Prompt Declaration Language
LLMs will continue to change the way we build software systems. They are not only useful as coding assistants, providing snippets of code, explanations, and code transformations, but they can also help replace components that could only previously be achieved with rule-based systems. Whether LLMs are used as coding assistants or software components, reliability remains an important concern. LLMs have a textual interface and the structure of useful prompts is not captured formally. Programming frameworks do not enforce or validate such structures since they are not specified in a machine-consumable way. The purpose of the Prompt Declaration Language (PDL) is to allow developers to specify the structure of prompts and to enforce it, while providing a unified programming framework for composing LLMs with rule-based systems.
PDL is based on the premise that interactions with an LLM are mainly for the purpose of generating some kind of data. So PDL allows users to specify the shape of data to be generated in a declarative way (in YAML), and is agnostic of any programming language. Because of its data-oriented nature, it can be used to easily express a variety of data generation tasks (inference, data synthesis, data generation for model training, etc...). PDL takes care of chat templates and accumulates input messages to LLMs implicitly, making it easier to interact with LLMs and less verbose.
PDL provides the following features:
- Ability to use any LLM locally or remotely via LiteLLM, including IBM's watsonx, as well as the Granite IO Processor framework
- Ability to templatize not only prompts for one LLM call, but also composition of LLMs with tools (code and APIs). Templates can encompass tasks of larger granularity than a single LLM call
- Control structures: variable definitions and use, conditionals, loops, functions
- Ability to read from files and stdin, including JSON data
- Ability to call out to code and call REST APIs (Python)
- Type checking input and output of model calls, used for structured decoding
- Python SDK
- Support for chat APIs and chat templates
- Live Explorer, a UI tool for exploring traces and live programming
The PDL interpreter takes a PDL program as input and generates data by executing its instructions (calling out to models, code, etc...).
See below for a quick reference, followed by installation notes and an overview of the language. A more detailed description of the language features can be found in this tutorial.
Quick Reference

(See also PDF version.)
Interpreter Installation
The interpreter has been tested with Python versions 3.11, 3.12, and 3.14, on macOS and Linux. For Windows, please use WSL.
To install the requirements for pdl, execute the command:
pip install prompt-declaration-language
To install the dependencies for development of PDL and execute all the example, execute the command:
pip install 'prompt-declaration-language[examples]'
The Live Explorer can be installed as follows (MacOS):
brew install pdl
For other platforms, see installation notes.
You can run PDL with LLM models in local using Ollama, or other cloud service. See here for instructions on how to install an Ollama model locally.
Most examples in this repository use IBM Granite models on Ollama and some are on Replicate. In order to run these examples, you need to create a free account on Replicate, get an API key and store it in the environment variable:
REPLICATE_API_TOKEN
In order to use foundation models hosted on watsonx via LiteLLM, you need a watsonx account (a free plan is available) and set up the following environment variables:
WX_URL, the API url (set tohttps://{region}.ml.cloud.ibm.com) of your watsonx instance. The region can be found by clicking in the upper right corner of the watsonx dashboard (for example a valid region isus-southoteu-gb).WX_API_KEY, the API key (see information on key creation)WATSONX_PROJECT_ID, the project hosting the resources (see information about project creation and finding project ID).
For more information, see documentation.
To run the interpreter:
pdl <path/to/example.pdl>
The folder examples contains many examples of PDL programs. They cover a variety of prompting patterns such as CoT, RAG, ReAct, and tool use.
We highly recommend to edit PDL programs using an editor that support YAML with JSON Schema validation. For example, you can use VSCode with the YAML extension and configure it to use the PDL schema. This enables the editor to display error messages when the yaml deviates from the PDL syntax and grammar. It also provides code completion.
The PDL repository has been configured so that every *.pdl file is associated with the PDL grammar JSONSchema (see settings). You can set up your own VSCode PDL projects similarly using the following .vscode/settings.json file:
{
"yaml.schemas": {
"https://ibm.github.io/prompt-declaration-language/dist/pdl-schema.json": "*.pdl"
},
"files.associations": {
"*.pdl": "yaml",
}
}
The interpreter executes Python code specified in PDL code blocks. To sandbox the interpreter for safe execution,
you can use the --sandbox flag which runs the interpreter in a Docker-compatible container. Without this flag, the interpreter
and all code is executed locally. To use the --sandbox flag, you need to have a Docker daemon running, such as
Rancher Desktop.
