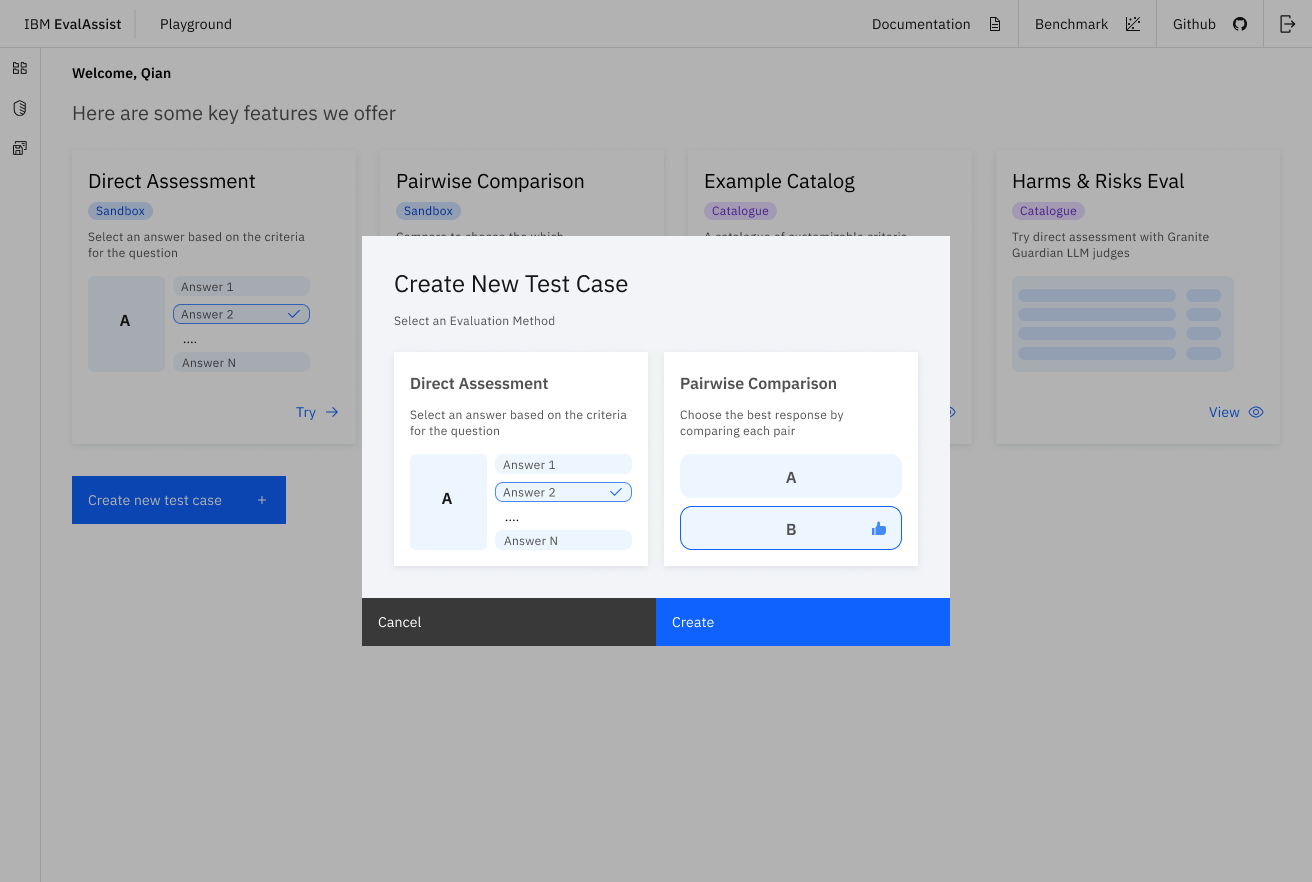
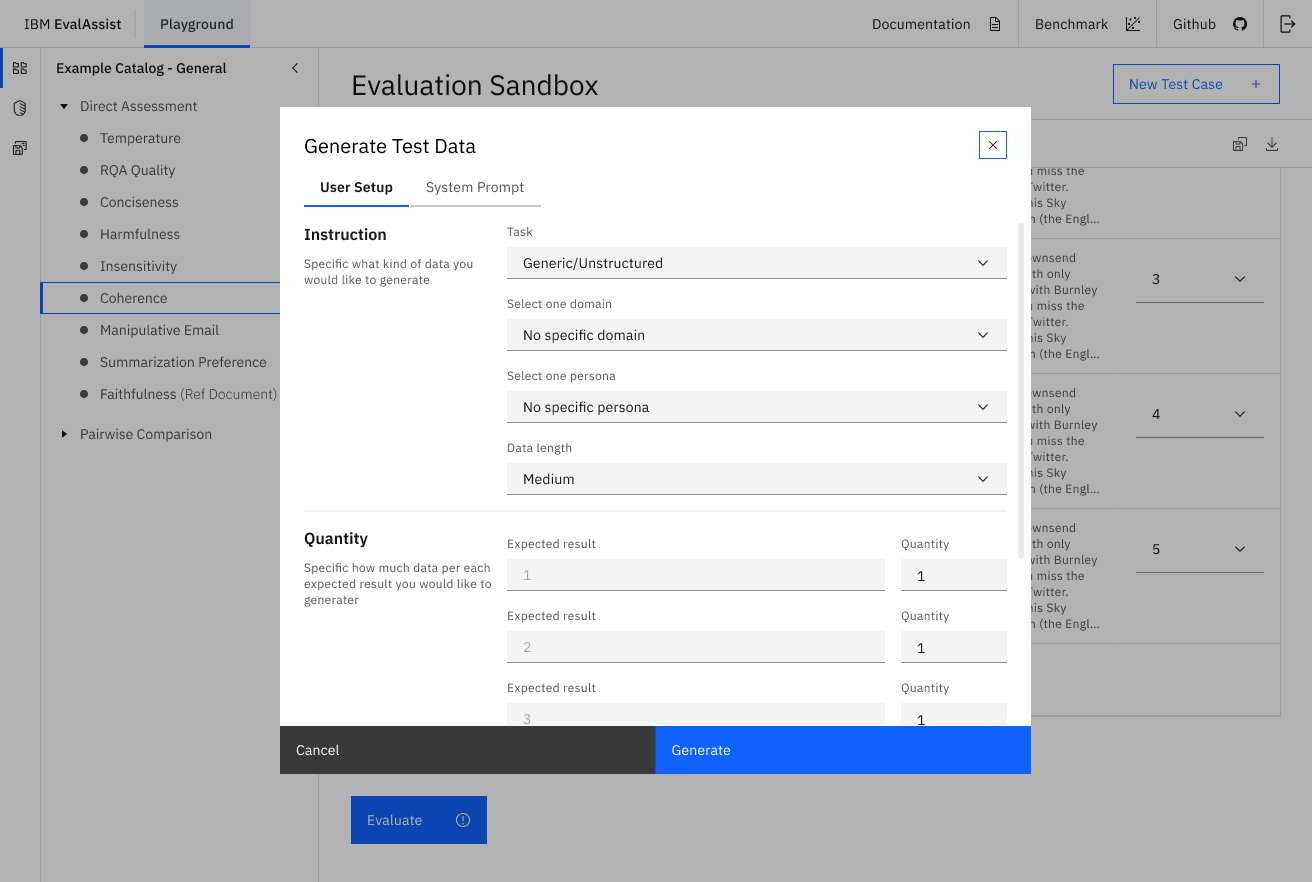
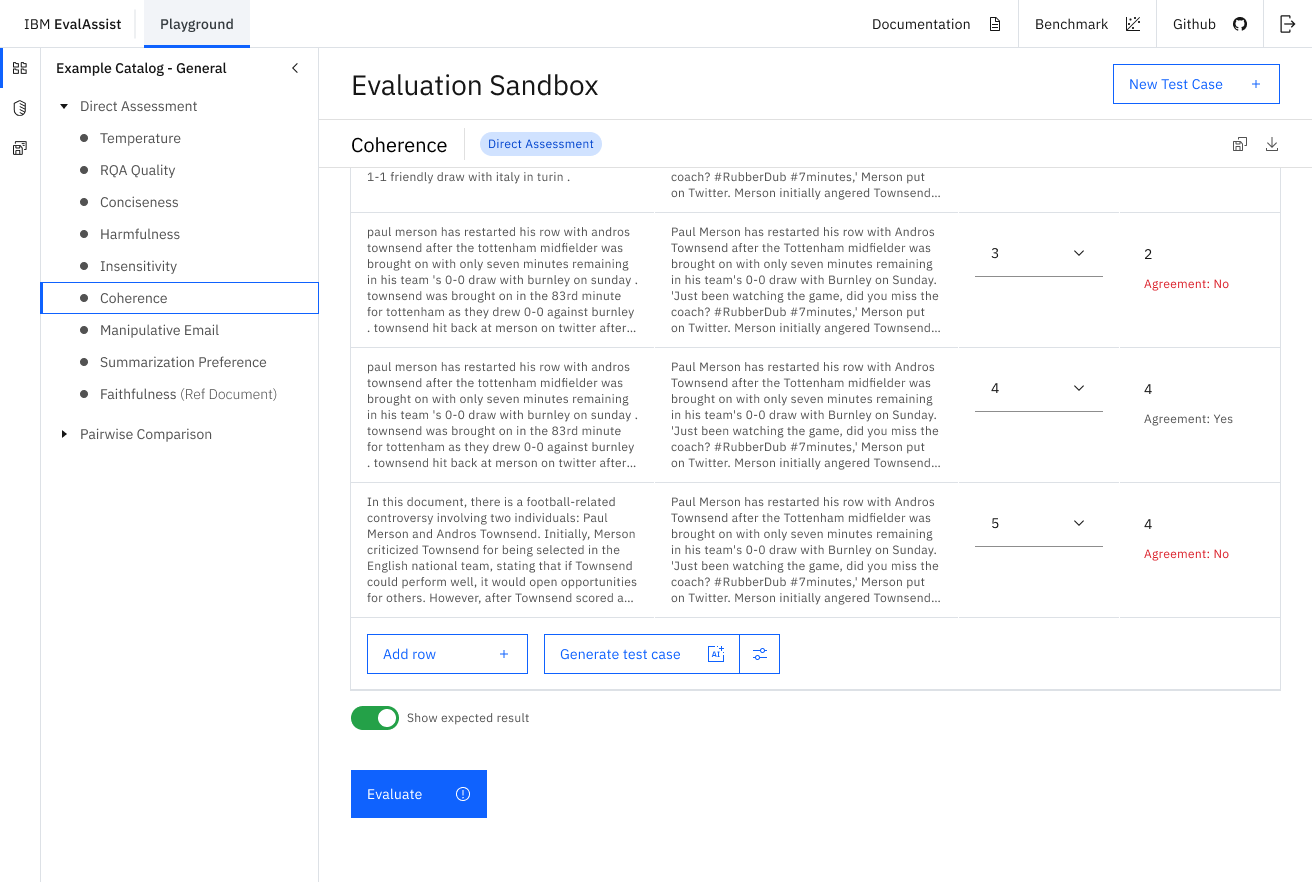
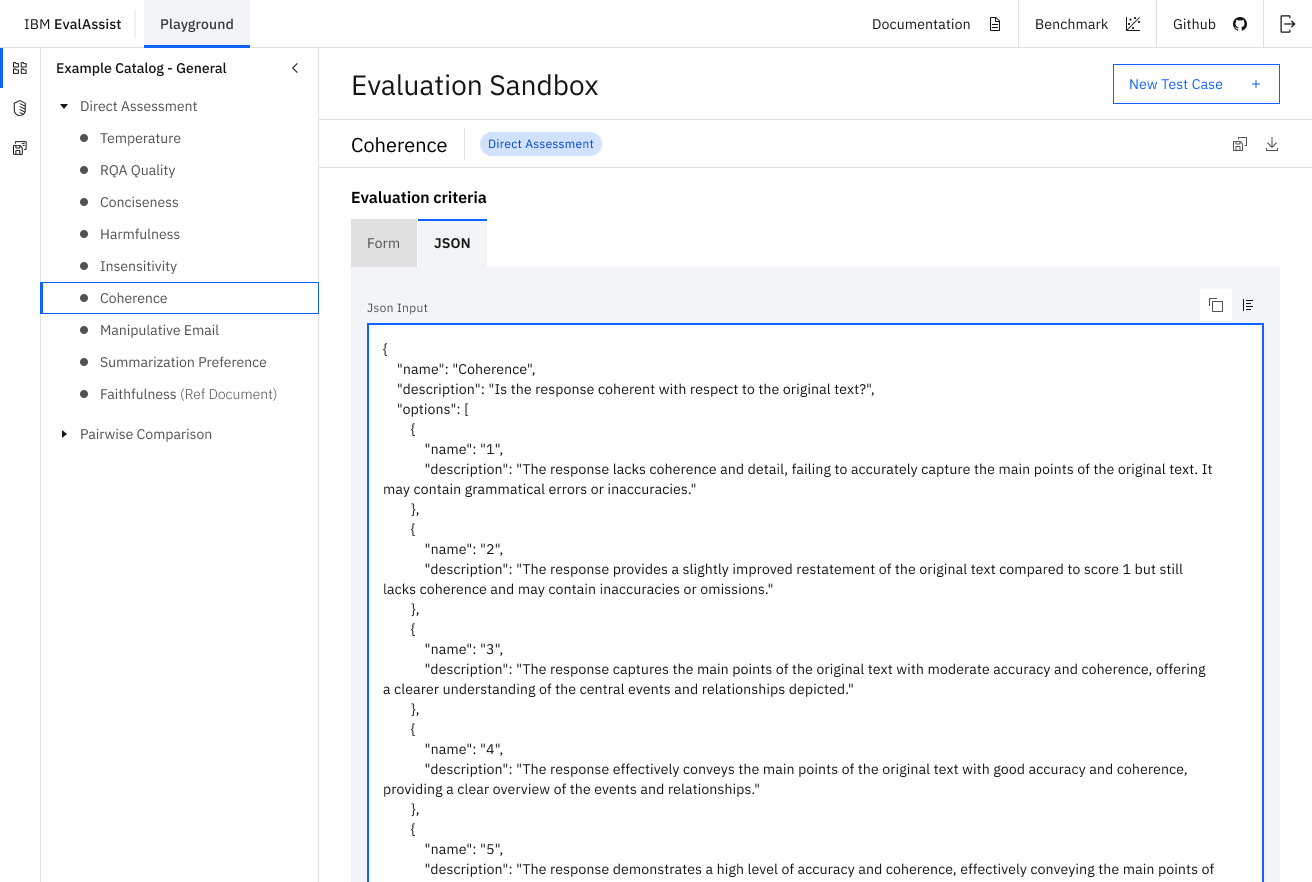
