Tune Experiment run#
The TuneExperiment class is responsible for creating experiments and scheduling tunings. All experiment results are stored automatically in the user-specified Cloud Object Storage (COS) for SaaS or in cluster’s file system in case of Cloud Pak for Data. Then, the TuneExperiment feature can fetch the results and provide them directly to the user for further usage.
Configure PromptTuner#
For an TuneExperiment object initialization authentication credentials (examples available in section: Setup) and one of project_id or space_id are used.
Hint
You can copy the project_id from Project’s Manage tab (Project -> Manage -> General -> Details).
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes
from ibm_watson_machine_learning.experiment import TuneExperiment
experiment = TuneExperiment(credentials,
project_id="7ac03029-8bdd-4d5f-a561-2c4fd1e40705"
)
prompt_tuner = experiment.prompt_tuner(
name="prompt tuning name",
task_id=experiment.Tasks.CLASSIFICATION,
base_model=ModelTypes.FLAN_T5_XL,
accumulate_steps=32,
batch_size=16,
learning_rate=0.2,
max_input_tokens=256,
max_output_tokens=2,
num_epochs=6,
tuning_type=experiment.PromptTuningTypes.PT,
verbalizer="Extract the satisfaction from the comment. Return simple '1' for satisfied customer or '0' for unsatisfied. Input: {{input}} Output: ",
auto_update_model=True
)
Get configuration parameters#
To see current configuration parameters, call the get_params() method.
config_parameters = prompt_tuner.get_params()
print(config_parameters)
{
'base_model': {'model_id': 'google/flan-t5-xl'},
'accumulate_steps': 32,
'batch_size': 16,
'learning_rate': 0.2,
'max_input_tokens': 256,
'max_output_tokens': 2,
'num_epochs': 6,
'task_id': 'classification',
'tuning_type': 'prompt_tuning',
'verbalizer': "Extract the satisfaction from the comment. Return simple '1' for satisfied customer or '0' for unsatisfied. Input: {{input}} Output: ",
'name': 'prompt tuning name',
'description': 'Prompt tuning with SDK',
'auto_update_model': True
}
Run prompt tuning#
To schedule an tuning experiment, call the run() method (this will trigger a training process). The run() method can be synchronous (background_mode=False), or asynchronous (background_mode=True).
If you don’t want to wait for training to end, invoke the async version. It immediately returns only run details.
from ibm_watson_machine_learning.helpers import DataConnection, ContainerLocation
tuning_details = prompt_tuner.run(
training_data_connection=[DataConnection(
connection_asset_id=connection_id,
location=S3Location(
bucket='prompt_tuning_data',
path='pt_train_data.json')
)
)]
background_mode=False)
# OR
tuning_details = prompt_tuner.run(
training_data_connection=[DataConnection(
data_asset_id='5d99c11a-2060-4ef6-83d5-dc593c6455e2')
]
background_mode=True)
# OR
tuning_details = prompt_tuner.run(
training_data_connection=[DataConnection(
location=ContainerLocation("path_to_file.json"))
]
background_mode=True)
Get run status, get run details#
If you use the run() method asynchronously, you can monitor the run details and status, using the following two methods:
status = prompt_tuner.get_run_status()
print(status)
'running'
# OR
'completed'
run_details = prompt_tuner.get_run_details()
print(run_details)
{
'metadata': {'created_at': '2023-10-12T12:01:40.662Z',
'description': 'Prompt tuning with SDK',
'id': 'b3bc33b3-cb3f-49e7-9fb3-88c6c4d4f8d7',
'modified_at': '2023-10-12T12:09:42.810Z',
'name': 'prompt tuning name',
'project_id': 'efa68764-5ec2-410a-bad9-982c502fbf4e',
'tags': ['prompt_tuning',
'wx_prompt_tune.3c06a0db-3cb9-478c-9421-eaf05276a1b7']},
'entity': {'auto_update_model': True,
'description': 'Prompt tuning with SDK',
'model_id': 'd854752e-76a7-4c6d-b7db-5f84dd11e827',
'name': 'prompt tuning name',
'project_id': 'efa68764-5ec2-410a-bad9-982c502fbf4e',
'prompt_tuning': {'accumulate_steps': 32,
'base_model': {'model_id': 'google/flan-t5-xl'},
'batch_size': 16,
'init_method': 'random',
'learning_rate': 0.2,
'max_input_tokens': 256,
'max_output_tokens': 2,
'num_epochs': 6,
'num_virtual_tokens': 100,
'task_id': 'classification',
'tuning_type': 'prompt_tuning',
'verbalizer': "Extract the satisfaction from the comment. Return simple '1' for satisfied customer or '0' for unsatisfied. Input: {{input}} Output: "},
'results_reference': {'connection': {},
'location': {'path': 'default_tuning_output',
'training': 'default_tuning_output/b3bc33b3-cb3f-49e7-9fb3-88c6c4d4f8d7',
'training_status': 'default_tuning_output/b3bc33b3-cb3f-49e7-9fb3-88c6c4d4f8d7/training-status.json',
'model_request_path': 'default_tuning_output/b3bc33b3-cb3f-49e7-9fb3-88c6c4d4f8d7/assets/b3bc33b3-cb3f-49e7-9fb3-88c6c4d4f8d7/resources/wml_model/request.json',
'assets_path': 'default_tuning_output/b3bc33b3-cb3f-49e7-9fb3-88c6c4d4f8d7/assets'},
'type': 'container'},
'status': {'completed_at': '2023-10-12T12:09:42.769Z', 'state': 'completed'},
'tags': ['prompt_tuning'],
'training_data_references': [{'connection': {},
'location': {'href': '/v2/assets/90258b10-5590-4d4c-be75-5eeeccf09076',
'id': '90258b10-5590-4d4c-be75-5eeeccf09076'},
'type': 'data_asset'}]}
}
Get data connections#
The data_connections list contains all training connections that you referenced while calling the run() method.
