In recent years, large language models have made tremendous strides in natural language question answering tasks. To take this progress to the next level, researchers have developed various question-answering style reasoning datasets to further assess and improve natural language reasoning. These datasets evaluate a range of reasoning skills, including common-sense reasoning, arithmetic reasoning, multi-modal reasoning, logical deduction, and tabular QA, among others. While there are many more, the figure below highlights some of the most commonly used benchmarks in the field. These benchmarks play a crucial role in advancing the research goal of complex natural language reasoning, pushing the boundaries of what is possible with language models and paving the way for even more sophisticated AI approaches.

Word Cloud of Natural Language Reasoning Datasets.
As large language models (LLMs) continue to excel in reasoning tasks and benchmarks, researchers are now exploring their potential to take on a more ambitious role; serving LLMs as agents that can orchestrate workflows and make decisions in complex domains that require planning. This emerging area of research holds tremendous promise, with potential applications spanning multiple fields. Imagine LLMs capable of autonomously managing business processes, planning a trip, or even managing and analyzing data to provide timely insights. However, despite the excitement surrounding this development, there is a significant gap in our understanding of LLMs' planning capabilities.
To this end, we introduce ACP Bench. A question-answering style dataset that evaluates AI-model's ability to reason about Action, Change, and Planning. To fully harness LLMs' potential for planning, ACPBench performs a more systematic evaluation of their strengths and limitations in tasks that are central to planning, indeed not being able to perform these tasks perfectly precludes the ability to formulate plans.
ACPBench consists of boolean and multi-choice questions of the following 7 reasoning tasks.
Action Applicability
Progression
Atom Reachability
Validation
Action Reachability
Justification
Landmarks
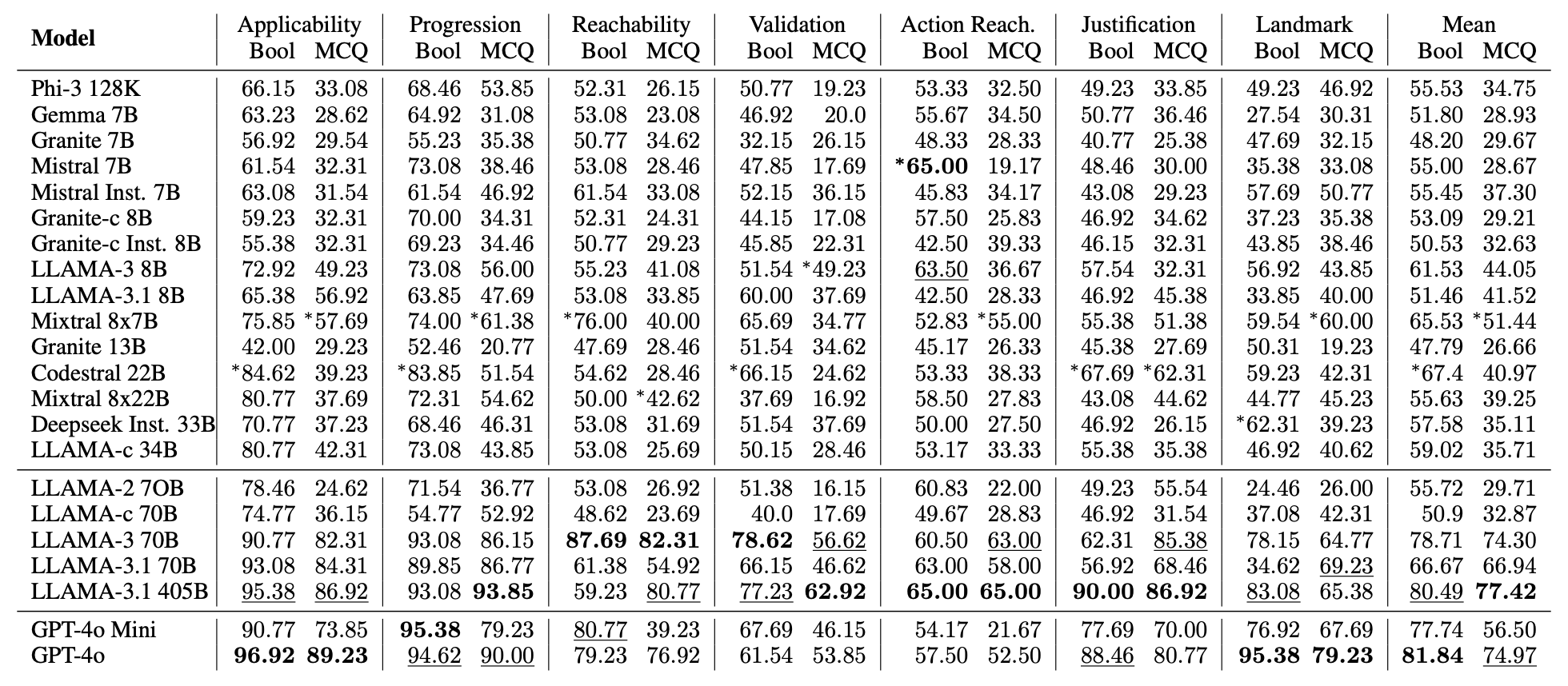
Accuracy of 22 leading LLMs on 7 ACPBench tasks (boolean as well as multi-choice questions). The best results are boldfaced, second best are underlined, and the best among the small, open-sourced models are highlighted with *. All models were evaluated with two in-context examples and Chain-of-Thought prompt. The right-most column is mean across tasks.
