Data Virtualization
何十年もの間、企業はサイロ化を解消するために、さまざまな業務システムからデータマート、データウェアハウス、データレイクなどの中央データストアにデータをコピーして分析しようとしてきました。しかし、これには多くのコストがかかり、エラーも発生しがちです。ほとんどの企業は、構造や種類が異なる平均33個の独自のデータソースを管理するのに苦労しており、見つけにくく、アクセスしにくいデータサイロに閉じ込められていることが多いのです。
データ仮想化を使えば、データをコピーしたり複製したりすることなく、多くのシステムでデータを照会できるので、コスト削減につながります。また、最新のデータをソースから照会できるため、分析が簡素化され、より最新で正確な分析が可能になります。
このチュートリアルでは、IBM Cloud Pak for Data 上のデータ仮想化を使用して、複数のデータ・ソースにまたがるクエリーを作成する方法を学びます。この例では、Netezza Performance Server または Db2 Warehouse を使用しますが、IBM Data Virtualization 用の組み込みコネクターを持つ多くのデータベース、または JDBC コネクターを持つ任意のデータベースから選択できます。
学習目標¶
このチュートリアルでは、以下の方法を学びます。
- IBM Cloud Pak for Data にデータセットを追加します。
- データ仮想化のためのデータ・ソースを追加する。
- データを仮想化して結合ビューを作成する。