We can pass initial data to the interpreter to populate variables used in a PDL program, as follows:
pdl --data <JSON-or-YAML-data> <my-example>
For an example, see file.
This can also be done by passing a JSON or YAML file:
pdl --data-file <JSON-or-YAML-file> <my-example>
The interpreter can also output a trace file that is used by the Live Explorer app (see Live Document):
pdl --trace <file.json> <my-example>
The interpreter can be made to output the background context:
pdl --stream context <my-example>
For more information:
pdl --help
Overview
In PDL, we can write some YAML to create a prompt and call an LLM:
description: Simple LLM interaction
text:
- "Hello\n"
- model: ollama/granite-code:8b
parameters:
stop: ['!']
temperature: 0
The description field is a description for the program. Field text contains a list of either strings or blocks which together form the text to be produced. In this example, the text starts with the string "Hello\n" followed by a block that calls out to a model. In this case, it is model with id ollama/granite-code:8b on Ollama, via LiteLLM, with the indicated parameters: the stop sequence is !, and temperature set to 0. Stop sequences are provided as a list of strings. The input to the model call is everything that has been produced so far in the program (here "Hello\n").
When we execute this program using the PDL interpreter:
pdl examples/hello/hello.pdl
we obtain the following:
Hello
Hi there
where Hi there was produced by Granite. In general, PDL provides blocks for calling models, Python code, and makes it easy to compose them together with control structures (sequencing, conditions, loops).
A similar example on watsonx would look as follows:
text:
- "Hello\n"
- model: watsonx/ibm/granite-34b-code-instruct
parameters:
stop: ['!']
temperature: 0
Notice the syntactic differences. Model ids on watsonx start with watsonx.
Watsonx also provides a text completion endpoint as shown in the following example. A text completion endpoint does not take chat templates into account:
text:
- "Hello\n"
- model: watsonx_text/ibm/granite-34b-code-instruct
parameters:
stop: ['!']
decoding_method: sample
Instead of providing temperature: 0, the user can write decoding_method: greedy, or choose sample as in the above example.
The same example on Replicate:
text:
- "Hello\n"
- model: replicate/ibm-granite/granite-3.2-8b-instruct
parameters:
stop: "!"
temperature: 0
A PDL program computes two data structures. The first is a JSON corresponding to the result of the overall program, obtained by aggregating the results of each block. This is what is printed by default when we run the interpreter. The second is a conversational background context, which is a list of role/content pairs, where we implicitly keep track of roles and content for the purpose of communicating with models that support chat APIs. The contents in the latter correspond to the results of each block. The conversational background context is the list of messages used to make calls to LLMs via LiteLLM.
The PDL interpreter can also stream the background conversation instead of the result:
pdl --stream context examples/hello/hello.pdl
See the tutorial for more information about the conversational background context and how to use roles and chat templates.
Consider now an example from AI for code, where we want to build a prompt template for code explanation. We have a JSON file as input containing the source code and some information regarding the repository where it came from.
For example, given the data in this JSON file:
source_code:
|
@SuppressWarnings("unchecked")
public static Map<String, String> deserializeOffsetMap(String lastSourceOffset) throws IOException {
Map<String, String> offsetMap;
if (lastSourceOffset == null || lastSourceOffset.isEmpty()) {
offsetMap = new HashMap<>();
} else {
offsetMap = JSON_MAPPER.readValue(lastSourceOffset, Map.class);
}
return offsetMap;
}
repo_info:
repo: streamsets/datacollector
path: stagesupport/src/main/java/com/.../OffsetUtil.java
function_name: OffsetUtil.deserializeOffsetMap
we would like to express the following prompt and submit it to an LLM:
Here is some info about the location of the function in the repo.
