Git for source code management
Why move to Git?
Git is the de facto industry standard source code manager (SCM) for the open source community and is growing in popularity among major organizations. It is a central part of the modern developer’s toolkit, and provides a common SCM tool for hybrid application architectures that can span across components ranging from those implemented in traditional mainframe languages such as COBOL, PL/I, or Assembler, to components for the service layer such as z/OS® Connect, and components in Java™ and Go, to reflect the architecture of the business application.
Git integrates with most modern DevOps tools and pipeline processes to support the full development lifecycle from continuous integration (CI) to continuous delivery (CD). By migrating to Git as the enterprise SCM, mainframe application development teams can then take advantage of the open source community's modern tooling.
Use a Git-based service
Choosing Git as the foundational tool presents some choices - Git's flexibility to be used in many different ways is a major reason why it is so widely adopted.
- Using just Git by itself allows developers on a shared system to collaborate at a very basic level using their own copies of the source code. This can work well for very small and informal projects and a few contributing developers (like Alice and Bob in the tutorial).
- Using Git and a patch-based workflow extends the collaboration to developers spread across different locations. This relies on a high level of trust and out-of-band communication between the contributors, as well as a strong leadership and governance process. It is how the Linux kernel continues to be maintained under the leadership of Git's inventor, Linus Torvalds.
- Git-based service providers such as GitHub, GitLab, and Azure DevOps include most of the additional capabilities enterprises need (for example, security, review processes, and governance) and are the most familiar to the overwhelming majority of developers today.
This guide is based on the use of a Git-based service provider. We strongly advise against choosing the "just Git" or "patch-based" styles of collaboration for mainframe teams. It may seem that these options could provide an entirely "z/OS-resident" solution, but they do not support the typical full set of needs for mainframe teams and development lifecycles, and they still demand adoption of and proficiency in additional z/OS facilities such as UNIX System Services.
Common Git provider options
Git basics
Git is a distributed "version control system" for source code. It provides many features to allow developers to check in and check out code with a full history and audit trail for all changes.
Source is stored in repositories (also known as "repos") on hierarchical file systems on Linux®, MacOS, Windows, or z/OS UNIX System Services.
The team stores a primary copy of the repository on a service running Git on a server (see Common Git provider options). Such services provide all the resilience required to safeguard the code and its history. Once source code is moved into a repository on the server, that becomes the primary source of truth, so existing processes to ensure the resilience of copies on z/OS are no longer required.
An application repo can be cloned from the team's chosen Git server (known as the "remote") to any machine that has Git, including a developer's local computer using popular integrated development environments (IDEs) such as IBM® Developer for z/OS (IDz) and Microsoft’s Visual Studio Code (VS Code). By default, clones contain all the files and folders in the repository, as well as their complete version histories. (Cloning provides many options to select what is copied and synchronized.)
All Git operations that transfer the data held in the repository (clone, push, fetch, and pull) use SSH or HTTPS secure communications. Pros and cons of each protocol are discussed in "Git on the Server - The Protocols".
z/OS UNIX System Services includes OpenSSH. z/OS OpenSSH provides the following z/OS extensions:
- System Authorization Facility (SAF) key ring: z/OS OpenSSH can be configured to allow z/OS OpenSSH keys to be stored in SAF key rings.
- Multilevel security: This is a security policy that allows the classification of data and users based on a system of hierarchical security levels combined with a system of non-hierarchical security categories.
- System Management Facility (SMF): z/OS OpenSSH can be configured to collect SMF Type 119 records for both the client and the server.
- Hardware Cryptographic Support: OpenSSH can be configured to choose Integrated Cryptographic Service Facility (ICSF) callable service for implementing the applicable SSH session ciphers and HMACs.
The developer can then create "branches" in the repository. Branches allow developers to make and commit changes to any files in the repository in isolation from other developers working in other branches, or for an individual developer to work on multiple work items that each have their own branch.
For each task the developer has (such as a bug fix or feature), the developer would generally do their development work on a branch dedicated to that task. When they are ready to promote their changes, they can create a "pull request", (also known as a "merge request") which is a request to integrate (or "merge") those changes back into the team's common, shared branch of code.
With Git’s branching and merging features, changes can be performed in isolation and in parallel with other developer changes. Git is typically hosted by service providers such as GitHub, GitLab, Bitbucket, or Azure Repos. Git providers add valuable features on top of the base Git functionality, such as repository hosting, data storage, and security.
