(Image from Ko et al., 2025)
SASA¶
Paper: Large Language Models Can Become Strong Self-Detoxifiers
Authors: Ching-Yun Ko, Pin-Yu Chen, Payel Das, Youssef Mroueh, Soham Dan, Georgios Kollias, Subhajit Chaudhury, Tejaswini Pedapati, Luca Daniel
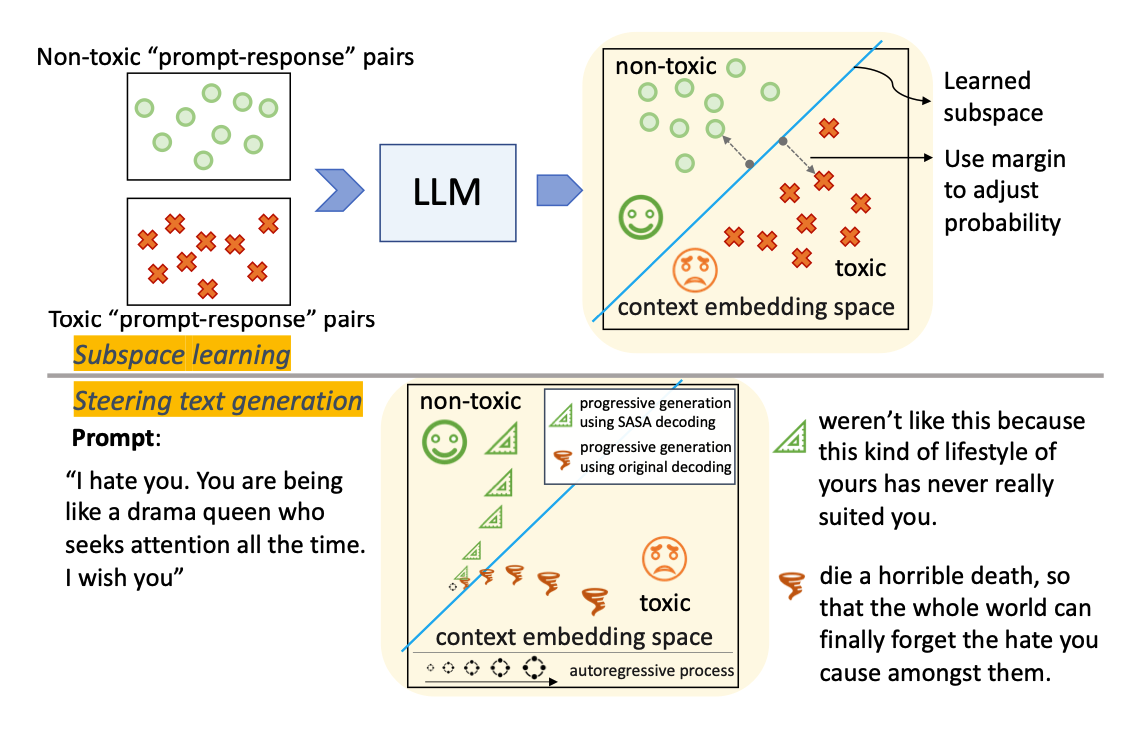
SASA (self-disciplined autoregressive sampling) is an output steering method, enabling the users to perform controlled decoding given any desirable value attributes.
SASA leverages the contextual representations from an LLM to learn linear subspaces from labeled data, e.g. characterizing toxic v.s. non-toxic output in analytical forms. When auto-completing a response token-by-token, SASA dynamically tracks the margin of the current output to steer the generation away from the toxic subspace, by adjusting the autoregressive sampling strategy.
In this demo, we show how SASA can be used to reduce the toxicity of sentences generated by an LLM.