repo:
streamsets/datacollector
path: stagesupport/src/main/java/com/.../OffsetUtil.java
Function_name: OffsetUtil.deserializeOffsetMap
Explain the following code:
@SuppressWarnings("unchecked")
public static Map<String, String> deserializeOffsetMap(String lastSourceOffset) throws IOException {
Map<String, String> offsetMap;
if (lastSourceOffset == null || lastSourceOffset.isEmpty()) {
offsetMap = new HashMap<>();
} else {
offsetMap = JSON_MAPPER.readValue(lastSourceOffset, Map.class);
}
return offsetMap;
}
In PDL, this would be expressed as follows (see file):
description: Code explanation example
defs:
# Read data.yaml as YAML and store it in a variable `CODE`
CODE:
read: ./data.yaml
parser: yaml
text:
# Output the `source_code:` of the YAML to the console
- "\n${ CODE.source_code }\n"
# Use ollama to invoke a Granite model with a prompt
- model: ollama_chat/granite4:micro
input: |
Here is some info about the location of the function in the repo.
repo:
${ CODE.repo_info.repo }
path: ${ CODE.repo_info.path }
Function_name: ${ CODE.repo_info.function_name }
Explain the following code:
```
${ CODE.source_code }```
parameters:
temperature: 0
In this program we first define some variables using the defs construct. Here CODE is defined to be a new variable, holding the result of the read block that follows.
A read block can be used to read from a file or stdin. In this case, we read the content of the file ./data.yaml, parse it as YAML using the parser construct, then
assign the result to variable CODE.
Next we define a text, where the first block is simply a string and writes out the source code. This is done by accessing the variable CODE. The syntax ${ var } is a Jinja expression and means accessing the value of a variable in the scope. Since CODE contains YAML data, we can also access fields such as CODE.source_code.
The second block calls a granite model on Ollama via LiteLLM. Here we explicitly provide an input field which means that we do not pass the entire text produced so far to the model, but only what is specified in this field. In this case, we specify our template by using the variable CODE as shown above.
When we execute this program with the PDL interpreter, we obtain the following text:
@SuppressWarnings("unchecked")
public static Map<String, String> deserializeOffsetMap(String lastSourceOffset) throws IOException {
Map<String, String> offsetMap;
if (lastSourceOffset == null || lastSourceOffset.isEmpty()) {
offsetMap = new HashMap<>();
} else {
offsetMap = JSON_MAPPER.readValue(lastSourceOffset, Map.class);
}
return offsetMap;
}
The code is a Java method that takes a string `lastSourceOffset` as input and returns a `Map<String, String>`. The method uses the Jackson library to deserialize the JSON-formatted string into a map. If the input string is null or empty, an empty HashMap is returned. Otherwise, the string is deserialized into a Map using the `JSON_MAPPER.readValue()` method.
Notice that in PDL variables are used to templatize any entity in the document, not just textual prompts to LLMs. We can add a block to this document to evaluate the quality of the output using a similarity metric with respect to our ground truth. See file:
description: Code explanation example
defs:
CODE:
read: ./data.yaml
parser: yaml
TRUTH:
read: ./ground_truth.txt
text:
- "\n${ CODE.source_code }\n"
- model: ollama_chat/granite4:micro
def: EXPLANATION
input: |
Here is some info about the location of the function in the repo.
repo:
${ CODE.repo_info.repo }
path: ${ CODE.repo_info.path }
Function_name: ${ CODE.repo_info.function_name }
Explain the following code:
```
${ CODE.source_code }```
parameters:
temperature: 0
- |
EVALUATION:
The similarity (Levenshtein) between this answer and the ground truth is:
- def: EVAL
lang: python
# (Use `pip install textdistance` if needed to install the textdistance package)
code: |
import textdistance
expl = """
${ EXPLANATION }
"""
truth = """
${ TRUTH }
"""
# (In PDL, set `result` to the output you wish for your code block.)
result = textdistance.levenshtein.normalized_similarity(expl, truth)
This program has an input block that reads the ground truth from filename examples/code/ground_truth.txt and assigns its contents to variable TRUTH. It also assigns the output of the model to the variable EXPLANATION, using a def construct. In PDL, any block can have a def to capture the result of that block in a variable. The last block is a call to Python code, which is included after the code field. Notice how code is included here simply as data. We collate fragments of Python with outputs obtained from previous blocks. This is one of the powerful features of PDL: the ability to specify the execution of code that is not known ahead of time. We can use LLMs to generate code that is later executed in the same programming model. This is made possible because PDL treats code as data, like any another part of the document.