In Git, all changes are committed (saved) in a repo using a commit hash (unique identifier) and a descriptive comment. Most IDEs provide a Git history tool to navigate changes and drill down to line-by-line details in Git diff reports. The following image of an Azure Repos example setup shows the Git history on the right panel, and a Git diff report on the left.
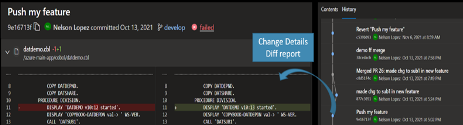
As part of comprehensive integrity assurance, developers can cryptographically sign their commits.
Git branching
A Git "branch" is a reference to all the files in a repo at a certain point in time, as well as their history. A normal practice is to create multiple branches in a repo, each for a different purpose. In the standard pattern (incorporated into our branching model for mainframe development) there will be a "main" branch, which is shared by the development team. The team's repository administrator(s) will usually set up protections for this branch, requiring approval for any change to be merged into it. The team might also have additional shared branches for different purposes, depending on their branching strategy. The repository administrator(s) can also set up branch protections for these branches, as well as any other branch in the repository.
Do not think of branches being aligned to deployment targets (such as test or production environments). For more on this see No environment branches in our recommended branching model.
All Git actions are performed on a branch, and a key advantage of Git is that it allows developers to clone a repo and create (check out) a new branch (sometimes called a "feature branch") to work on their own changes in isolation from the main source branch. This lets each developer focus on their task without having to worry about other developers' activities disturbing their work or vice versa.
When a developer wants to save their code changes onto a branch in Git, they perform a Git "commit", which creates a snapshot of the branch with their changes. Git uniquely identifies this snapshot with a commit hash, and attaches a short commit message from the developer describing the changes. The developer (and any other teammates with access to the branch) can then use this commit hash as a point-in-time reference for the set of committed changes. They can later check out the commit hash to view the code at that commit point. Additionally, the code can also be rolled back (or "reverted", in Git terminology) to any prior commit hash.
Git merge
Feature branching allows developers to work on the same code, and work in parallel and in isolation. Git merge is how all the code changes from one branch get integrated into another branch. Once developers complete their feature development, they initiate a pull request asking to integrate their feature changes into the team's shared branch of code.
The pull request process is where development teams can implement peer reviews, allowing team leads or other developers to approve or reject changes. They can also set up other quality gates such as automated testing and code scanning to run on the PR. Git will automatically perform merge conflict detection to prevent the accidental overlaying of changes when the pull request is merged in. Development teams often have a CI pipeline that is triggered to run upon pull request approval/merge for the integration test phase.
Merge conflict detection: parallel development use case
One of the biggest benefits of using Git is its merge conflict detection. This is Git's ability to detect when there are overlaps in the code changes during a merge process, so that developers can stop the merge and resolve the merge conflict. This merge conflict detection means that team members can merge their changes to the same program while avoiding unintentionally overlaying each other’s code.
To illustrate this example of parallel development, in the following diagram, Developer 1 (Dev1) and Developer 2 (Dev2) have each created their own feature branch from the same version of their team's shared branch of code. Note that there are no commits (indicated by purple dots) on the team's shared branch between when Dev2 and Dev1 created their respective feature branches. Now, each developer can work on their own feature in isolation: Dev1 has his feature1 branch where he is working on his copy of the code, and Dev2 has her feature2 branch where she is working on her copy of the code.