Upon evaluation of leading LLMs with COT-style prompting and two examples we found that LLAMA-3.1 405B and GPT-4o consistently outperform other models on these tasks, although they do not always achieve the top performance. When it comes to smaller open-sourced models, Codestral 22B stands out for its exceptional performance on boolean questions, while Mixtral 8x7B excels in handling multi-choice questions. However, both of them lag significantly behind GPT-4o, which is the best performer in these tasks. Action Reachability and Validation are the most challenging tasks for LLMs. Surprisingly, the GPT family models are not even among top-3 for the action reachablity task. cross all the tasks, GPT-4o performs best for boolean questions and LLAMA-3.1 405B performs best for multi-choice questions.
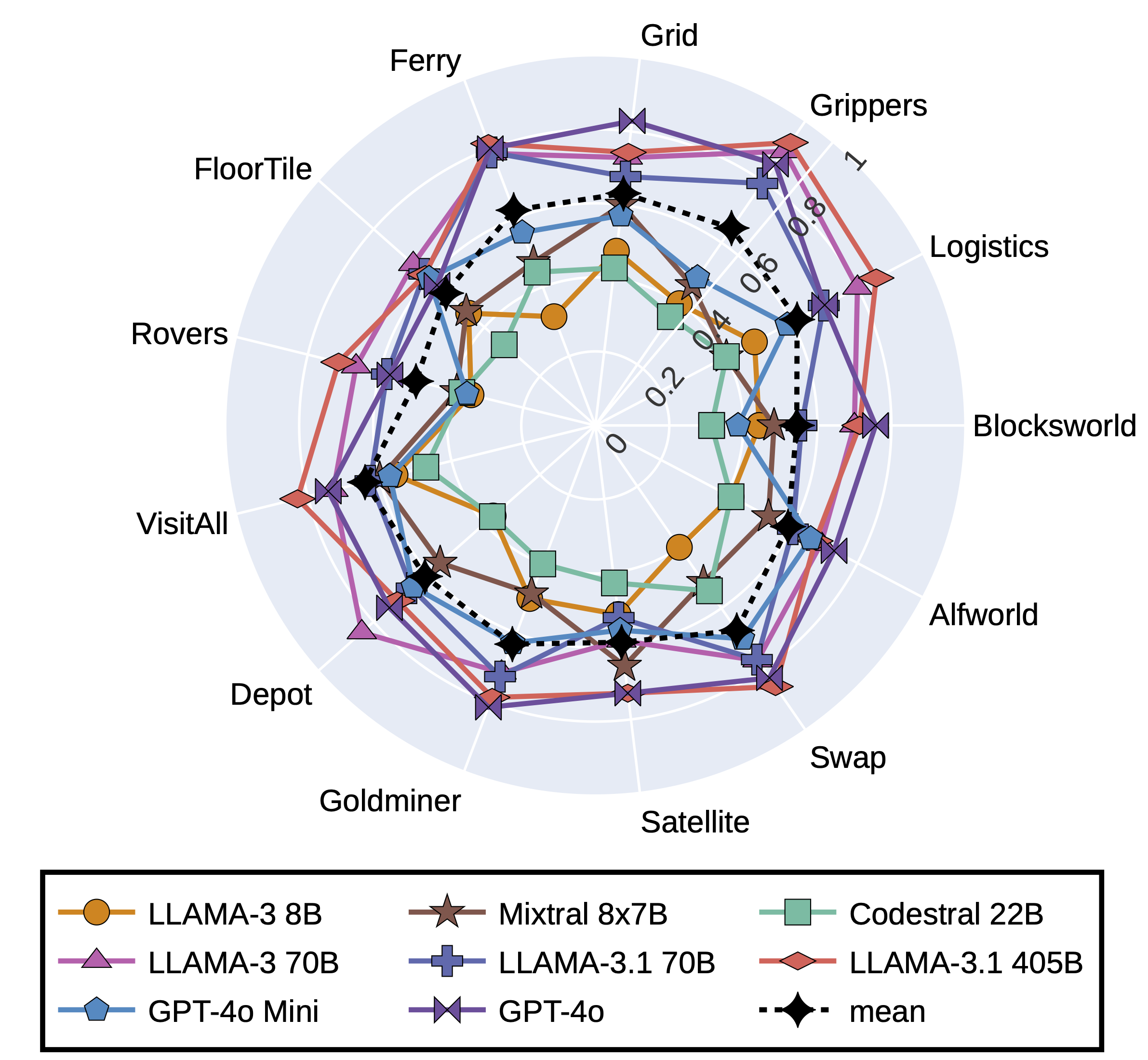
Comparison of 8 top performing LLMs on multi-choice questions in 13 domains of ACPBench. The mean of performance across the top-8 models is presented with dotted line in Black. The mean line indicates that none of the domains are exceptionally easy
A domain-wise analysis of the performance of LLMs on multi-choice questions. This analysis showcases the top 8 performing models. The average performance of these top-8 models is shown as the dotted line in black. This indicates that across models no specific domain seems too easy. However, Rovers, FloorTile, Blocksworld, Alfworld and Satellite domains pose the greatest challenges to LLMs, in that particular order.