data_connections = prompt_tuner.get_data_connections()
# Get data in binary format
binary_data = data_connections[0].read(binary=True)
Summary#
It is possible to see details of models in a form of summary table. The output type is a pandas.DataFrame with model names, enhancements, base model, auto update option, the number of epochs used and last loss function value.
results = prompt_tuner.summary()
print(results)
# Enhancements Base model ... loss
# Model Name
# Prompt_tuned_M_1 [prompt_tuning] google/flan-t5-xl ... 0.449197
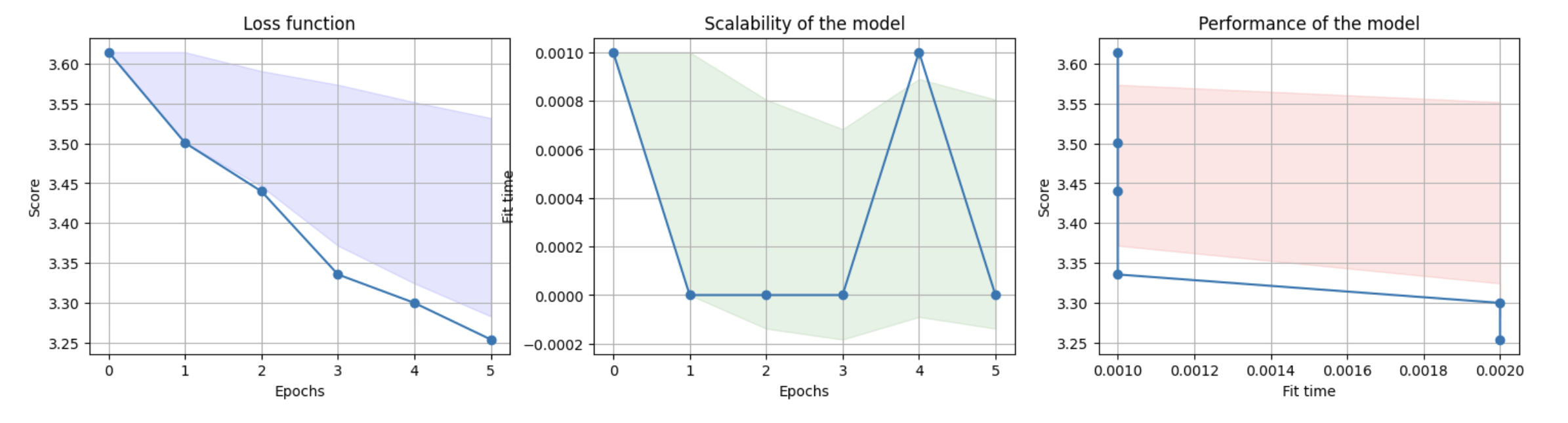
Plot learning curves#
Note
Available only for Jupyter notebooks.
To see graphically how tuning was performed, you can view learning curve graphs.
prompt_tuner.plot_learning_curve()
Get model identifier#
Note
It will be only available if the tuning was scheduled first and parameter auto_update_model was set as True (default value).
To get model_id call get_model_id method.
model_id = prompt_tuner.get_model_id()
print(model_id)
'd854752e-76a7-4c6d-b7db-5f84dd11e827'
The model_id obtained in this way can be used to create deployments and next create ModelInference.
For more information, see the next section: Tuned Model Inference.