アプリケーション
公式ドキュメント:
- アプリケーションのパースペクティブ(機能説明): https://www.ibm.com/docs/ja/instana-observability/1.0.302?topic=capabilities-application-perspectives
- アプリケーションのパースペティブ(設定): https://www.ibm.com/docs/ja/instana-observability/current?topic=applications-application-perspectives
- アプリケーションのモニター: https://www.ibm.com/docs/ja/instana-observability/current?topic=instana-monitoring-applications
エージェント設定の確認
エージェントをインストールすると、Instanaセンサーが自動的にインストールされます。
「センサー」とは、特定のテクノロジーをモニターするように設計されたモジュールです。
ほとんどのセンサーは、エージェントのインストール後に自動的にインストールされ、構成されます。
該当のセンサーがインストールされ、正常に構成された場合アプリケーションの「サービス」画面に該当プロセスが表示されるようになります。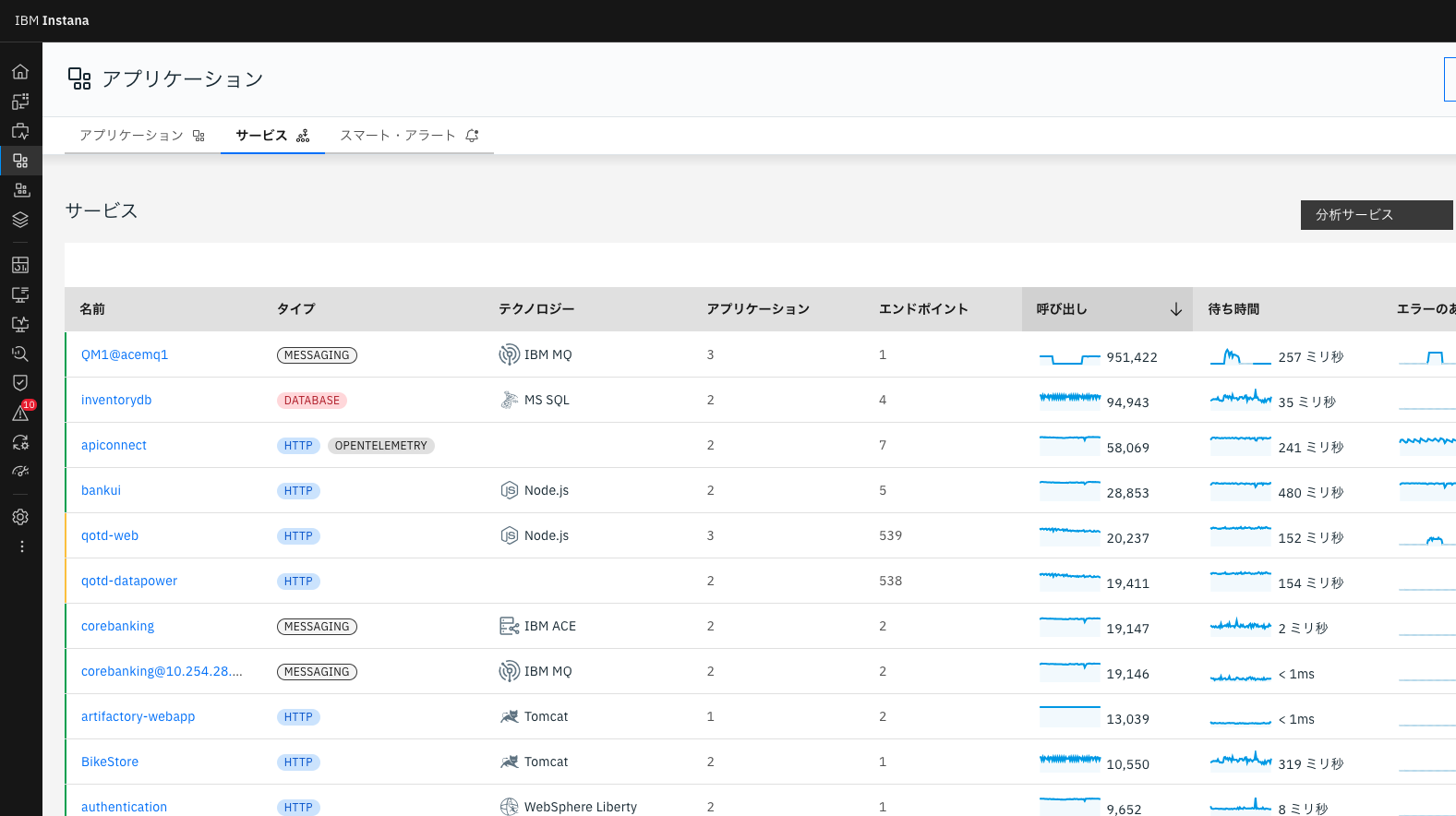
もしこの画面に監視したいテクノロジーが表示されない場合は、センサーの設定を行う必要があります。例えばDb2などはAgentからDb2への接続情報を設定する必要があります。
Instanaは非常に多くのテクノロジーに対応しています。エージェントの設定 に沿ってセンサーの設定を行ってください。
アプリケーション・パースペクティブとは
アプリケーション・パースペクティブとは、アプリケーションを構成するサービスやコンポーネントをグルーピングして見るための考え方 です。