When we execute this new program, we obtain the following:
@SuppressWarnings("unchecked")
public static Map<String, String> deserializeOffsetMap(String lastSourceOffset) throws IOException {
Map<String, String> offsetMap;
if (lastSourceOffset == null || lastSourceOffset.isEmpty()) {
offsetMap = new HashMap<>();
} else {
offsetMap = JSON_MAPPER.readValue(lastSourceOffset, Map.class);
}
return offsetMap;
}
The code is a Java method that takes a string `lastSourceOffset` as input and returns a `Map<String, String>`. The method uses the Jackson library to deserialize the JSON-formatted string into a map. If the input string is empty or null, an empty HashMap is returned. Otherwise, the string is deserialized into a Map using the `JSON_MAPPER.readValue()` method.
EVALUATION:
The similarity (Levenshtein) between this answer and the ground truth is:
0.3090614886731392
PDL allows rapid prototyping of prompts by allowing the user to change prompts and see their immediate effects on metrics. Try it!
Finally, we can output JSON data as a result of this program, as follows:
description: Code explanation example
defs:
CODE:
read: ./data.yaml
parser: yaml
TRUTH:
read: ./ground_truth.txt
EXPLANATION:
model: ollama_chat/granite4:micro
input:
|
Here is some info about the location of the function in the repo.
repo:
${ CODE.repo_info.repo }
path: ${ CODE.repo_info.path }
Function_name: ${ CODE.repo_info.function_name }
Explain the following code:
```
${ CODE.source_code }```
EVAL:
lang: python
code:
|
import textdistance
expl = """
${ EXPLANATION }
"""
truth = """
${ TRUTH }
"""
result = textdistance.levenshtein.normalized_similarity(expl, truth)
data:
input: ${ CODE }
output: ${ EXPLANATION }
metric: ${ EVAL }
The data block takes various variables and combines their values into a JSON object with fields input, output, and metric.
The output of this program is the corresponding serialized JSON object, with the appropriate treatment of quotation marks. Similarly PDL can read jsonl files and create jsonl files by piping to a file.
PDL Language Tutorial
Debugging Tools
Live Explorer
PDL has a Live Explorer to help in program understanding given an execution trace.
To produce an execution trace consumable by the Live Explorer, you can run the interpreter with the --trace argument:
pdl <my-example> --trace <my-example_trace.json>
This produces an additional file named my-example_trace.json that can be uploaded to the Live Explorer visualizer tool. The Live Explorer shows a timeline of execution and a tile for every block. By clicking on a tile, the user can discover more information such as input/context/output for LLM calls. It also provides the ability to re-run a block for eventual live programming.
This is similar to a spreadsheet for tabular data, where data is in the forefront and the user can inspect the formula that generates the data in each cell. In the Live Explorer, cells are not uniform but can take arbitrary extents. Clicking on them similarly reveals the part of the code that produced them.