- 仮想化されたデータをプロジェクトに割り当てる。
- ユーザーにロールを追加し、管理タスクを実行する。
前提条件¶
- IBM Cloud Pak for Data
- IBM Cloud Account
- 1つまたは複数のデータソース
見積もり時間¶
このチュートリアルは、約30~45分で完了します。
Step 1.データの取得¶
3つのデータファイルをダウンロードします。
Step 2.データセットについて¶
ここでは、信用リスク/融資のシナリオを使用します。このシナリオでは、貸し手は、リスクモデリングへの異なるアプローチを使用して、より大きく多様な対象者への貸し出しを拡大するという圧力の増加に対応します。これは、伝統的な信用データソースを超えて、代替的な信用データソース(携帯電話プランの支払い履歴、学歴など)に移行することを意味しており、バイアスやその他の予期せぬ相関関係のリスクをもたらす可能性があります。
今回のワークショップで検討している信用リスクモデルは、各ローン申請者に関する20の属性を含むトレーニングデータセットを使用しています。シナリオとモデルは、UCI German Credit datasetに基づいた合成データを使用しています。
Applicant Financial Data¶
このファイルの属性は以下の通りです。
- CUSTOMERID (16進数、主キーとして使用)
- チェックステータス
- クレディセゾン
- 貯蓄残高
- 分割払いプラン
- 既存のクレジットカウント
Applicant Loan Data。¶