特定のサービスを環境(本番環境、検証環境)やリージョン(US East, JP West)、Kubernetes Namespaceなどでグルーピングすることができます。また、DBAが特定のDBだけを見ることも可能です。
積極的な使用を推奨している機能の一つで、以下のような様々なメリットがあります。
- サービス全体のパフォーマンス(ゴールデンシグナル)を可視化できる
- サービス同士の関係性を簡単に把握できる
- 問題が発生している箇所を迅速に発見できる
詳細は公式ドキュメント:アプリケーションのパースペクティブ を参照してください。
アプリケーション・パースペクティブの作成方法
詳細は公式ドキュメント:アプリケーションのパースペクティブ を参照してください。
続けてアプリケーション・パースペクティブの設定を行います。
アプリケーション・パースペクティブの追加
アプリケーション・パースペクティブ(以降「AP」)を作成する際は、アプリケーション画面の右下にある(+ADD)ボタンをクリックし、新規アプリケーション・パースペクティブを選択することで、設定画面が開きます。
モードの違い
APの作成方法には、単純モードと拡張モードの2種類が存在し、作成画面の右上で切り替えができます。 結果的に入力する情報は同様となりますが、最初は単純モードの使用を推奨します。 単純モードが推奨される理由については、後ほど説明します。

単純モード
単純モードでは、モデルの選択 > アプリケーションの指定 > 詳細の指定 の3ステップを行い、APに含めるサービスの絞り込み条件や、どの程度までトレースを追跡するかを指定します。

それぞれのステップで何を設定するか見ていきましょう。
ステップ1: モデルの選択
アプリケーションの画面で新規アプリケーション・パースペクティブを選択すると、初期表示として、単純モードのステップ1の画面が表示されます。
「モデル化するアプリケーションの種類を指定してください」の表示の下に、様々なモデルが列挙されています。
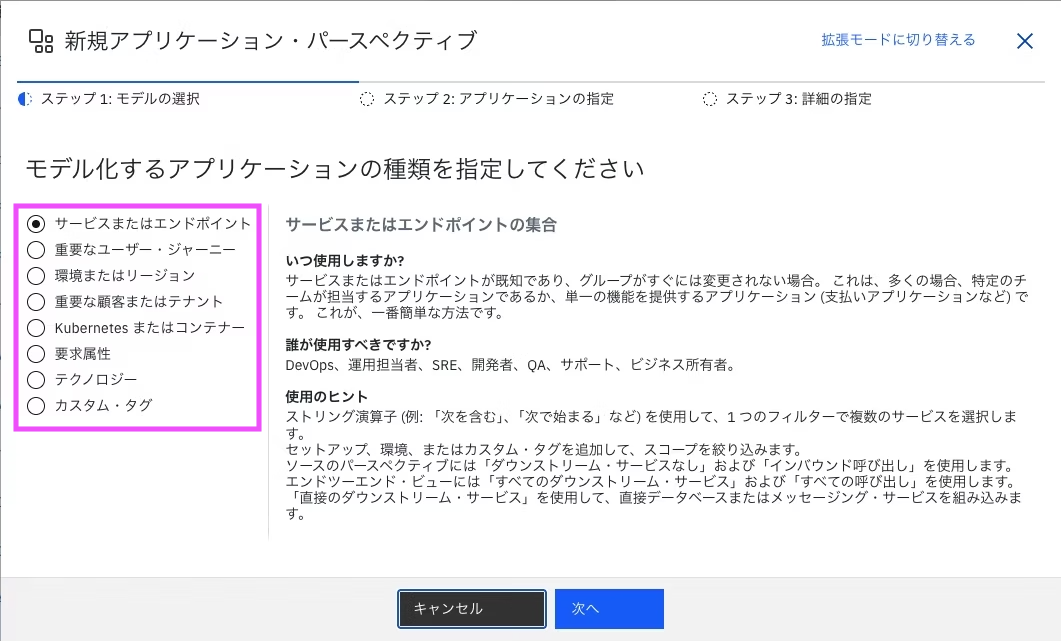
各モデルは下記のような違いがありますが、どちらのモデルを選択しても最終的に完成する機能は同様となります。
