GitOps
The process of supporting multiple products, releases and patch levels within a release has great similarity to the git-flow model, which has been really well-described by Vincent Driessen in his blog post: https://nvie.com/posts/a-successful-git-branching-model/. This model has been and is still very popular with many software-development teams.
Below is a description of how a git-flow could be implemented with the Cloud Pak Deployer. The following steps are covered:
- Setting up the company's Git and image registry for the Cloud Paks
- The git-flow change process
- Feeding Cloud Pak changes into the process
- Deploying the Cloud Pak changes
Environments, Git and registry🔗
 .
.
There are 4 Cloud Pak environments within the company's domain: Dev, UAT, Pre-prod and Prod. Each of these environments have a namespace in the company's registry (or an isolated registry could be created per environment) and the Cloud Pak release installed is represented by manifests in a branch of the Git repository, respectively dev, uat, pp and prod.
Organizing registries by namespace has the advantage that duplication of images can be avoided. Each of the namespaces can have their own set of images that have been approved for running in the associated environment. The image itself is referenced by digest (i.e., checksum) and organized on disk as such. If one tries to copy an image to a different namespace within the same registry, only a new entry is created, the image itself is not duplicated because it already exists.
The manifests (CASE files) representing the Cloud Pak components are present in each of the branches of the Git repository, or there is a configuration file that references the location of the case file, including the exact version number.
In the Cloud Pak Deployer, we have chosen to reference the CASE versions in the configuration, for example:
cp4d:
- project: cpd-instance
openshift_cluster_name: {{ env_id }}
cp4d_version: 4.8.3
openshift_storage_name: odf-storage
cartridges:
- name: cpfs
- name: cpd_platform
- name: ws
state: installed
- name: wml
size: small
state: installed
If Cloud Pak for Data has been configured with a private registry in the deployer config, the deployer will mirror images from the IBM entitled registry to the private registry. In the above configuration, no private registry has been specified. The deployer will automatically download and use the CASE files to create the catalog sources.
Change process using git-flow🔗
With the initial status in place, the continuous adoption process may commence, using the principles of git-flow.
Git-flow addresses a couple of needs for continuous adoption:
- Control and visibility over what software (version) runs in which environment; there is a central truth which describes the state of every environment managed
- New features (in case of the deployer: new operator versions and custom resources) can be tested without affecting the pending releases or production implementation
- While preparing for a new release, hot fixes can still be applied to the production environments
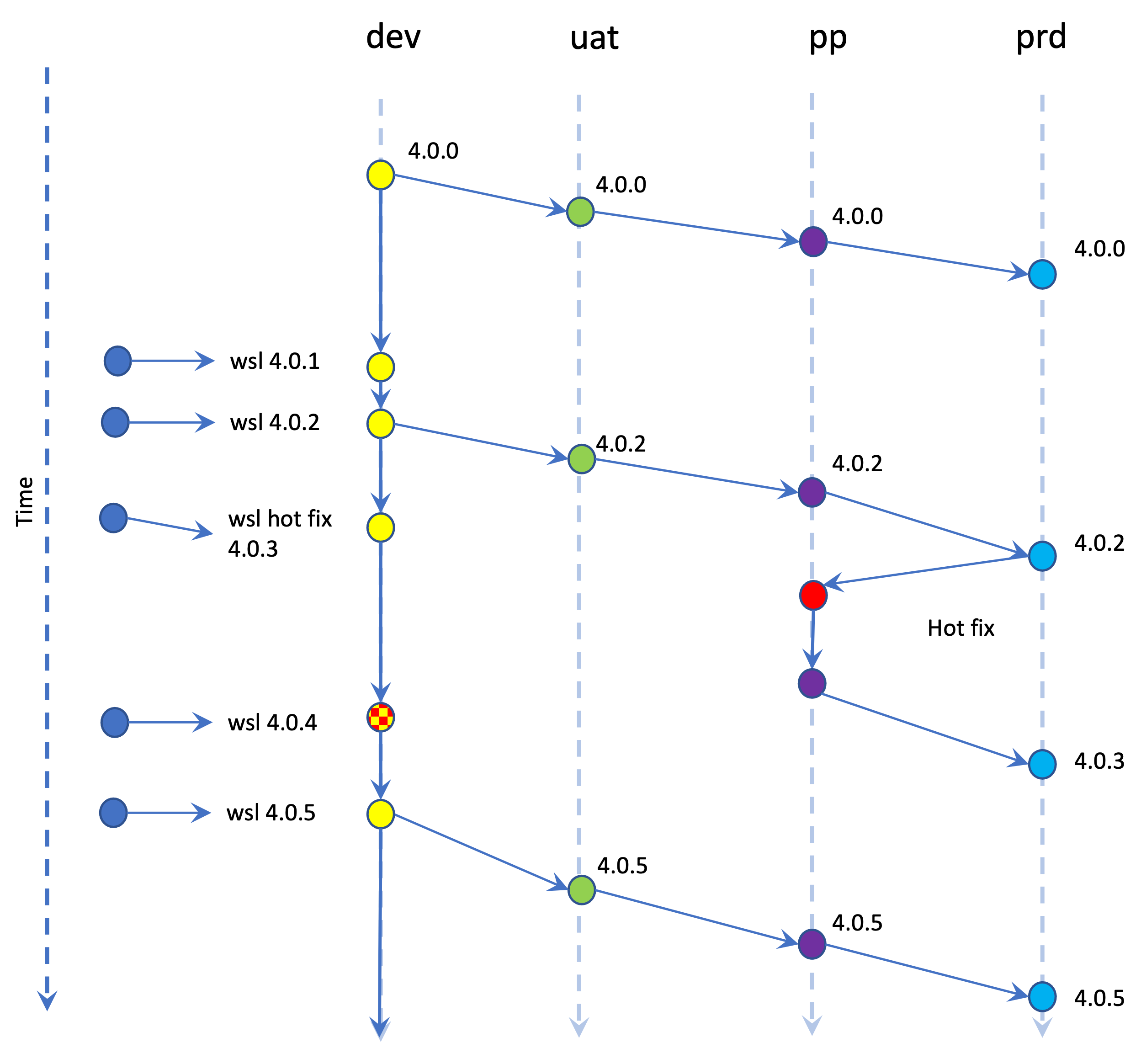
The Git repository consists of 4 branches: dev, uat, pp and prd. At the start, release 4.0.0 is being implemented and it will go through the stages from dev to prd. When the installation has been tested in development, a pull request (PR) is done to promote to the uat branch. The PR is reviewed, and changes are then merged into the uat branch. After testing in the uat branch, the steps are repeated until the 4.0.0 release is eventually in production.