このファイルの属性は以下の通りです。
- CUSTOMERID
- LOANDURATION
- LOANPURPOSE
- LOANAMOUNT
- 分割払いのパーセンテージ
- OTHERSONLOAN
- リスク(Risk)
申請者個人データ。¶
このファイルの属性は以下の通りです。
- CUSTOMERID
- Employmentduration
- SEX
- currentesidenceduration
- OWNSPROPERTY
- 年齢
- 住まい
- 職務
- 扶養家族
- 電話
- 外国人労働者
- FIRSTNAME (ファーストネーム)
- LASTNAME (ラストネーム)
- ♪Eメール
- Streetaddress
- CITY
- STATE
- POSTALCODE
Step 3.プロジェクトをセットアップし、IBM Cloud Pak for Data上でデータ仮想化をプロビジョニングします。¶
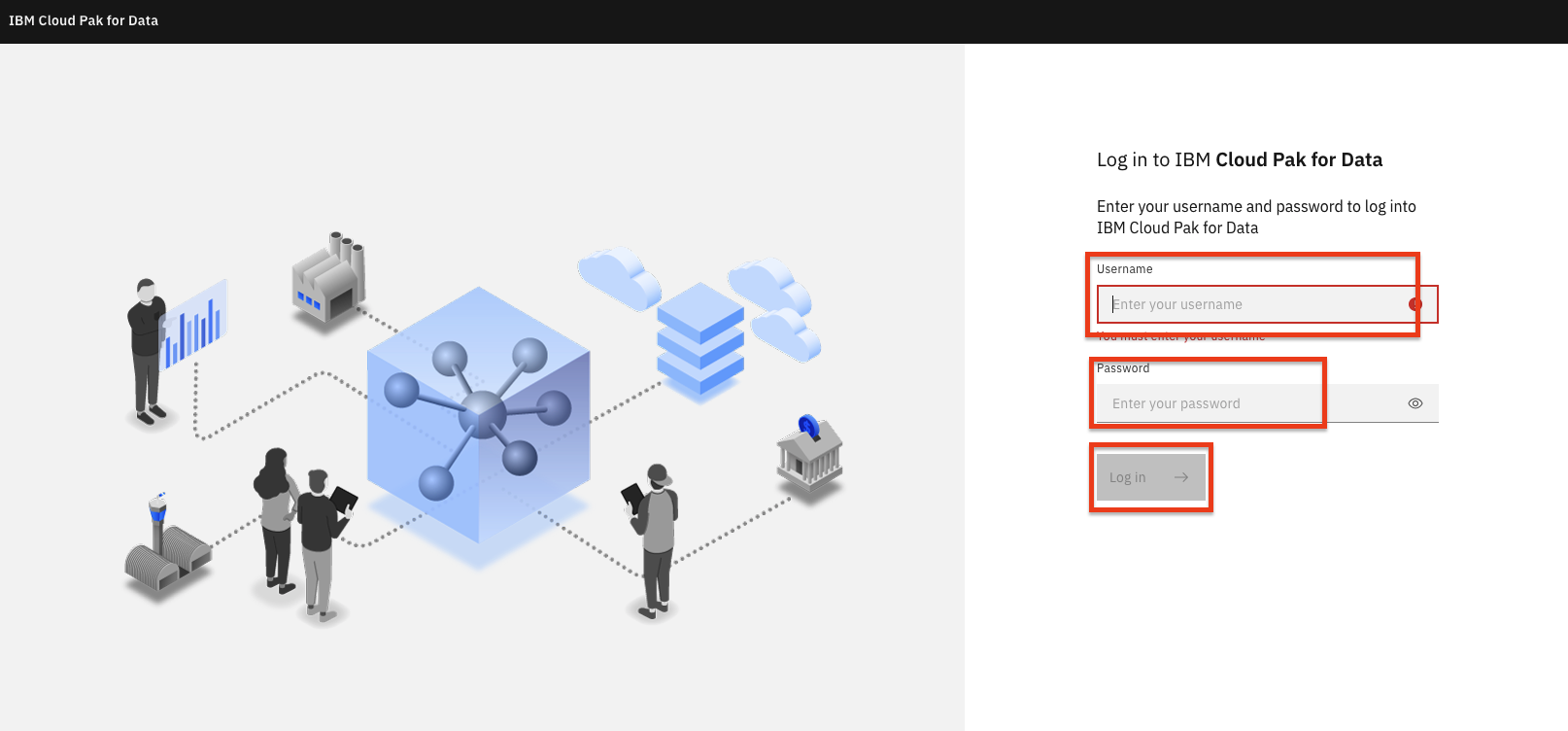
IBM Cloud Pak for Data にログインします。¶
ブラウザを起動して、IBM Cloud Pak for Data のデプロイメントに移動します。
新しい IBM Cloud Pak for Data プロジェクトを作成します。¶
IBM Cloud Pak for Data では、特定の目標を達成するために使用するリソース (問題に対するソリューションを構築するためのリソース) を収集/整理するために、プロジェクトという概念を使用しています。プロジェクトのリソースには、データ、共同研究者、ノートブックやモデルなどの分析資産などがあります。
