Logical Neural Networks ¶
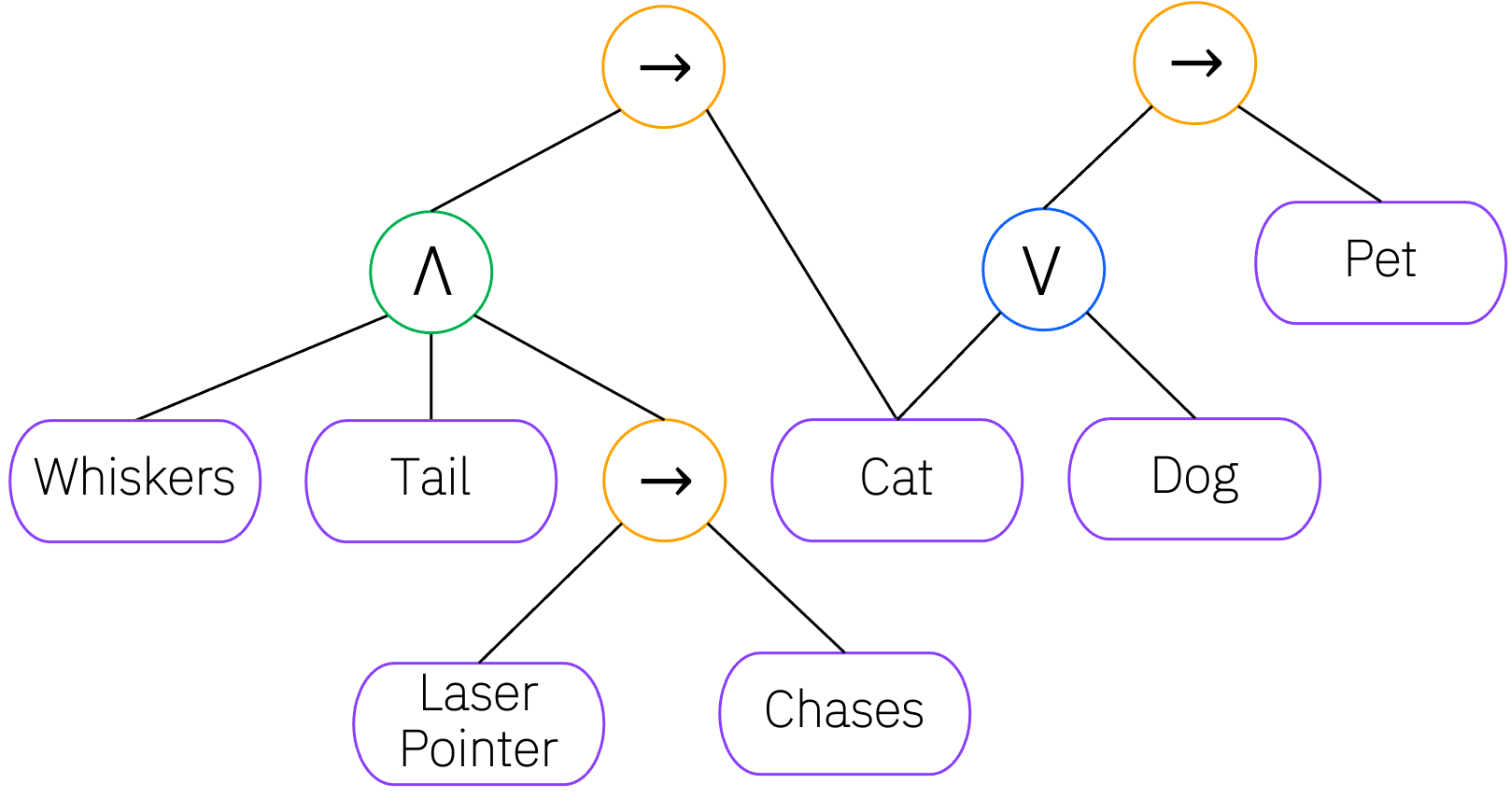
The LNN is a form of recurrent neural network with a 1-to-1 correspondence to a set of logical formulae in any of various systems of weighted, real-valued logic , in which evaluation performs logical inference. The graph structure therefore directly reflects the logical formulae it represents.
Key innovations that set LNNs aside from other neural networks are
-
neural activation functions constrained to implement the truth functions of the logical operations they represent, i.e.
And,Or,Not,Implies, and, in FOL,ForallandExists, -
results expressed in terms of bounds on truth values so as to distinguish known, approximately known, unknown, and contradictory states,
-
bidirectional inference permitting, e.g.,
x → yto be evaluated as usual in addition to being able to proveygivenxor, just as well,~xgiven~y.
The nature of the modeled system of logic depends on the family of activation functions chosen for the network’s neurons, which implement the logic’s various atoms (i.e. propositions or predicates) and operations.
In particular, it is possible to constrain the network to behave exactly classically when provided classical input. Computation is characterized by tightening bounds on truth values at neurons pertaining to subformulae in upward and downward passes over the represented formulae’s syntax trees.
Bounds tightening is monotonic; accordingly, computation cannot oscillate and necessarily converges for propositional logic. Because of the network’s modular construction, it is possible to partition and/or compose networks, inject formulae serving as logical constraints or queries, and control which parts of the network (or individual neurons) are trained or evaluated.
Inputs are initial truth value bounds for each of the neurons in the network; in particular, neurons pertaining to predicate atoms may be populated with truth values taken from KB data. Additional inputs may take the form of injected formulae representing a query or specific inference problem.
Outputs are typically the final computed truth value bounds at one or more neurons pertaining to specific atoms or formulae of interest.
In other problem contexts, the outputs of interest may instead be the neural parameters themselves — serving as a form of inductive logic programming (ILP) — after learning with a given loss function and input training data set.