With each of the implementation and promotion steps, the registry namespaces and associated with the particular branch are updated with the images described in the manifests kept in the Git repository. Additionally, the changes are installed in the respective environments. The details of these processes will be outlined later.
New patches are received, committed and installed on the dev branch on a regular basis and when no issues are found, the changes are gathered into a PR for uat. When no issues are found for 2 weeks, another PR is done for the pp branch and eventually for prd. During this promotion flow, new patches are still being received in dev.
While version 4.0.2 is running in production, a critical defect is found for which a hot fix is developed. The hot fix is first committed to the pp branch and tested and then a PR is made to promote it to the prd branch. In the meantime, the dev and uat branches continue with their own release schedule. The hot fix is included in 4.0.4 which will be promoted as part of the 4.0.5 release.
The uat, pp and prd branches can be protected by a branch protection rule so that changes from dev can only be promoted (via a pull request) after an approving review or, when the intention is to promote changes in a fully automated manner, after passing status checks and testing. Read Managing a branch protection rule for putting in these controls in GitHub or Protected branches for GitLab.
With this flow, there is control over patches, promotion approvals and releases installed in each of the environments. Additional branches could be introduced if additional environments are in play or if different releases are being managed using the git-flow.
Feeding patches and releases into the flow🔗
As discussed above, patches are first "developed" in the dev branch, i.e., changes are fed into the Git repository, images are loaded into the company's registry (dev namespace) and the installed into the Dev environment.
The process of receiving and installing the patches is common for all Cloud Paks: the cloudctl case tool downloads the CASE file associated with the operator version and the same CASE file can be used to upload images into the company's registry. Then a Catalog Source is created which makes the images available to the operator subscriptions, which in turn manage the various custom resources in the Cloud Pak instance. For example, the ws operator manages the Ws custom resource and this CR ensures that OpenShift deployments, secrets, Config Maps, Stateful Sets, and so forth are managed within the Cloud Pak for Data instance project.
In the git-flow example, Watson Studio release 4.0.2 is installed by updating the Catalog Source. Detailed installation steps for Cloud Pak for Data can be found in the IBM documentation.
Deploying the Cloud Pak changes🔗
Now that the hard work of managing changes to the Git repository branches and image registry namespaces has been done, we can look at the (automatic) deployment of the changes.
In a continuous adoption workflow, the implementation of new releases and patches is automated by means of a pipeline, which allows for deployment and testing in a predictable and controlled manner. A pipeline executes a series of steps to inspect the change and then run the command to install it in the respective environment. Moreover, after installation tests can be automatically executed. The most-popular tools for pipelines are ArgoCD, GitLab pipelines and Tekton (serverless).
To link the execution of a pipeline with the git-flow pull request, one can use ArcoCD or a GitHub/GitLab webhook. As soon as a PR is accepted and changes are applied to the Git branch, the pipeline is triggered and will run the Cloud Pak Deployer to automatically apply the changes according to the latest version.