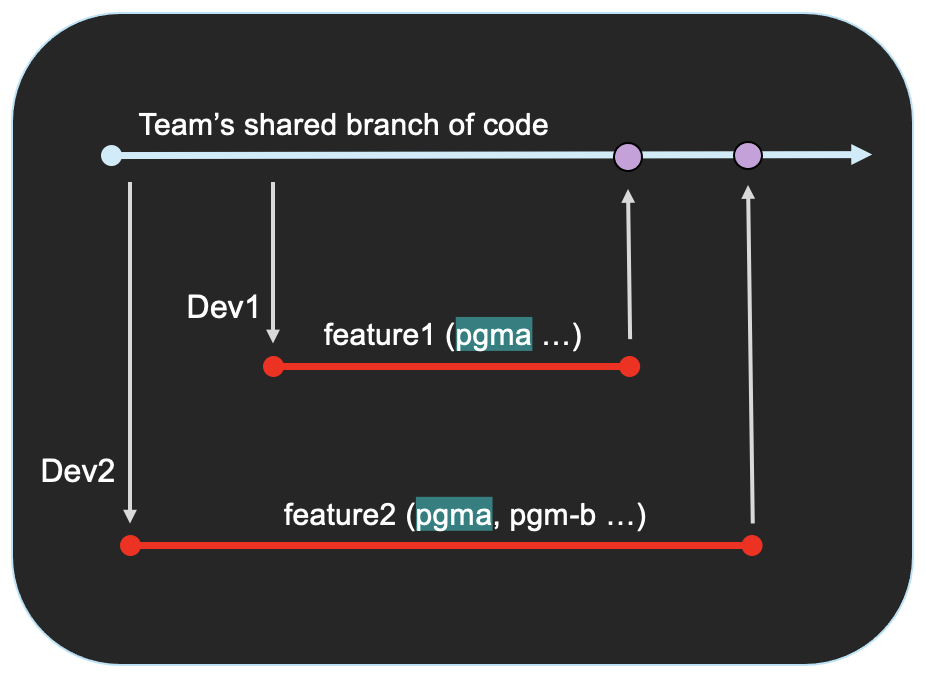
Doing this kind of parallel development is complicated on legacy systems, especially with PDSs, because developers have to figure out how to merge the code at the end, especially when working on the same files. Additionally, legacy SCMs typically lock files that are being worked on. In contrast, Git branching allows the developers to work on the files at the same time, in parallel.
In the Git example illustrated above, Dev1 and Dev2 agreed to work on different parts of the same program, and they then each make their own pull request to integrate their respective changes back into the team's shared branch of code when they are ready. Dev1 has done this before Dev2, so his changes have been approved and merged in first. When Dev2 later makes her request to merge her code changes into the team's shared branch of code, Git does a line-by-line check to make sure the changes proposed in Dev2's pull request do not conflict with any of the changes in the shared branch of code (which now include Dev1's changes). If any issues are found, Git will stop the merge and alert the developers of the merge conflict. Git will also highlight the conflicting code so that the developers know where to look and can resolve the conflict, most likely via another commit in Dev2's branch.
Git tags
A Git tag references the repo with a specific, unique commit point. Tags are optional but are strongly recommended and broadly used in modern development practices with Git.
Forking repositories
Repositories can also be forked. A fork is a more independent copy of the original repo created on the remote Git service either in a different organization or under an individual's account. The original repo from which a fork is created is commonly known as the upstream repository. A project can impose a restriction to stop forks being created.
As an independent copy, it has its own branches (including main). Forks have an association with the original repo, and pull requests can be made from forks to their originating repos.
Forks are most commonly used as part of an open source project's workflow as they allow contributors to work without them needing to be granted update permission to the project's main repository (which
would be required if they worked via a clone and used git push to synchronize). With their own fork, they can work on branches in the fork and then ask someone with commiting authority to
the project's repository to merge from the fork into the upstream repository.
Branch protection rules are usually more appropriate in an enterprise development team to control who can merge commits to important branches. Using forks will limit cross-team visibility of all the work that is in-flight.
Git workflow by role
To begin using the software development lifecycle with Git for an existing z/OS application, the source of the application must already be located in a Git repository. For information on how to migrate source files from z/OS to Git, see Migrating data from z/OS to Git.
Once the source code of the application is in a Git repository, the workflow involves tasks that use Git capabilities such as cloning, pulling, branching, committing, pushing, and merging.