- (☰)ナビゲーションメニューの「プロジェクト」セクションで、「すべてのプロジェクト」をクリックします。
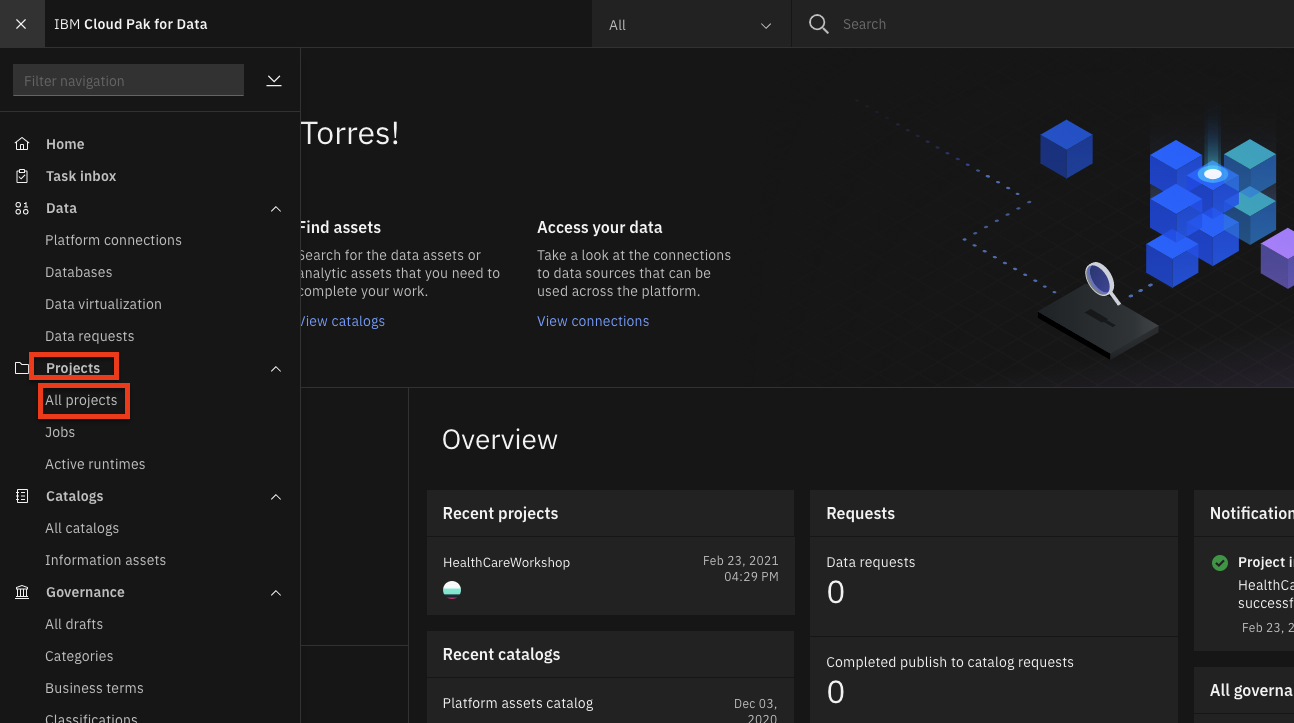
- 右上の 新規プロジェクト ボタンをクリックします。

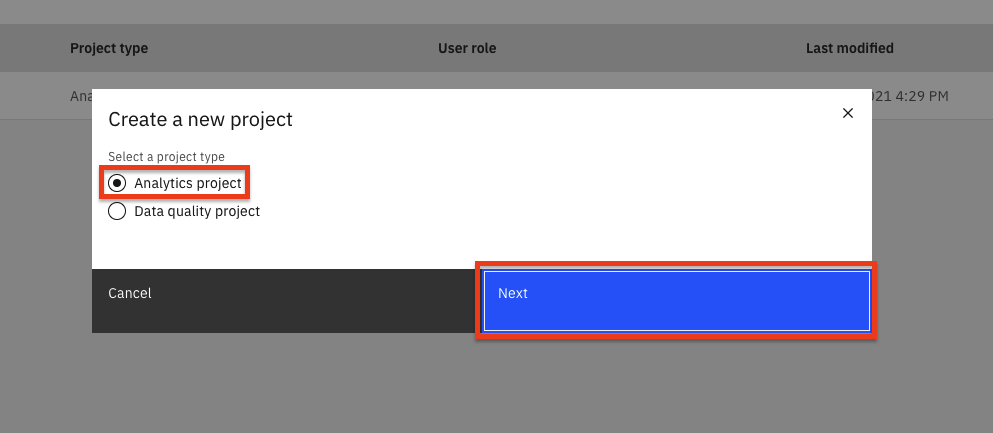
- Analytics projectのラジオボタンを選択し、Nextボタンをクリックします。
- Create an empty project を選択します。
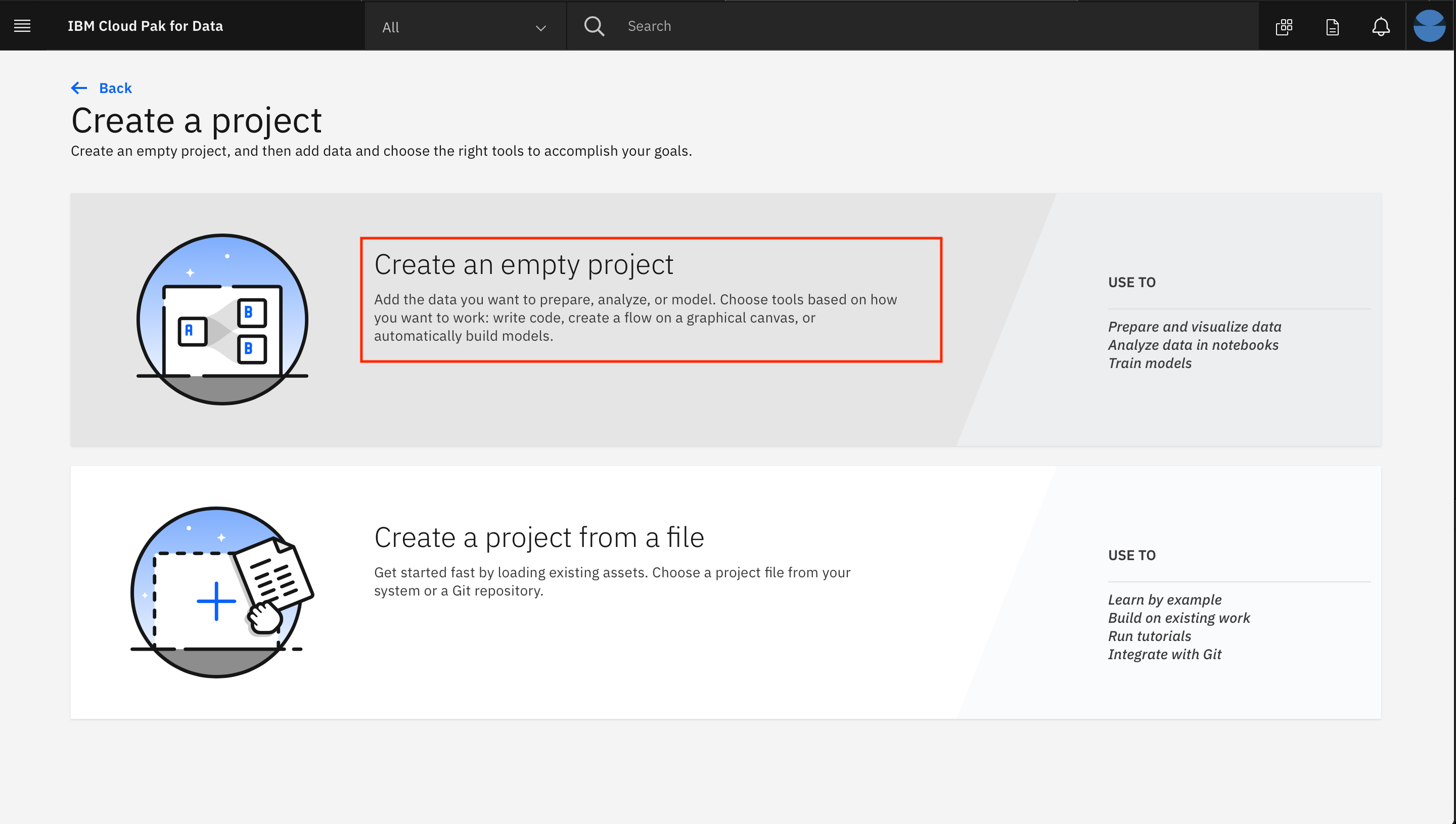
- プロジェクトの名前とオプションの説明を入力し、Createをクリックします。
IBM Cloud Pak for Data でのデータ仮想化のプロビジョニング¶
-
左上(☰)のハンバーガーメニューから、サービス>インスタンスオプションをクリックします。
-
インスタンスの一覧から「データ仮想化」サービスを探し、アクションメニュー(縦3つのドット)をクリックして、インスタンスのプロビジョニングを選択します。
-
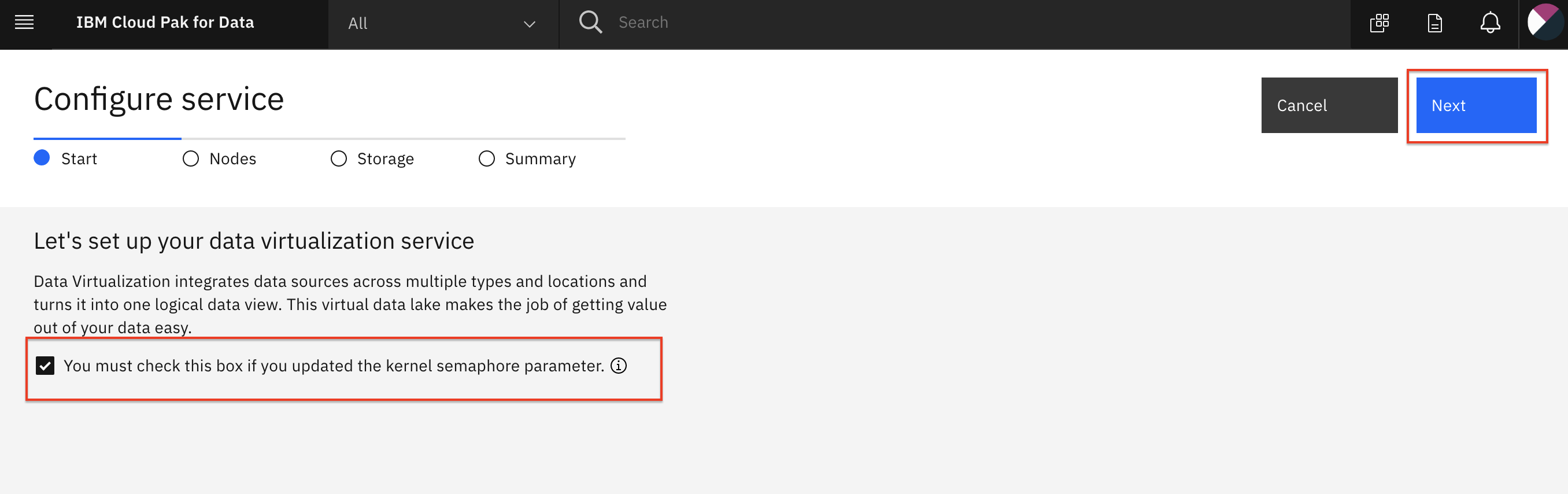
Configure service > Startページで、automatic semaphore configurationのチェックボックスを有効にし、 Nextボタンをクリックします。