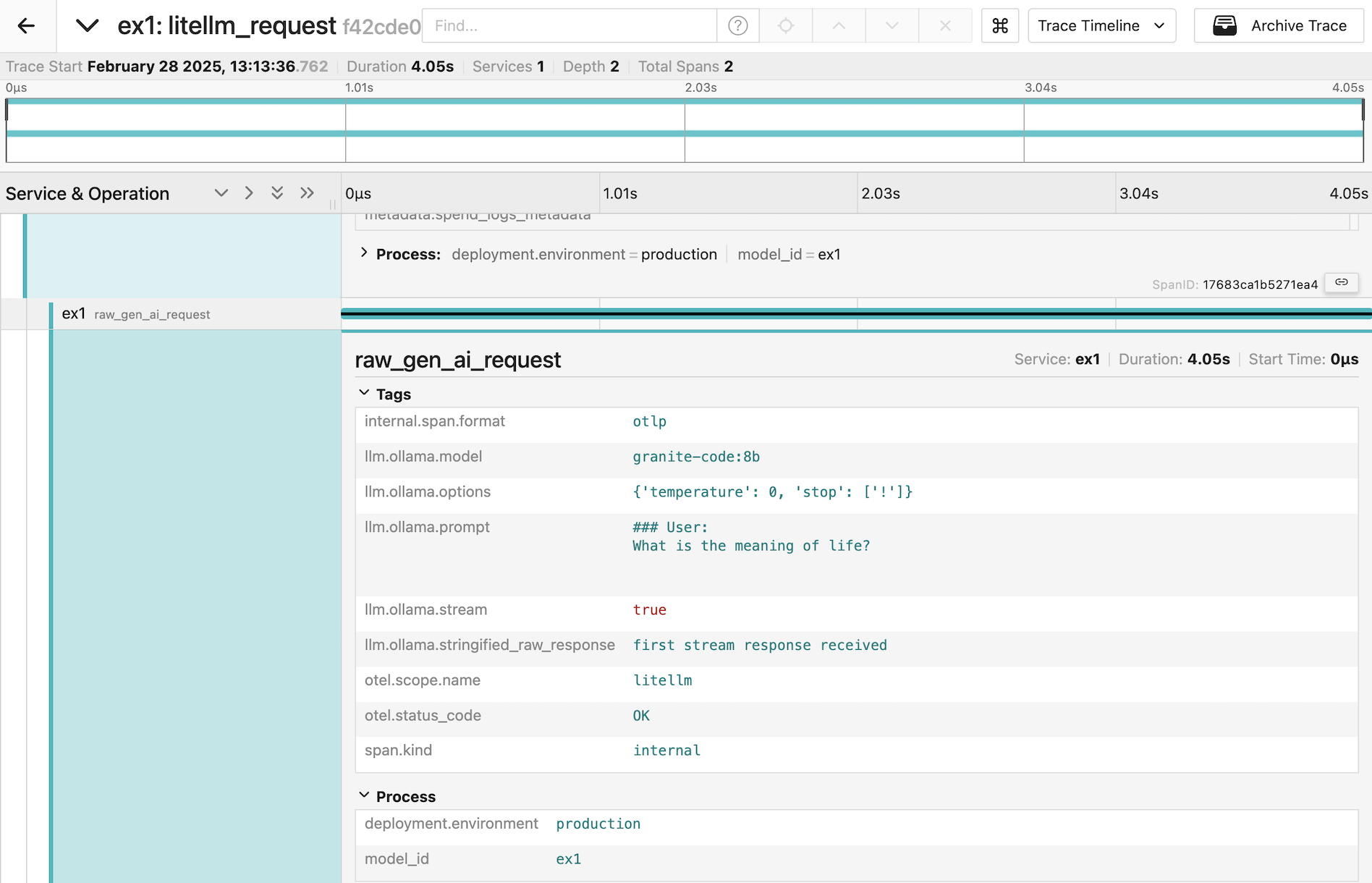
Trace Telemetry
PDL includes experimental support for gathering trace telemetry. This can be used for debugging or performance analysis, and to see the shape of prompts sent by LiteLLM to models.
For more information see here.
Best Practices
-
Template Organization:
- Keep templates modular and reusable
- Use variables for dynamic content
- Document template purpose and requirements
-
Error Handling:
- Validate model inputs/outputs
- Include fallback logic
- Log intermediate results
-
Performance:
- Cache frequent LLM calls
- Use appropriate temperature settings
- Implement retry logic for API calls
-
Security:
- Enabling sandbox mode for untrusted code
- Validate all inputs
- Follow API key best practices
Additional Notes
When using Granite models, we use the following defaults for model parameters:
temperature: 0max_new_tokens: 1024min_new_tokens: 1repetition_penalty: 1.05
Also if the decoding_method is sample (for watsonx_text text completion endpoint on watsonx), then the following defaults are used:
temperature: 0.7top_p: 0.85top_k: 50
For a complete list of issues see here.
Contributing to the Project
See Contributing to PDL.