Recently, OpenAI released a series of LLM-based reasoning models, o1, that shows significant boost over GPT-4o on benchmarks that require reasoning. A comparison of o1 with LLMs is not even-handed as o1 uses multiple interactions and generates much more tokens than the max-limit provided to LLMs (see sec 4.4 in the paper). So we do not include it in the LLMs' Performance Evaluation. Instead, we present the performance difference of OpenAI o1 models (with zeroshot IO and 2-shot COT prompts) from the best performing LLMs. Our results indicate that o1 models fail to yield performance gains for boolean questions, but demonstrate notable improvements on MCQs. Specifically, o1 preview consistently performs better or equal to the best performing model for MCQs.
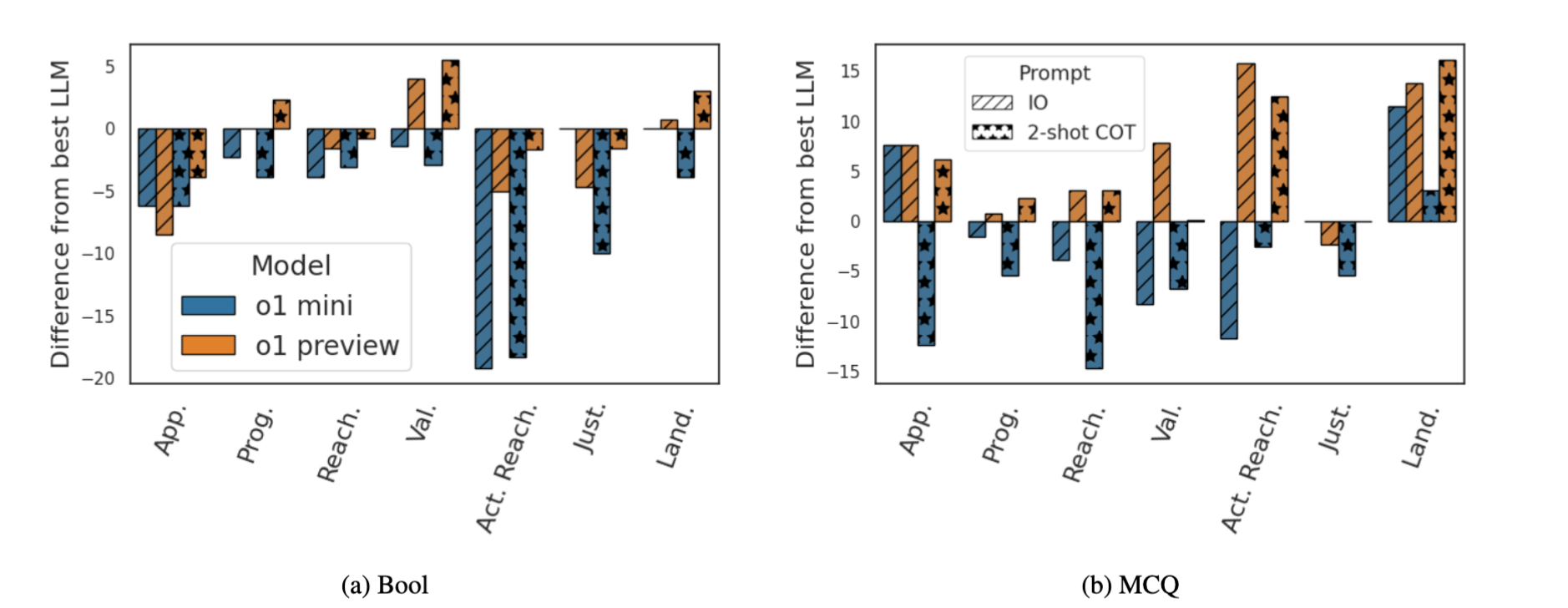
Comparing OpenAI o1 models with the best LLM. Positive difference shows o1 model performing better than the best of the LLMs. Negative difference is when o1 model lags behind the best LLM.
@inproceedings{kokel2024acp
author = {Harsha Kokel and
Michael Katz and
Kavitha Srinivas and
Shirin Sohrabi},
title = {ACPBench: Reasoning about Action, Change, and Planning},
booktitle = {{AAAI}},
publisher = {{AAAI} Press},
year = {2024}
}