- Configure service > Nodes ページでは、デフォルトのシングルノードとリソースの割り当てのまま、 Next ボタンをクリックします。
Note: 64GB以上のRAMを持つDVインスタンスを構成しようとすると、以前は構成エラーが発生していました。
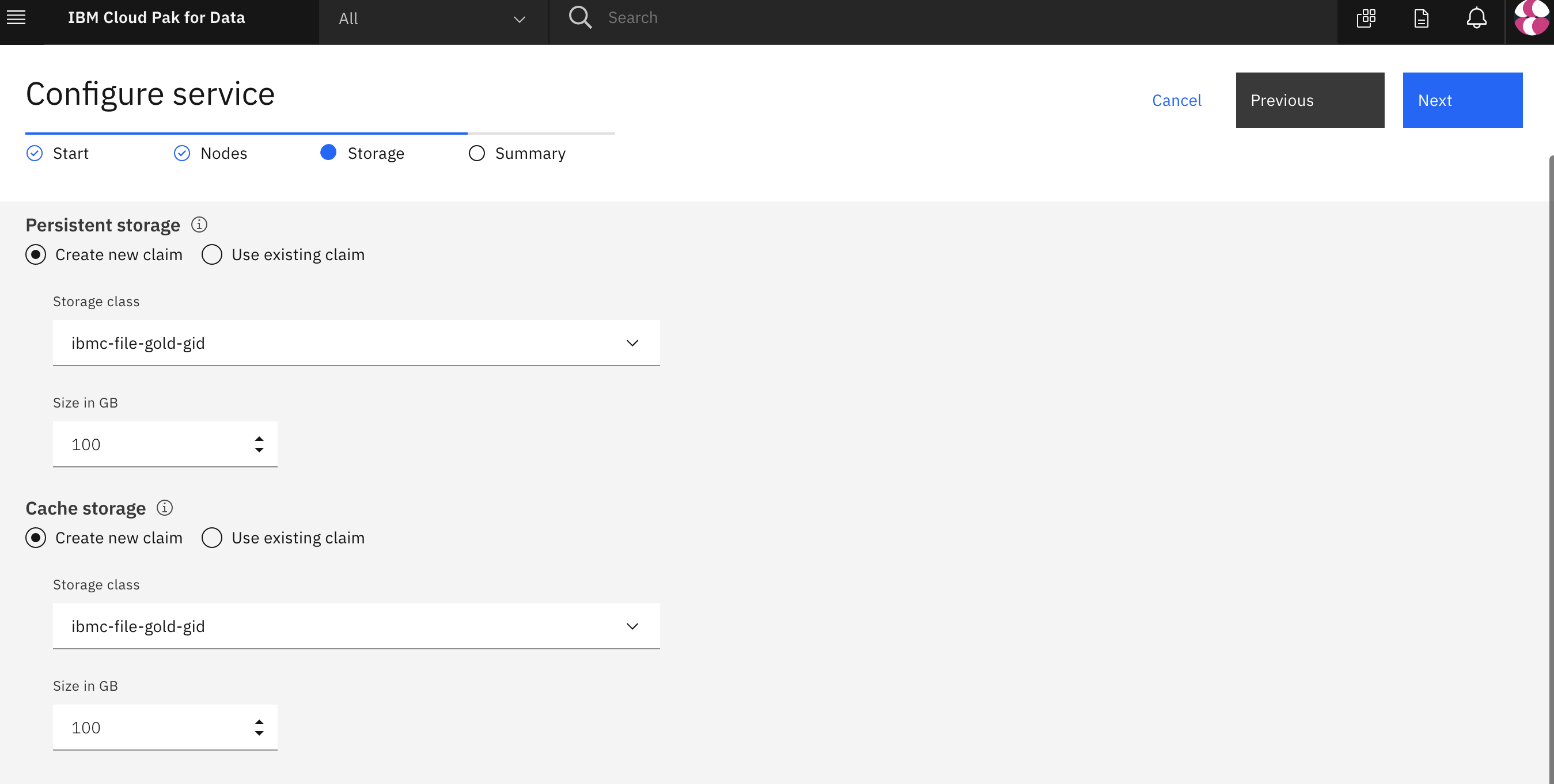
- Configure service > Storage ページで、永続的ストレージとキャッシュストレージの両方のストレージクラスとして ibmc-file-gold-gid を選択する必要があります。その後、Nextボタンをクリックします。
- Configure service > Summary ページで、Configure ボタンをクリックします。
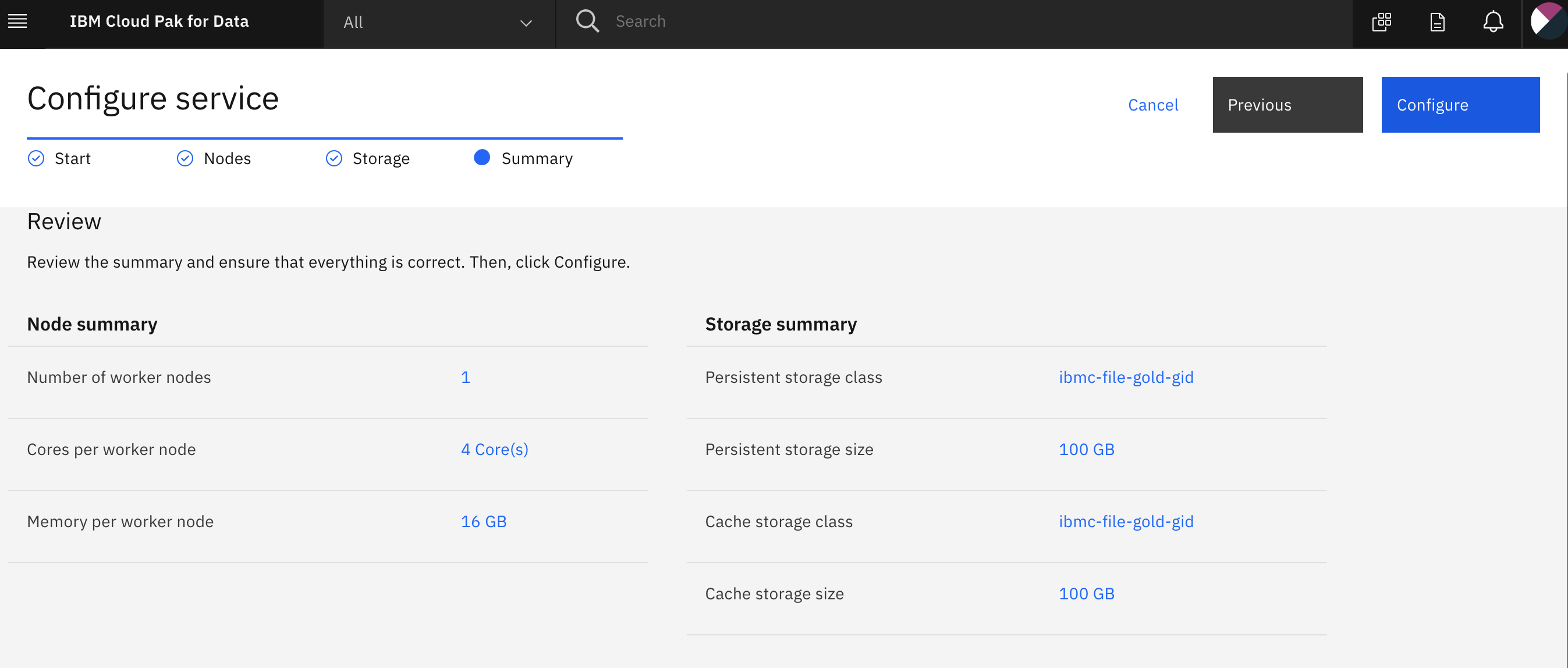
- 設定作業には時間がかかる場合があります。
Step 4.1つまたは複数のデータベースの設定¶
IBM Cloud Pak for Data は、JDBC コネクターを持つあらゆるデータベースと連携できます。このチュートリアルでは、IBM Db2 Warehouse on IBM Cloud、IBM Db2 local on IBM Cloud Pak for Data、および Netezza Performance Server を使用してデモを行います。これらのうちの1つまたは2つ、3つすべて、または他のデータベースの組み合わせを使用することができます。
