データの分析、モデルの生成、そしてデプロイ
まとめ¶
この開発者コード・パターンでは、IBM Cloud Pak for Data を使用してデータ・サイエンス・パイプライン全体を通し、ビジネス問題を解決し、ドイツの信用リスク・データセットを使用してローンのデフォルトを予測します。IBM Cloud Pak for Data は、インタラクティブでコラボレーション可能なクラウドベースの環境です。データ・サイエンティスト、開発者、その他データ・サイエンスに関心のある人が、ツールを使ってコラボレーション、共有、データからのインサイトの収集を行い、機械学習や深層学習モデルを構築してデプロイするのに役立ちます。
説明¶
ローンのデフォルトを予測することは、多くの金融機関やその他の関連ビジネスにとって不可欠です。このユースケースでは、私たちが構築する機械学習モデルは、「リスク」(ローン申請者の特徴から、ローンのデフォルトの可能性が高いと予測される)または「リスクなし」(申請者の入力から、ローンが完済されると予測される)の予測を返す分類モデルです。この研究室では、人気の高いライブラリやフレームワークを使って、PythonでJupyter notebookを使ってモデルを構築するアプローチをとります。
このコードパターンを完成させると、以下の方法を理解することができます。
- Jupyter Notebooksを使用して、データを読み込み、視覚化し、分析する。
- IBM Cloud Pak for Data でノートブックを実行する。
- IBM Cloud Pak for Data上でSpark MLibを使用して、機械学習モデルを構築、テスト、デプロイします。
- IBM Cloud Pak for Dataを使って、選択した機械学習モデルを本番環境にデプロイする。
- クライアントとインターフェイスするフロントエンド・アプリケーションを作成して、デプロイしたモデルの消費を開始する。
フロー¶
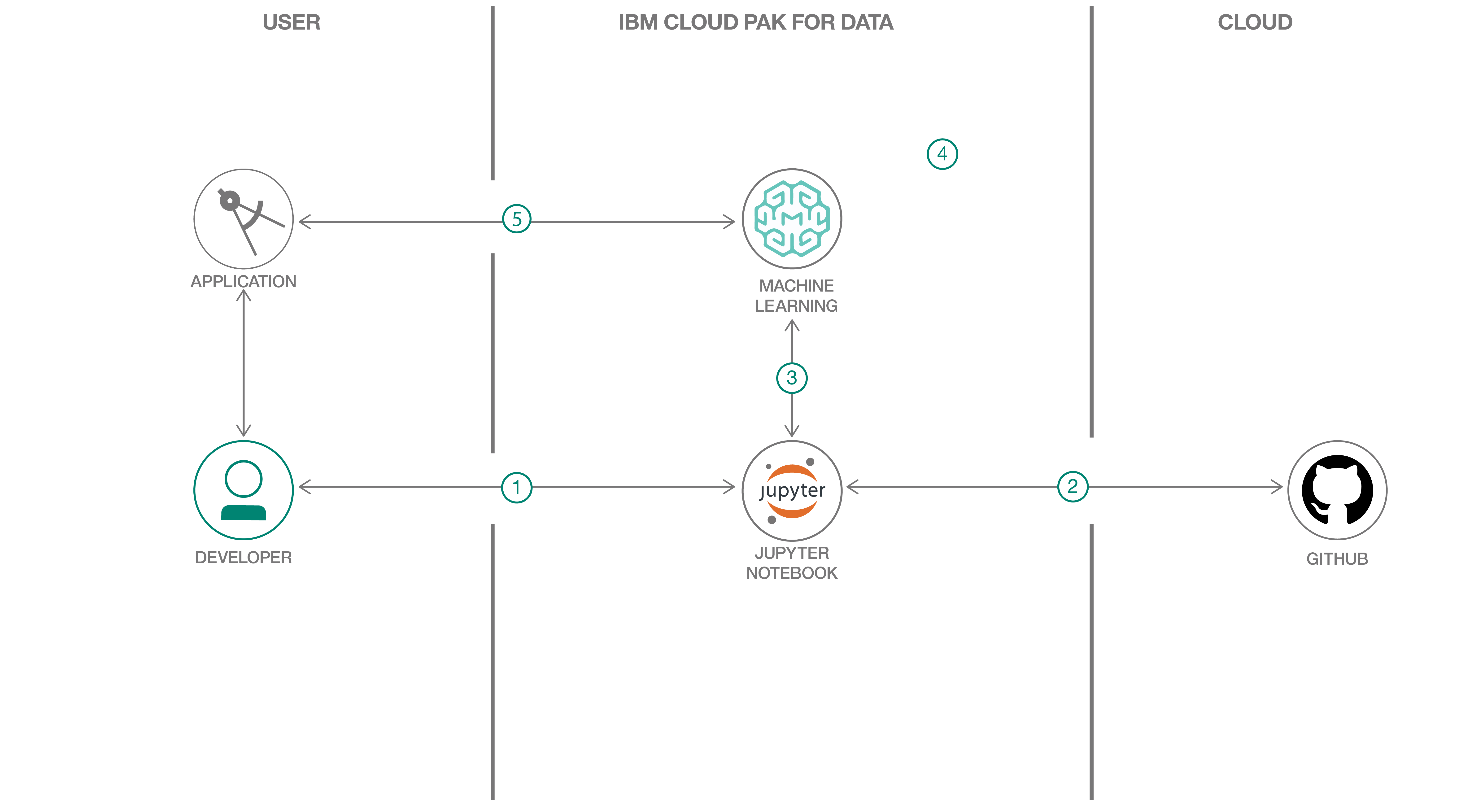
- ユーザーは、Jupyter Notebook を IBM Cloud Pak for Data プラットフォームにロードします。
- ドイツのクレジットデータをJupyter Notebookにロードします。GitHub repoから直接ロードするか、前のチュートリアルに従った後に仮想化データとしてロードします。
- データを前処理し、機械学習モデルを構築し、IBM Cloud Pak for Data上のIBM Watson Machine Learningに保存します。
- 選択した機械学習モデルを IBM Cloud Pak for Data プラットフォーム上の本番環境にデプロイし、スコアリング・エンドポイントを取得します。
- フロントエンド・アプリケーションを使用して、モデルを信用予測に使用します。
指示¶
このコードパターンを使用する準備ができましたか?READMEには、このアプリケーションを起動して使用する方法の詳細が記載されています。
- 新しいプロジェクトを作成します。
- 機械学習のデプロイメント用のスペースを作成する。
- IBM Cloud Pak for Data の学習パスを利用していない場合は、データセットをアップロードします。
- Jupyter Notebook を IBM Cloud Pak for Data にインポートします。
- ノートブックを実行します。
- IBM Cloud Pak for Data の UI を使用してモデルをデプロイします。
- モデルをテストします。
- モデルを使用するPython Flaskアプリを作成します。
Conclusion¶
このコードパターンでは、IBM Cloud Pak for Data を使用し、データ・サイエンス・パイプライン全体を通して、ビジネス上の問題を解決し、ドイツの信用リスク・データセットを使用してローンのデフォルトを予測する方法を示しました。