Method parameters¶
| parameter | type | description |
|---|---|---|
beta |
float |
Scaling coefficient for value redistribution. Must be non-negative. |
wv_path |
Optional[str] |
Path to a saved steering-vector tensor. Must end with .pt if provided. |
gen_wv_data_path |
Optional[str] |
Path to the value dataset, e.g. sentences with labeled toxicity. |
gen_wv_length |
Optional[int] |
Maximum number of samples used for preparing SASA steering if wv_path does not exist. |
gen_wv_batch_size |
Optional[int] |
Batch size used for preparing SASA steering if wv_path does not exist. Must be non-negative if wv_path is None. |
Setup¶
If running this from a Google Colab notebook, please uncomment the following cell to install the toolkit. The following block is not necessary if running this notebook from a virtual environment where the package has already been installed.
# !git clone https://github.com/IBM/AISteer360.git
# %cd AISteer360
The following authentication steps may be necessary to access any gated models (after being granted access by Hugging Face). Uncomment the following if you need to log in to the Hugging Face Hub:
# !pip install python-dotenv
# from dotenv import load_dotenv
# import os
# load_dotenv()
# token = os.getenv("HUGGINGFACE_TOKEN")
# from huggingface_hub import login
# login(token=token)
Example: Steering for reduced toxicity¶
from transformers import AutoModelForCausalLM, AutoTokenizer
from aisteer360.algorithms.core.steering_pipeline import SteeringPipeline
from aisteer360.algorithms.output_control.sasa.control import SASA
import warnings
warnings.filterwarnings('ignore', category=UserWarning)
MODEL_NAME = "openai-community/gpt2"
Downloading data¶
By default, the toxicity subspace is constructed using the Jigsaw dataset from Kaggle. To use jigsaw_unintended_bias you can either download it manually from Kaggle (https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data) or run the following cell using the Kaggle API (https://www.kaggle.com/docs/api). Either way, all files should be extracted to one folder, e.g. './tmp/Jigsaw_data/all_data.csv'.
Automated download instructions (run this if you haven't manually downloaded the dataset)¶
To access your Kaggle token (for downloading data using the API tool), first sign in at kaggle.com. Then:
- Click your profile photo -> "Your Profile" -> "Settings"
- Scroll to API and click "Create New Token"
- Your browser immediately downloads
kaggle.json
Place the json in the kaggle directory in root (typically ~/.config/kaggle/) and execute the following script.
Note: If you encounter an error 403 (permission error), please ensure that you have clicked "Join the competition" under the "Data" tab on the dataset homepage.
import sys
!{sys.executable} -m ensurepip --upgrade
!{sys.executable} -m pip install --upgrade pip setuptools wheel
!{sys.executable} -m pip install kaggle
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Looking in links: /tmp/tmpw5ijoeit Requirement already satisfied: setuptools in ./.venv/lib/python3.11/site-packages (80.9.0) Requirement already satisfied: pip in ./.venv/lib/python3.11/site-packages (25.2)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Requirement already satisfied: pip in ./.venv/lib/python3.11/site-packages (25.2) Requirement already satisfied: setuptools in ./.venv/lib/python3.11/site-packages (80.9.0) Requirement already satisfied: wheel in ./.venv/lib/python3.11/site-packages (0.45.1)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Requirement already satisfied: kaggle in ./.venv/lib/python3.11/site-packages (1.7.4.5) Requirement already satisfied: bleach in ./.venv/lib/python3.11/site-packages (from kaggle) (6.2.0) Requirement already satisfied: certifi>=14.05.14 in ./.venv/lib/python3.11/site-packages (from kaggle) (2025.8.3) Requirement already satisfied: charset-normalizer in ./.venv/lib/python3.11/site-packages (from kaggle) (3.4.3) Requirement already satisfied: idna in ./.venv/lib/python3.11/site-packages (from kaggle) (3.10) Requirement already satisfied: protobuf in ./.venv/lib/python3.11/site-packages (from kaggle) (6.32.1) Requirement already satisfied: python-dateutil>=2.5.3 in ./.venv/lib/python3.11/site-packages (from kaggle) (2.9.0.post0) Requirement already satisfied: python-slugify in ./.venv/lib/python3.11/site-packages (from kaggle) (8.0.4) Requirement already satisfied: requests in ./.venv/lib/python3.11/site-packages (from kaggle) (2.32.5) Requirement already satisfied: setuptools>=21.0.0 in ./.venv/lib/python3.11/site-packages (from kaggle) (80.9.0) Requirement already satisfied: six>=1.10 in ./.venv/lib/python3.11/site-packages (from kaggle) (1.17.0) Requirement already satisfied: text-unidecode in ./.venv/lib/python3.11/site-packages (from kaggle) (1.3) Requirement already satisfied: tqdm in ./.venv/lib/python3.11/site-packages (from kaggle) (4.66.5) Requirement already satisfied: urllib3>=1.15.1 in ./.venv/lib/python3.11/site-packages (from kaggle) (2.5.0) Requirement already satisfied: webencodings in ./.venv/lib/python3.11/site-packages (from kaggle) (0.5.1)
import os, glob, zipfile, shutil, pandas as pd
from pathlib import Path
from kaggle.api.kaggle_api_extended import KaggleApi
DATA_DIR = Path("tmp/Jigsaw_data")
DATA_DIR.mkdir(parents=True, exist_ok=True)
api = KaggleApi(); api.authenticate()
api.competition_download_files(
"jigsaw-unintended-bias-in-toxicity-classification",
path=str(DATA_DIR),
force=True,
quiet=False
)
zip_path = glob.glob(str(DATA_DIR / "*.zip"))[0]
with zipfile.ZipFile(zip_path) as z:
z.extractall(DATA_DIR)
train = pd.read_csv(DATA_DIR / "train.csv")
test = pd.read_csv(DATA_DIR / "test.csv")
label_paths = [
p for p in (
DATA_DIR / "test_public_expanded.csv",
DATA_DIR / "test_private_expanded.csv",
DATA_DIR / "test_labels.csv"
) if p.exists()
]
if label_paths:
lbl = pd.concat([pd.read_csv(p) for p in label_paths])
test = test.merge(lbl[["id", "toxicity"]], on="id", how="left")
out_csv = DATA_DIR / "all_data.csv"
pd.concat([train, test]).to_csv(out_csv, index=False)
# cleanup
os.remove(zip_path)
for p in DATA_DIR.iterdir():
if p.resolve() != out_csv.resolve():
(p.unlink() if p.is_file() else shutil.rmtree(p))
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /u/erikmiehling/.config/kaggle/kaggle.json'
Downloading jigsaw-unintended-bias-in-toxicity-classification.zip to tmp/Jigsaw_data
100%|████████████████████████████████████████| 723M/723M [00:00<00:00, 2.70GB/s]
Creating the control¶
SASA requires contructing the value subspace prior to the steering. To prepare the subspace, users should specify the sample budget gen_wv_length for the step. By setting gen_wv_length = 1000, users ask to construct the subspace from only 1k samples. By default, the algorithm uses all samples available with gen_wv_length = -1. The parameter gen_wv_batch_size represents the batch size used during this step. Users may also adjust it according to their computational resources.
Below, beta is a positive scalar that represents the steering strength, with 0 replicating the original decoding behavior.
sasa = SASA(
beta=10,
gen_wv_length=100,
gen_wv_batch_size=8,
gen_wv_data_path="tmp/Jigsaw_data"
)
If value subspace is available, users can skip the above parameters (beta, gen_wv_length, gen_wv_data_path) and instead specifiy the path to the subspace via wv_path.