Netezza Performance Serverのセットアップ¶
Netezza を使ってテストする場合は、以下の手順で行ってください。¶
IBM Netezza Performance Serverへの接続を行う前に、必要なテーブルを作成し、nzload cliを使ってcsvデータをIBM Netezza Performance Serverサーバーにロードする必要がある。nzload cliをインストールするには、instructionに従う。
IBM Netezza Performance Serverのコンソールにログインし、Applicant Loan Data、Applicant Financial Data、Applicant Personal Dataの3つのテーブルを作成する。
なお、これらのテーブルは、nzloadを使ってデータをロードする前に存在している必要があります。その後、nzloadのCLIコマンドを使ってCSVデータをNetezza Performance Serverデータベースにロードすることができます。
もし、nzloadというCLIがサポートされていない場合(Mac OSXなど)は、提供されたCSVデータに対してインサートステートメントを作成し、Netezzaコンソールから実行する必要がある。これはnzloadコマンドより少し時間がかかるかもしれません。
IBMクラウドでDb2ウェアハウスをセットアップする¶
DB2 Warehouse on IBM Cloudでテストする場合は、以下の手順で行ってください。¶
Db2 Warehouse on IBM Cloudを使用することで、クラスター上のリソースを最適に節約することができます。クラスター上でローカルのDb2を使用する場合は、このセクションをスキップし、代わりにset up the local Db2-warehouse on IBM Cloud Pak for Dataを使用します。
注意。続行する前に、IBM Cloud上でDb2ウェアハウスをプロビジョニングしていることを確認してください。
- サービスのプロビジョニングが完了したら、「Service Credentials」にアクセスし、「New credential +」をクリックします。「View credentials」を開き、後で使用するためにクレデンシャル(これは接続の詳細です)をコピーします。
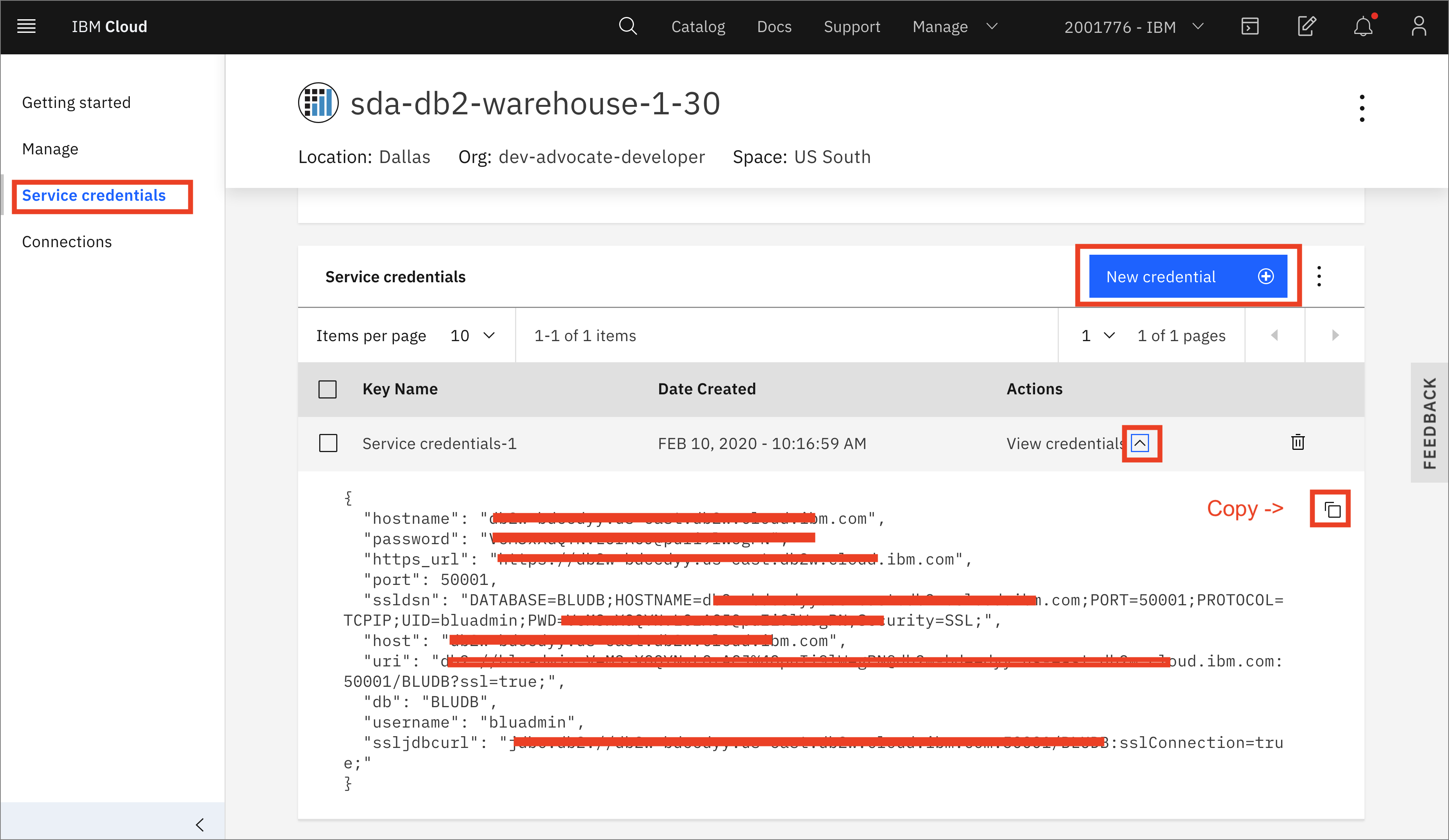
クラウド上のDb2 Warehouseにデータをロードする¶
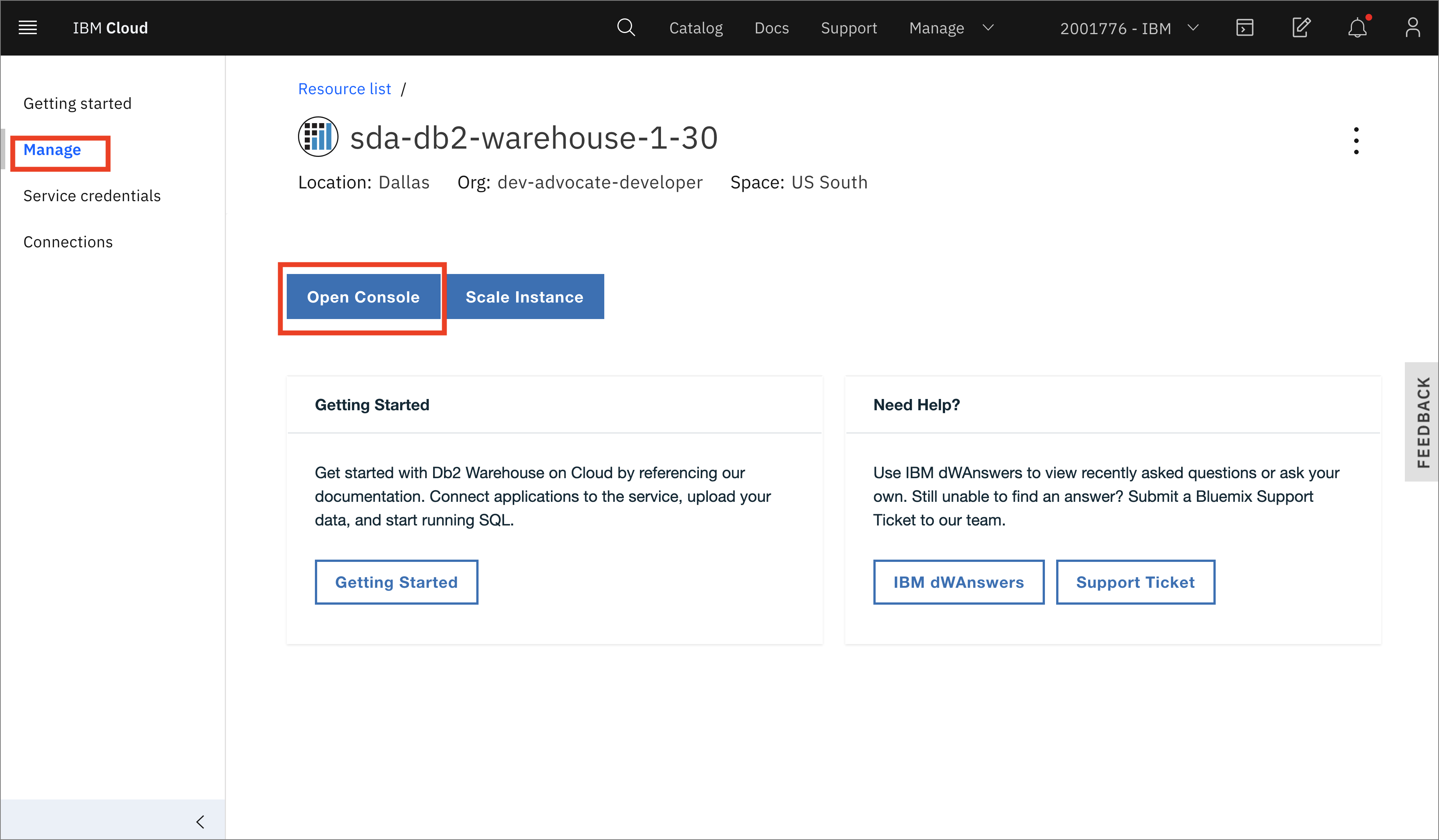
- ここでManageに移動し、Open Consoleをクリックします。
- 左上(☰)のハンバーガーメニューから、Dataをクリックし、Load dataタブをクリックします。
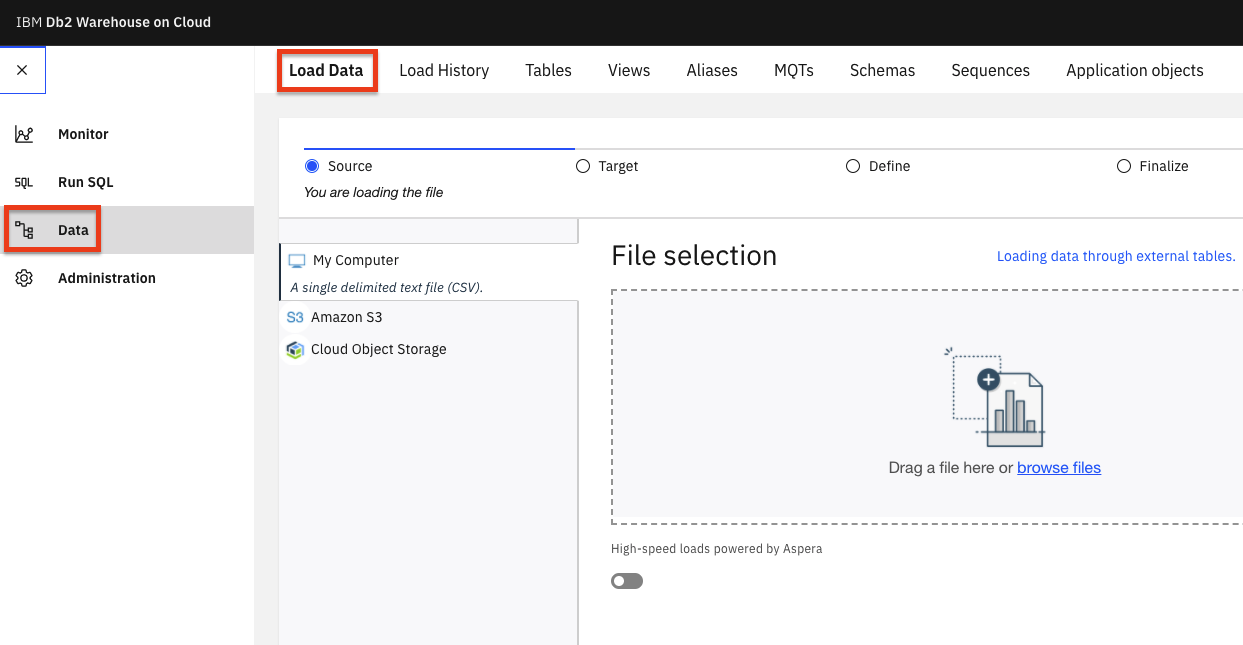
-
ページのFile Selectionセクションにあるbrowse filesリンクをクリックし、このリポジトリをダウンロードした場所に移動し、次に