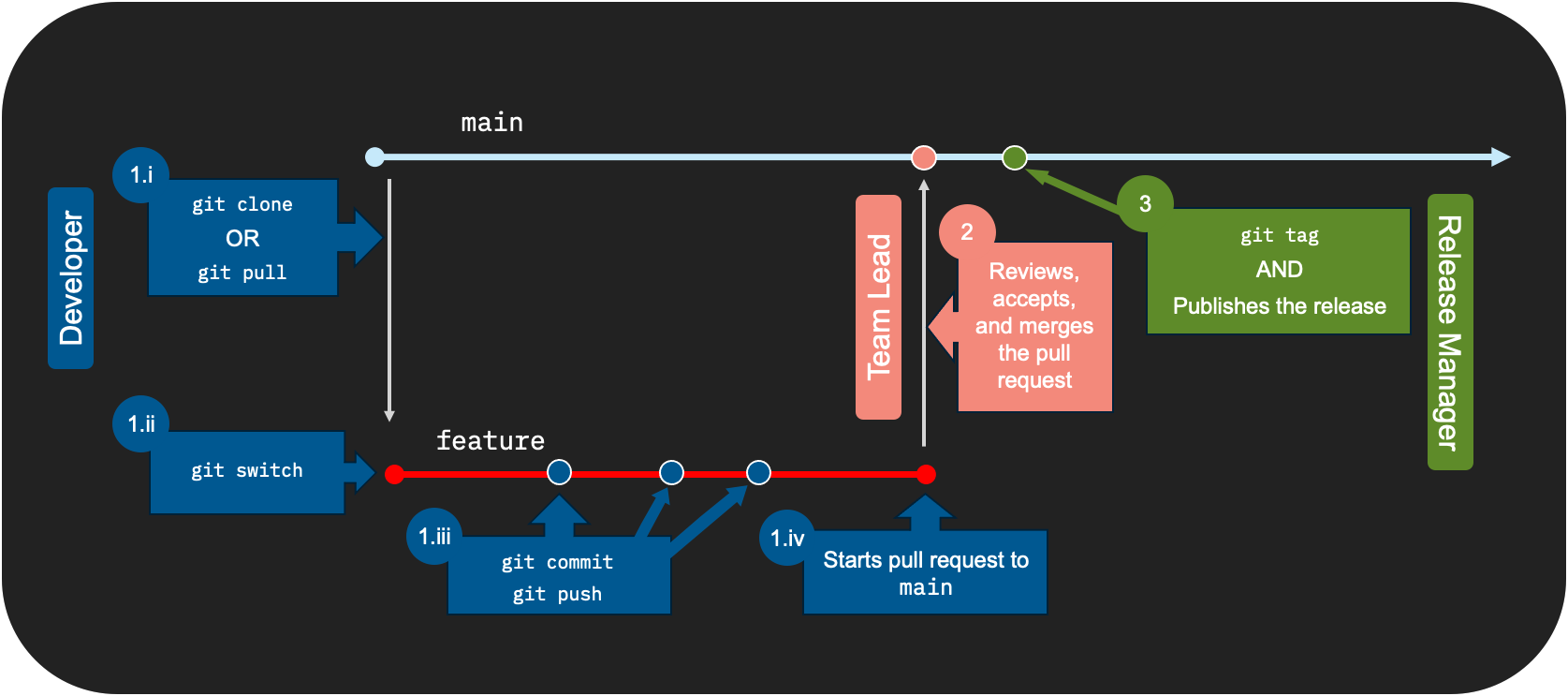
The following diagram summarizes the Git workflow by role at a high level.
Note:
The commands mentioned in this section are high-level commands to provide an overall idea of the workflow, and may omit arguments or use sample arguments (enclosed in angle brackets; for example, <sample-argument>) for clarity.
-
Developing new features or bug fixes: Upon receiving a new assignment, a developer performs the following tasks:
-
Clones or pulls the latest source files from the central Git repository to their local repository using the following commands:
-
If cloning the repository for the first time:
git clone <repo-url> -
If working on an existing cloned repository:
git pull
-
-
Works on their code changes using a dedicated feature branch, which can be created using the following command:
git switch -c <feature> -
Commits and pushes the changes to their feature branch on the central Git repository using the following commands:
git commit
git pushWhen using the
git commitcommand, adding a descriptive, concise commit message with the-m <'msg'>option can help the both the developer and their team understand the changes in the commit when reviewing the code. -
Starts the merge workflow from their feature branch to the
mainbranch.It is recommended to create a peer review request (for example, a pull request or a merge request) during this stage.
-
-
Reviewing the peer review request: The development team or the team lead reviews the request. The request is either approved and merged, or rejected.
-
Publishing the release: The release manager creates the release from the
mainbranch. The release can be created via a Git provider, or by using the command line.With the command line approach, the following command can be used:
git tag -a <version> -m <'msg'>Publishing the release is done by the release manager or the development team lead.