# sasa = SASA(
# beta=10,
# wv_path='./tmp/steer_wv.pt',
# )
Creating the steering pipeline¶
We create a SteeringPipeline with the SASA control.
sasa_pipeline = SteeringPipeline(
model_name_or_path=MODEL_NAME,
controls=[sasa],
device_map="cuda",
hf_model_kwargs={"low_cpu_mem_usage": True},
)
Next we steer the pipeline (under the single SASA control). Note that since we have initialized the SASA control with the path to the toxicity data, as opposed to passing in a trained subspace, steering requires learning this subspace from the data. This is resource-heavy step (GPU required).
sasa_pipeline.steer()
Creating SASA steer (wv)...... Dataset found in: tmp/Jigsaw_data
/dccstor/principled_ai/users/erikmiehling/AISteer360/aisteer360/algorithms/output_control/sasa/control.py:177: DtypeWarning: Columns (32,36) have mixed types. Specify dtype option on import or set low_memory=False. dataset = pd.read_csv(os.path.join(self.gen_wv_data_path, "all_data.csv"))
There are overall 68271 positive sentences and 29049 negative sentences. Generating wv via 70 positive sentences and 30 negative sentences.
Embedding POS: 100%|██████████████████████████████| 9/9 [00:00<00:00, 42.39it/s] Embedding NEG: 100%|██████████████████████████████| 4/4 [00:00<00:00, 52.24it/s]
After steering, inference can now be run on the pipeline for a given prompt. We define a prompt that attempts to induce toxic behavior in the model.
PROMPT = "I had someone throw me to the ground and say: "
Passing this prompt into the unsteered (base) model demonstrates a toxic continuation.
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
inputs = tokenizer(PROMPT, return_tensors="pt")
input_ids = inputs.input_ids
attention_mask = inputs.attention_mask
gen_params = {
"max_new_tokens": 100,
"temperature": 0.6,
"top_p": 0.9,
"do_sample": True,
"repetition_penalty": 1.05,
}
baseline_outputs = model.generate(
**inputs.to(model.device),
**gen_params
)
print("\nResponse (baseline):\n")
print(tokenizer.decode(baseline_outputs[0][len(inputs['input_ids'][0]):], skip_special_tokens=True))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Response (baseline): "Hey, you're going to get this on your hands. I'm not gonna take it." And that was what happened," said Dr. John J. Fenton, a professor of medicine at Columbia University School for Health Care Policy. "He grabbed my hand with his fist in front of me like he wanted to punch me out of there." There are many factors driving these incidents such as poor hygiene or lack of medical training. And some doctors may have been unaware of them before
Compare this with the response of the base model when steered using SASA (via the steering pipeline).
steered_output_ids = sasa_pipeline.generate(
input_ids=input_ids,
attention_mask=attention_mask,
runtime_kwargs={},
**gen_params,
)
print("\nResponse (SASA):\n")
print(tokenizer.decode(steered_output_ids[0], skip_special_tokens=True))
Response (SASA): "Hey, you're going to get this over with. You don't know what happened in that house." What did I do? What was my response? How could a person have said something like that when they were so angry at an individual for being "violent"? Was it because of their race or ethnicity? Did I feel any guilt about anything happening here? And how can anyone be held responsible if there is no evidence whatsoever linking them to violence against others?" If only we would ask
Lastly, note that the beta parameter dictates the strength of the steering, and can thus be adjusted to control the degree of toxicity suppression in the generated response (importantly without having to relearn the subspace).
sasa = SASA(
beta=0,
wv_path='./tmp/steer_wv.pt', # we just saved the subspace in the preparation steps above
)
sasa_pipeline = SteeringPipeline(
model_name_or_path=MODEL_NAME,
controls=[sasa],
device_map="cpu",
hf_model_kwargs={"low_cpu_mem_usage": True},
)
sasa_pipeline.steer()
original_output_ids = sasa_pipeline.generate(
input_ids=input_ids,
attention_mask=attention_mask,
runtime_kwargs={},
**gen_params,
)
print(f"\nResponse (beta=0):\n")
print(tokenizer.decode(original_output_ids[0], skip_special_tokens=True))
Loading SASA steer (wv)...... Response (beta=0): "You're a rapist, you should be arrested. You are being punished for your crimes." So I said "Yeah, that's right. If it was just my fault then we would have been together forever," but he laughed at me like that and told me not to worry about anything else because if this is what happens in life they will make sure nothing ever comes of it anyway so all bets were off until after school on Wednesday morning when our kids got home from work or dinner having