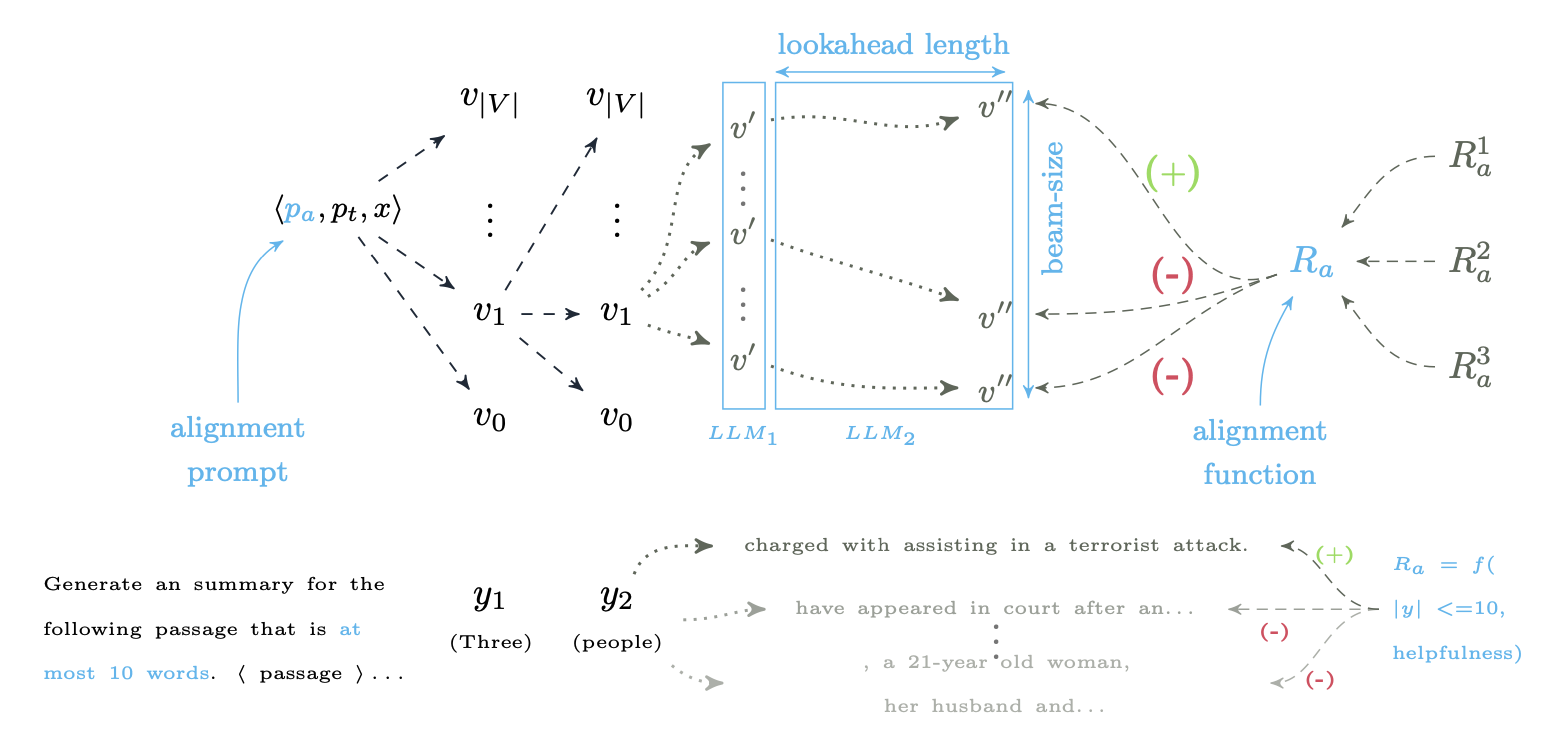
(Image from Huang et al., 2024)
DeAL¶
Paper: DeAL: Decoding-time Alignment for Large Language Models
Authors: James Huang, Sailik Sengupta, Daniele Bonadiman, Yi-an Lai, Arshit Gupta, Nikolaos Pappas, Saab Mansour, Katrin Kirchhoff, Dan Roth
DeAL (decoding-time alignment of LLMs) is a heuristic output steering method that uses an alignment or reward objective to guide model generation. It performs iterative generation of multiple beams, and at each step, selects the top-k partial beam outputs based on their alignment to the task objective, i.e., ranked by their scores using the reward function.
In this demo, we show how DeAL can be used to steer the output of LLMs to align with a given task alignment function.