data/split/に移動してapplicant_financial_data.csvを選択し、Nextボタンをクリックします。 -
+ New Schema をクリックして、名前を
CP4DCREDITにします。 -
新しいスキーマを選択した状態で、 + 新しいテーブル をクリックします。「新しいテーブル名」に「APPLICANTFINANCIALDATA」と入力し、「Create > Next」をクリックします。デフォルトを受け入れて、Nextをクリックし、Begin Loadをクリックします。
-
テーブル名を
APPLICANTPERSONALDATAにして、applicant_personal_data.csvファイルのデータロード手順を繰り返します。 -
applicant_loan_data.csvファイルに対するデータロードのステップを繰り返し、テーブルLOANSに名前を付けます。
SSL証明書の取得¶
-
IBM Cloud Db2 Warehouse インスタンスを使用するには、IBM Cloud Pak for Data の SSL 証明書が必要です。
-
Db2 Warehouseコンソールで、左上(☰)のハンバーガー・メニューから「Adminsitration」をクリックし、次に「Connections」タブをクリックします。「SSL証明書のダウンロード」ボタンをクリックします。
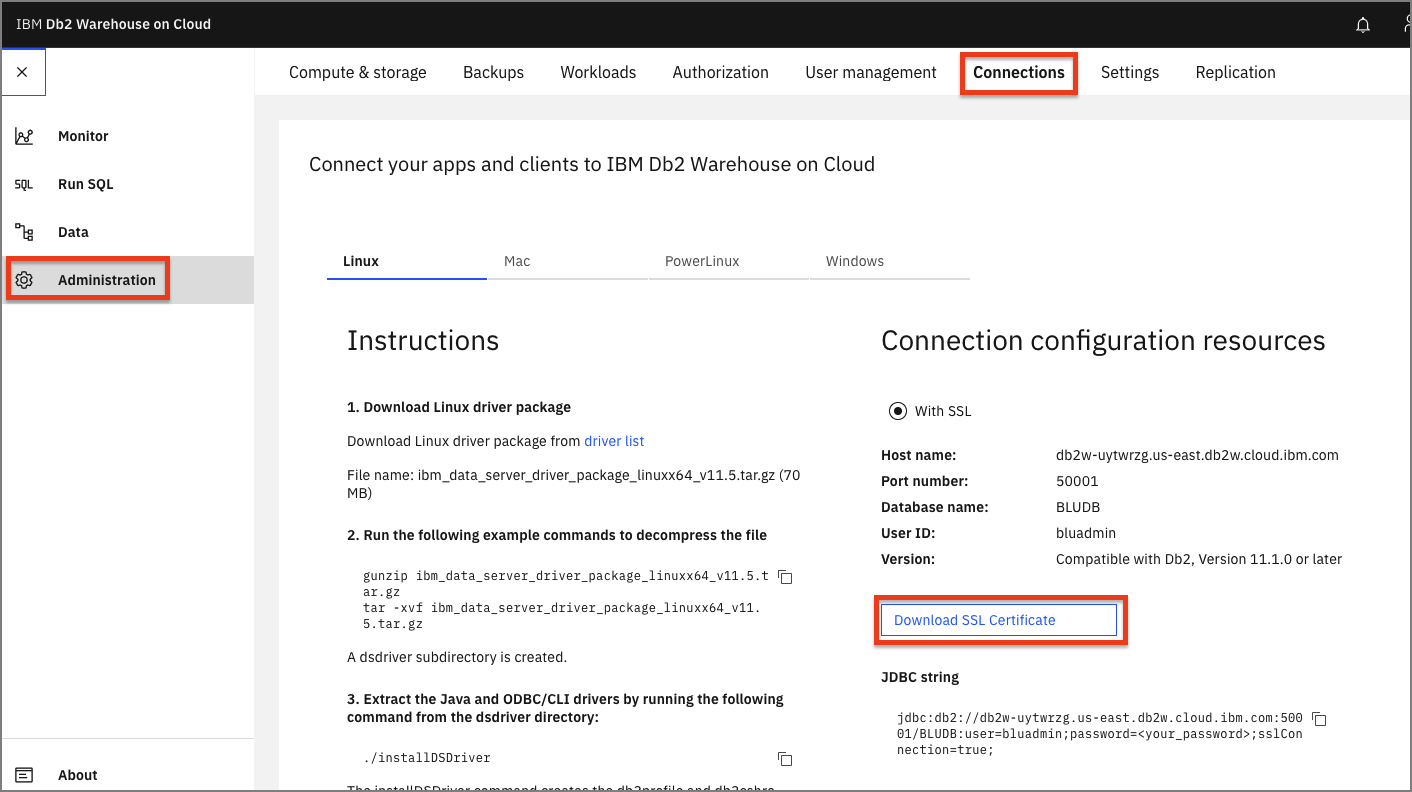
- opensslを使って、SSL証明書を
.crtから.pemファイルに変換する必要があります。以下のコマンドを実行してください。