Sharing code
It is a common practice that mainframe applications share common code. For example, COBOL copybooks are typically shared across applications that process similar data.
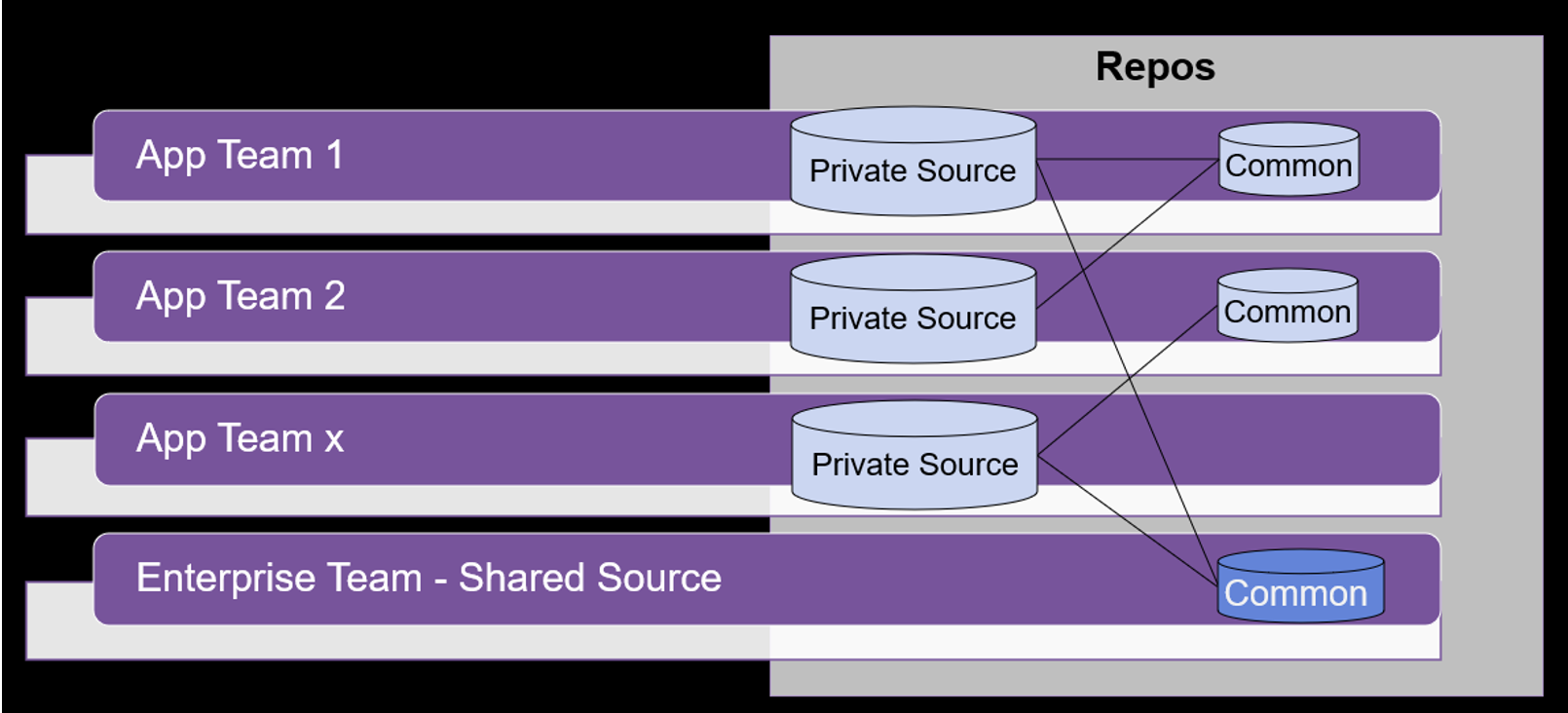
The following diagram illustrates how teams can define repos to securely share common code. In this example, App Team 1 has common code that App Team 2 can clone and use in their build.
Another example (also illustrated in the following diagram) is that an enterprise-wide team can maintain source that is common across many applications.
Examples of how the z/OS application developer, team lead, and release manager can use Git and other DevOps tools in the larger context of a CI/CD pipeline are outlined in Role-based usage. See Git branching model for mainframe development for detailed guidance on our recommended Git branching model and working practices.
Resources
This page contains reformatted and updated excerpts from Git training for Mainframers.