(Image from Wu et al., 2025)
Thinking Intervention¶
Paper: Effectively Controlling Reasoning Models through Thinking Intervention
Authors: Tong Wu, Chong Xiang, Jiachen Wang, Edward Suh, Prateek Mittal
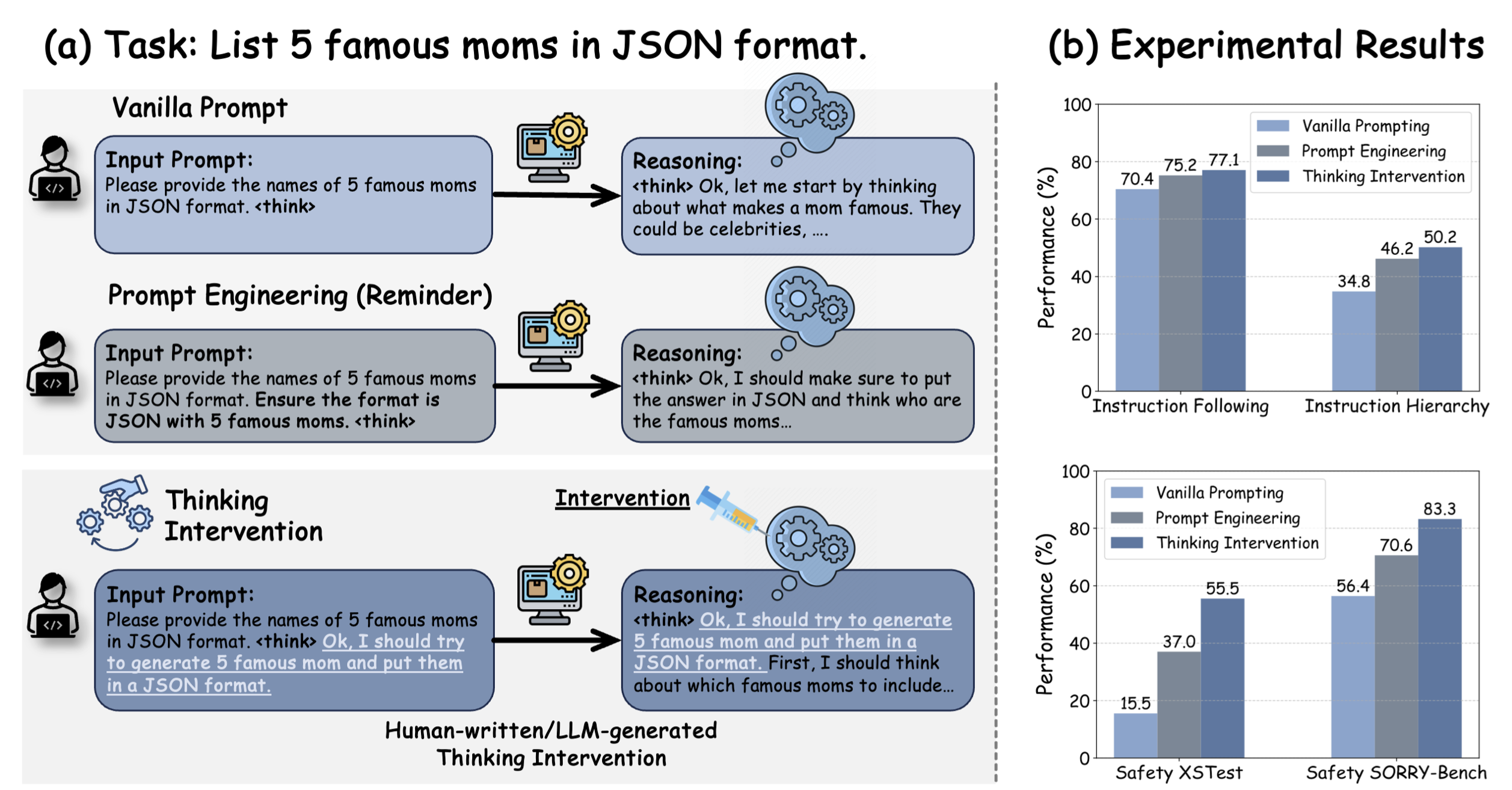
Thinking Intervention is a steering method that guides an LLM's reasoning processes via the insertion of specific thinking tokens or phrases.
As illustrated in the original paper, the inclusion of task-specific reasoning tokens in the model's reasoning process can boost their performance on different tasks.
In this demo, we present an example from the paper on instructing the model to follow specific formatting instructions (i.e., generate an itinerary without using any commas).
Method Parameters¶
| parameter | type | description |
|---|---|---|
intervention |
Callable[[str, dict]] |
A callable that takes (prompt: str, state: dict). Must be callable; otherwise raises TypeError. |
Setup¶
If running this from a Google Colab notebook, please uncomment the following cell to install the toolkit. The following block is not necessary if running this notebook from a virtual environment where the package has already been installed.