Method Parameters¶
| parameter | type | description |
|---|---|---|
lookahead |
int |
How many tokens to generate in every partial beam |
init_beams |
int |
Number of starting beams |
topk |
int |
Number of top-scoring beams to select in each iteration |
max_iterations |
int |
Maximum number of iterations |
reward_func |
Callable |
Alignment or reward function. Takes inputs: • prompt: str• candidates: list[str]• params: dictReturns a list of scores for each candidate |
Setup¶
If running this from a Google Colab notebook, please uncomment the following cell to install the toolkit. The following block is not necessary if running this notebook from a virtual environment where the package has already been installed.
# !git clone https://github.com/IBM/AISteer360.git
# %cd AISteer360
The following authentication steps may be necessary to access any gated models (after being granted access by Hugging Face). Uncomment the following if you need to log in to the Hugging Face Hub:
# !pip install python-dotenv
# from dotenv import load_dotenv
# import os
# load_dotenv()
# token = os.getenv("HUGGINGFACE_TOKEN")
# from huggingface_hub import login
# login(token=token)
Example: Steering for keyword inclusion¶
from transformers import AutoModelForCausalLM, AutoTokenizer
from aisteer360.algorithms.output_control.deal.control import DeAL
from aisteer360.algorithms.core.steering_pipeline import SteeringPipeline
import warnings
warnings.filterwarnings('ignore', category=UserWarning)
MODEL_NAME = "Qwen/Qwen2.5-1.5B-Instruct"
/dccstor/principled_ai/users/erikmiehling/AISteer360/.venv/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
Define a prompt that asks the model to generate some text that contains a specific set of words.
prompt = "Write ONE coherent sentence describing an everyday scenario using all of the following words: cat, couch, sun"
print(prompt)
Write ONE coherent sentence describing an everyday scenario using all of the following words: cat, couch, sun
And here is the baseline model prediction.
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
chat = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(chat, return_tensors="pt").to(model.device)
baseline_outputs = model.generate(
**inputs,
do_sample=False,
max_new_tokens=50,
pad_token_id=tokenizer.eos_token_id
)
print("\nResponse (baseline):\n")
print(tokenizer.decode(baseline_outputs[0][len(inputs['input_ids'][0]):], skip_special_tokens=True))
The following generation flags are not valid and may be ignored: ['temperature', 'top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
Response (baseline): As the warm sunlight streamed through the window onto my favorite plush couch, I lazily stretched and settled in for a peaceful nap with my beloved feline companion curled up beside me.
Notice that the baseline prediction only has one of the three required words -- couch. It contains the words sunlight and feline which do not satisfy the given instruction.
Let us try to steer the model's output using DeAL. First, we need to implement the reward or alignment function. Note that DeAL's reward functions need to take as input:
| argument (type) | description |
|---|---|
prompt (str) |
The prompt string |
candidates (list[str]) |
List of partial beam candidates that need to be scored |
params (dict) |
Additional parameters that can be passed to DeAL using the runtime_kwargs |
The reward function must return the scores for each of the candidates as a list[float].
For our example, let us define a very simple function that scores each candidate beam based on the number of required words present. Hopefully, this results in an output that contains all the required words. Also, note that the design of this function is entirely up to the user.
import re
def keyword_overlap_reward(prompt: str, candidates: list[str], params: dict) -> list[float]:
"""
Reward function for this example. Note the fixed input and output function signatures.
The function rewards beams that have the most number of key_terms present.
It also penalizes beams that contain more than one sentence
"""
terms = [t.lower() for t in params["key_terms"]]
rewards = []
for text in candidates:
full_stops = text.count('.')
if full_stops > 1:
rewards.append(0)
else:
words = re.findall(r'\b\w+\b', text.lower())
reward = sum(words.count(term) for term in terms)
rewards.append(reward)
return rewards
We now define the DeAL control and the SteeringPipeline. We will use 16 beams to start with, each with a lookahead of 20.
At each iteration, let us retain the top 5 beams and perform at most 8 such iterations.
We also pass the reward function we defined above.
deal = DeAL(
lookahead=20,
init_beams=16,
topk=5,
max_iterations=8,
reward_func=keyword_overlap_reward
)
deal_pipeline = SteeringPipeline(
model_name_or_path=MODEL_NAME,
controls=[deal],
device_map="auto"
)
deal_pipeline.steer()
Now let us see the model output when DeAL is used to steer it. Note that since our reward function requires the variable key_terms to be defined in the params, we provide this as part of the runtime_kwargs.
output = deal_pipeline.generate(
input_ids=inputs['input_ids'],
runtime_kwargs={
'reward_params': {'key_terms': ["cat", "couch", "pet"]}
},
max_new_tokens=50,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
print("\nResponse (DeAL):\n")
print(tokenizer.decode(output[0], skip_special_tokens=True))
Response (DeAL): As the warm sun shone through the window, the fluffy cat curled up on the comfortable couch,
We see that DeAL does steer the model's output to produce all 3 required words -- cat, couch, sun, by using the reward function.