- ステップ2で設定するフィルター項目のUIが異なる
- 利用シーンに応じた設定例について、使用のヒントへの記載有無
ゆえに、初期値のままで問題ないため「サービスまたはエンドポイント」を指定して次へをクリックしましょう。
ステップ2: アプリケーションの指定
ここでは、APに含めるサービスやコンポーネントの、フィルター条件と可視化する範囲を指定します。
最初に、フィルターについてです。
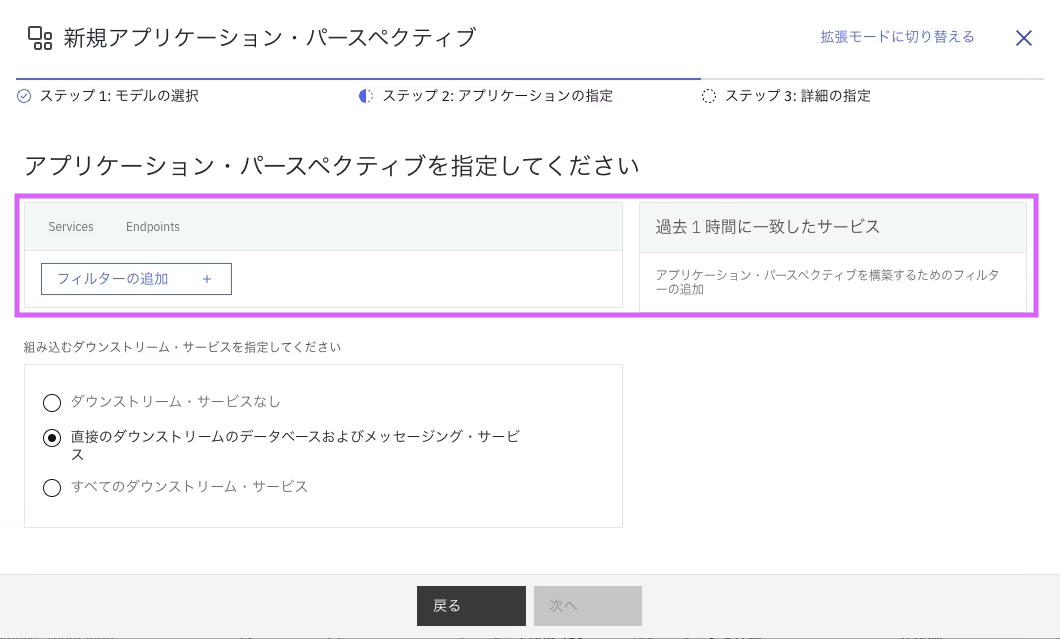
このエリアはクエリ・ビルダーと呼ばれ、1つ以上の条件を指定する必要があります。 フィルターの追加 +をクリックすると、フィルター条件に使用できる項目や論理演算子を選択するメニューが表示されます。
例として、demo-us-eksゾーンに存在するKubernetesクラスターの、Namespacerobot-shop上で稼働しているPodを絞り込みたい場合は、以下の画像のような設定になります。
フィルターを設定すると右側のプレビューパネルに、過去1時間を対象に現在の条件と一致したサービスが表示されます。
指定している条件において、特定のサービスがAPに含まれているか簡単に確認できるようになりました。
最後に組み込むダウンストリーム・サービスを指定しましょう。
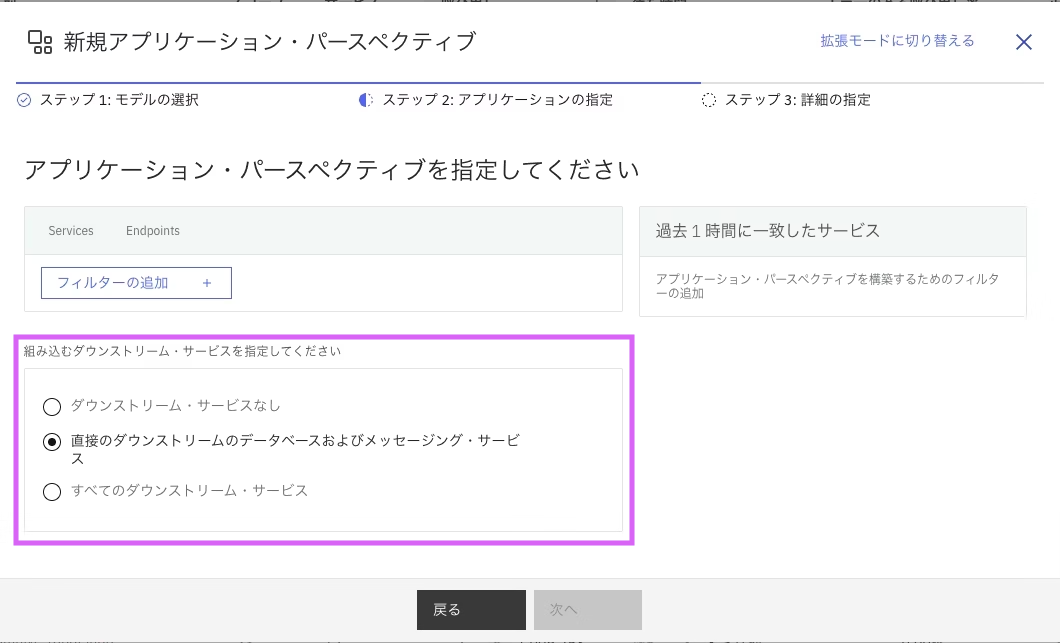
初期値として、2番目の「直接のダウンストリームのデータベースおよびメッセージング・サービス」が指定されています。
以下の画像を参照し、どの範囲までをAPに含め可視化するか指定してください。 「すべてのダウンストリーム・サービス」では、Instanaがトレースできる範囲全てを可視化できるため、障害発生時に得られる情報量が最も多くなります。
APに含めるサービス群が指定できたら次へをクリックしましょう。
ステップ3: 詳細の指定
ここでは、APの名前および呼び出しの範囲を指定します。
AP名に任意の名前を入力します。AP名は後から変更することも可能です。
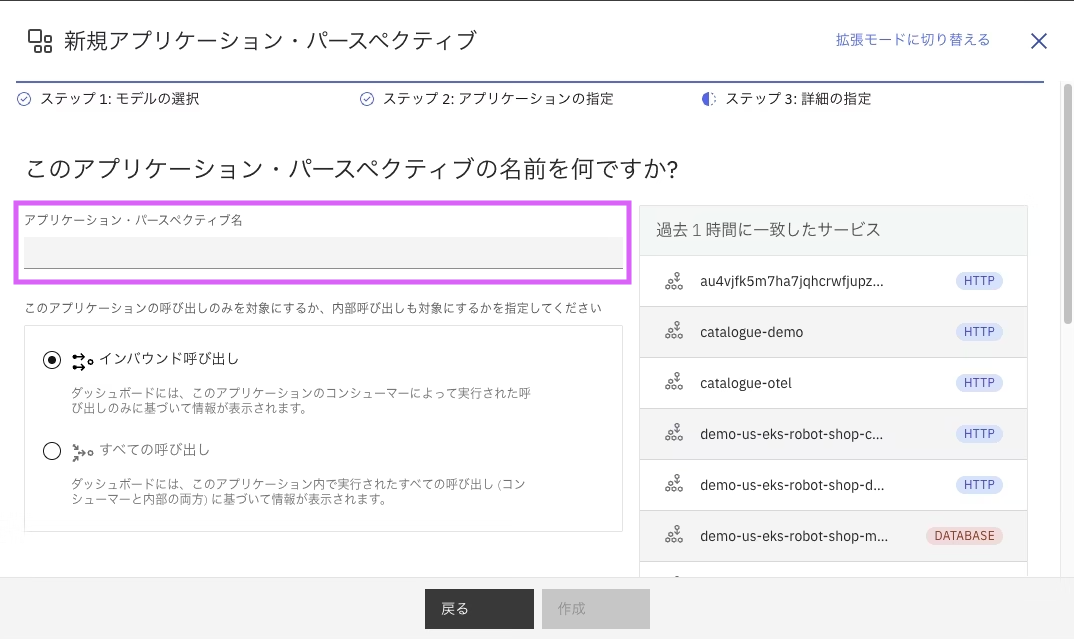