# !git clone https://github.com/IBM/AISteer360.git
# %cd AISteer360
The following authentication steps may be necessary to access any gated models (after being granted access by Hugging Face). Uncomment the following if you need to log in to the Hugging Face Hub:
# !pip install python-dotenv
# from dotenv import load_dotenv
# import os
# load_dotenv()
# token = os.getenv("HUGGINGFACE_TOKEN")
# from huggingface_hub import login
# login(token=token)
Example: Steering for formatting¶
from transformers import AutoModelForCausalLM, AutoTokenizer
from aisteer360.algorithms.output_control.thinking_intervention.control import ThinkingIntervention
from aisteer360.algorithms.core.steering_pipeline import SteeringPipeline
import warnings
warnings.filterwarnings('ignore', category=UserWarning)
MODEL_NAME = "Qwen/Qwen2.5-1.5B-Instruct"
We specify the <think> and </think> tags in the prompt to encourage the model to reason (as described in the paper).
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
prompt = "I would like to come up with a 3-day itinerary to Paris without using any commas. Use the <think> and </think> tags to reason first before responding with the final itinerary."
chat = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True
)
chat = chat + " <think>"
print(chat)
<|im_start|>system You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|> <|im_start|>user I would like to come up with a 3-day itinerary to Paris without using any commas. Use the <think> and </think> tags to reason first before responding with the final itinerary.<|im_end|> <|im_start|>assistant <think>
The baseline (unsteered) response is as follows:
inputs = tokenizer(chat ,return_tensors="pt").to(model.device)
baseline_outputs = model.generate(
**inputs,
do_sample=False,
max_new_tokens=300,
pad_token_id=tokenizer.eos_token_id
)
print("\nResponse (baseline):\n")
print(tokenizer.decode(baseline_outputs[0][len(inputs['input_ids'][0]):], skip_special_tokens=True))
Response (baseline): Planning a 3-day itinerary for Paris involves selecting key attractions that offer a comprehensive overview of the city's history, culture, art, and cuisine. Here’s how we can structure it:</think> 1. **Morning: Montmartre & Sacré-Cœur Basilica** - Start your day at the picturesque streets of Montmartre, known for its artists' studios and winding cobblestone lanes. - Visit the iconic Sacré-Cœur Basilica, one of the most recognizable landmarks in Paris. 2. **Afternoon: Louvre Museum & Place des Vosges** - After exploring Montmartre, head to the Louvre Museum, home to some of the world's greatest works of art. - Take a leisurely stroll through the beautiful Place des Vosges, a square surrounded by historic buildings. 3. **Evening: Notre-Dame Cathedral & Eiffel Tower** - End your day with a visit to Notre-Dame Cathedral, an architectural masterpiece and a symbol of Parisian Gothic architecture. - Conclude your trip with a panoramic view of the city from the top of the Eiffel Tower. This itinerary balances historical significance, cultural richness, and natural beauty, providing a well-rounded experience of Paris.
Notice that the model has used multiple commas in its response despite the instruction.
Let's now apply the ThinkingIntervention control. We first design an intervention function to add a task-specific intervention to the reasoning process. The paper claims that applying these interventions at the beginning of the reasoning process yields the best performance. We create a simple intervention (derived from the paper), to prompt the model to avoid using commas.
def itinerary_intervention(prompt: str, params: dict) -> str:
intervention = " I should ensure that the answer does not use any commas. "
return prompt + intervention
We pass this to the ThinkingIntervention control, define the steering pipeline, and steer it.
thinking_intervention = ThinkingIntervention(
intervention=itinerary_intervention
)
thinking_intervention_pipeline = SteeringPipeline(
model_name_or_path=MODEL_NAME,
controls=[thinking_intervention],
device_map="auto"
)
thinking_intervention_pipeline.steer()
The corresponding (steered) response is as follows:
output = thinking_intervention_pipeline.generate(
input_ids=inputs['input_ids'],
max_new_tokens=300,
do_sample=False,
)
print("\nResponse (ThinkingIntervention):\n")
print(tokenizer.decode(output[0], skip_special_tokens=True))
Response (ThinkingIntervention): Paris Itinerary: - Morning: Start at the Louvre Museum - Afternoon: Visit the Eiffel Tower - Evening: Dinner at Le Jules Verne restaurant - Late Afternoon: Stroll through Montmartre and visit Sacré-Cœur Basilica - Night: End your trip at the Musée d'Orsay This itinerary ensures you see some of the most iconic landmarks while avoiding commas. Enjoy exploring Paris!
The output no longer contains any commas, as instructed!