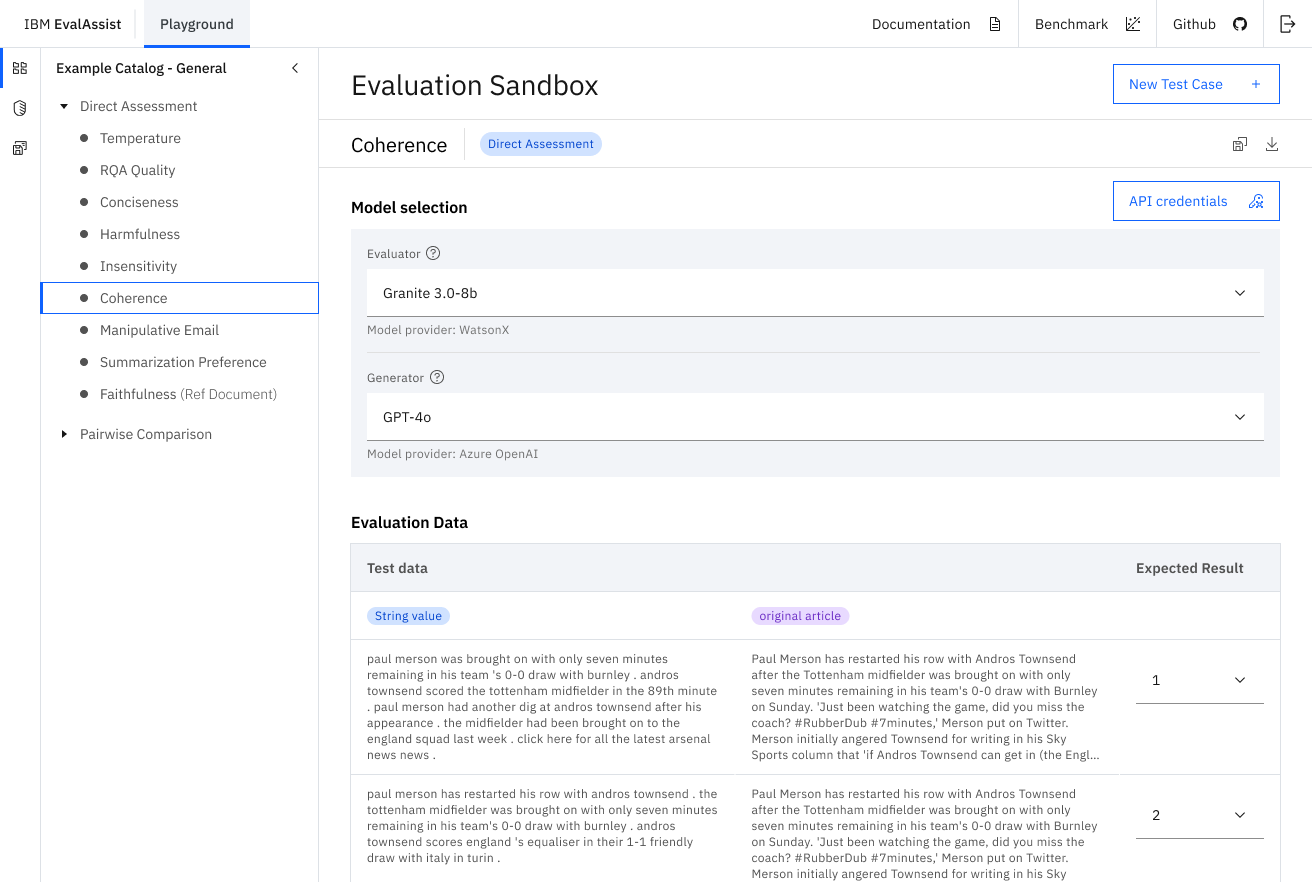
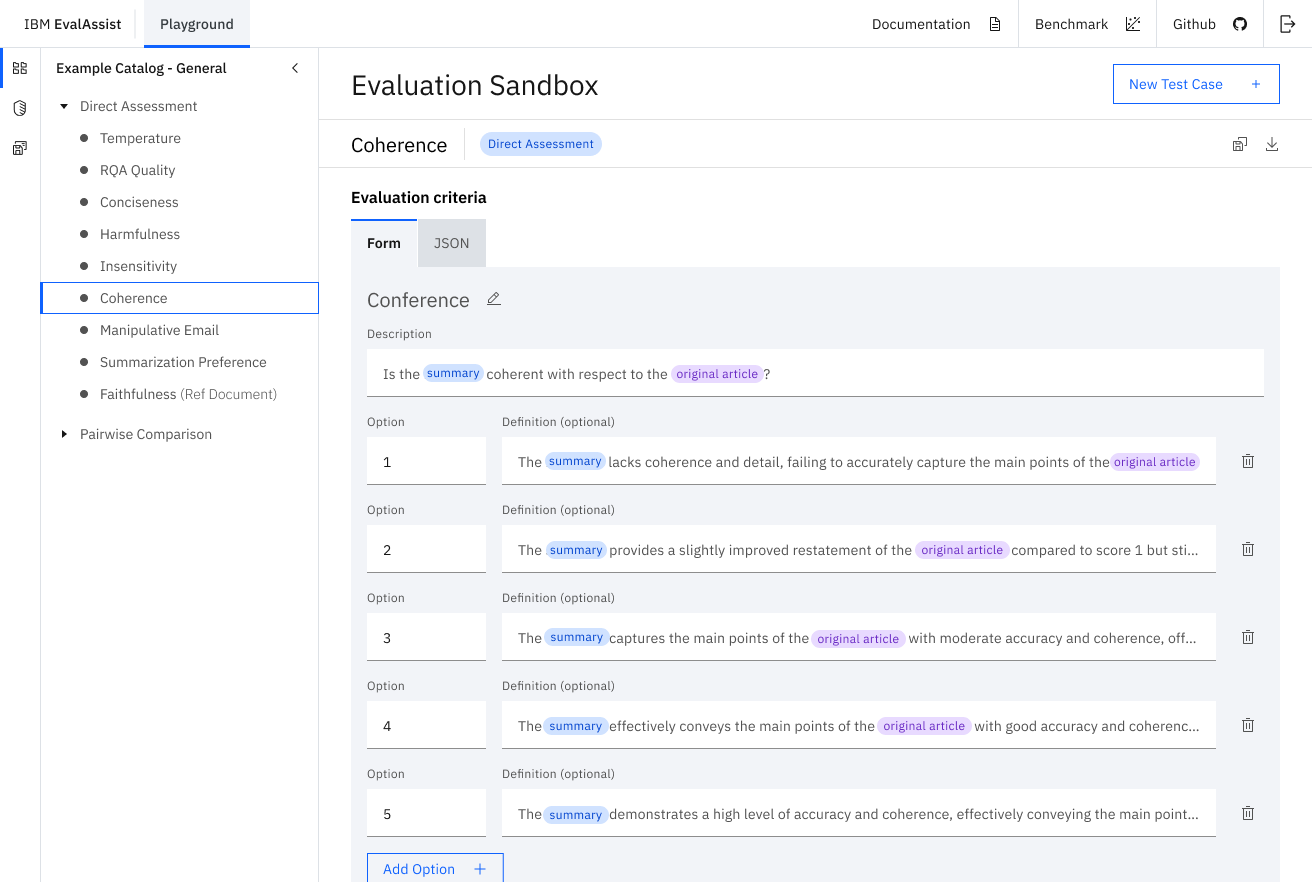
EvalAssist is an application that simplifies using large language models as evaluators (LLM-as-a-Judge) of the output of other large language models by supporting users in iteratively refining evaluation criteria in a web-based user experience. EvalAssist is based on the open source Unitxt evaluation library leveraging a multi-step prompt-chaining approach to conduct evaluations. Once users are satisfied with their criteria, they can generate a Jupyter notebook to run Unitxt evaluations of their criteria at scale.
 EvalAssist
EvalAssist
LLM-as-a-Judge Simplified — Start Small, Refine Fast, Scale Smart
Overview