次に、呼び出しの範囲は「インバウンド呼び出し」と「すべての呼び出し」の2つがあります。
- インバウンド呼び出し:外部(エンドユーザーなど)からのリクエストにのみフォーカスする場合に指定
- すべての呼び出し:外部からのリクエストに加え、アプリ内部で発生した呼び出し(サービス間通信)も含める場合に指定
ここまでで設定は完了です。作成をクリックしましょう。
数秒待つとAPが作成・表示されます。 また、さらに少し時間をおいてからゴールデンシグナルや依存関係が見えるか確認しましょう。
拡張モード
設定する項目は単純モードと同様ですが、拡張モードでは設定画面が1画面にまとまっています。 フィルターによって絞り込まれるサービスの確認(プレビューパネル)が不要なInstana上級者の方は拡張モードを使用してください。
アプリケーション・パースペクティブは簡単に追加削除を行うことができ、サービスの監視には影響を及ぼしません。 まずは何度か作成、削除を繰り返してみてください。
アプリケーション・パースペクティブの見方
(詳細は公式ドキュメント:アプリケーションのモニター を参照してください。)
サマリー
一番上には、ゴールデン・シグナル(呼び出し数、エラーのある呼び出し率、待ち時間)およびその履歴が表示されています。グラフにマウスを持っていくと、時間の内訳が表示されます。
下には関連する基盤で発生したインフラストラクチャーの問題および変更、各ゴールデンシグナルでのサービスのランキング、および処理時間が表示されています。 下段中央の トップ・サービスでは、応答が悪化しているサービスやエラー数が多いサービスを確認できますので、特に注視が必要なものが分かります。呼び出し、エラーのある呼び出し率、待ち時間を選択し表示を切り替えてみてください。
パーセンタイル については、このページの最後を参照してください。依存関係
サービス間のつながりが可視化されます。ブラックボックス的なシステムでも関係性を正確に捉えることが可能です。 画像中に該当の箇所はありませんが、問題が起きているサービスは赤や黄でハイライトされるため、問題箇所や影響範囲を迅速に把握できます。 また、線の上に黒や赤の点が流れていますが、これはサービス間のリクエストの流れや量を表します。
サービス
APに含まれるInstanaが検知したサービスの一覧が表示されます。
個々のサービスのテクノロジーやそのタイプ(HTTPやDATABASE, MESSAGINGなど)、および 各サービスのゴールデン・シグナル(呼び出し数、待ち時間、エラーのある呼び出し率)が表示されています。
これらのゴールデン・シグナルに対して、機械学習を適用していますので、呼び出し数の急減や応答性能の遅延、エラー率の急増といったイベントを検知して、画面の右端にて 正常性(緑色のレ点や黄色い△など) として表示されます。赤や黄になっているものがあれば、何らかの問題を抱えているサービスとなります。
エラー・メッセージ
Instanaが自動検出したエラーイベント(失敗したリクエストや例外など特定のエラーメッセージ)が表示されます。
ログ・メッセージ
APに含まれるサービスが出力したWARN〜ERRORレベルのログメッセージが表示されます。

インフラストラクチャー
APに含まれるサービスが稼働するインフラ情報が表示されます。
クラスター/プロセス/コンテナー/ホスト単位で確認することが可能です。
シンセティック・モニタリング
シンセティック・モニタリング(外形監視)と紐付けしている場合に、定期実行される外形監視のテスト結果が表示されます。
脆弱性
IBM Concertとツール連携をすることで、検知したアプリケーションの脆弱性を表示することが可能です。
最適化
Turbonomicとツール連携することで、アプリケーションの稼働状況を鑑みた最適なインフラリソースの増強・削減の提案がされます。
スマート・アラート
通常の閾値監視ではなく、「普段に比べてリクエスト数が多い」などのアプリの動作が通常と異なる状態を検知する、AIを使ったアラートを作成・管理できます。
Qiita記事 InstanaのSmart Alert(スマート・アラート)で楽ちん監視開始 もご参照ください。
サービス・レベル
SLOの作成・管理ができます。 例えば、「今月はエラーバジェットに余裕があるから新機能の追加をしよう」、「今月はエラーバジェットがもう少ないから、既存機能の品質向上に時間を充てよう」などの判断が可能となります。
構成
AP作成時の設定が確認・編集できます。
APが不要になった場合は一番下までスクロールしてAPを削除しましょう。 一度削除すると元に戻せないので注意してください。

補足: パーセンタイル
なぜ「平均値」ではなく「パーセンタイル値」を使うべきか?について補足します。
背景
ウェブサイトやAPIの応答速度は、ユーザー体験やSEO(検索順位)に大きく影響します。
パフォーマンス改善の指標として、平均値ではなくパーセンタイル値を推奨いたします。
平均値 vs パーセンタイル値
平均値は、「全データの合計 ÷ 件数」で計算され、外れ値(極端に遅いレスポンス)に大きく影響を受けます。
一方、パーセンタイルは、例えば、「90パーセンタイル → 上位10%の遅いレスポンスを除いた値」であるように外れ値の影響を受けにくく、実態に近い値を算出することができます。
ロングテール分布の問題
実際のAPIレスポンスは「ロングテール分布」になりやすいです。
一部のリクエストが極端に遅くなることで、平均値が大きく歪みます。
たとえば「全データをダウンロード」などの重いクエリがあると、平均値が跳ね上がります。
パーセンタイルの利点
90パーセンタイルを見ることで、「上位10%の遅いレスポンス」を把握することが可能です。
外れ値に左右されず、多くのユーザーに影響が出ているかどうかを判断しやすいという利点があります。
例えば、「90パーセンタイルが急上昇」していれば、10%以上のユーザーに影響が出ているということです。
実用面での活用
パフォーマンス監視やSLO(サービスレベル目標)の設定において、パーセンタイル値をKPIにすることが推奨されます。 例:95パーセンタイル以下で応答時間500ms以内、など。
参考(https://gigazine.net/news/20210916-web-percentile-useful/)