Lab 1: Introduction to DataStage¶
DataStage Flow Designer enables users to create, edit, load, and run DataStage jobs which can be used to perform integration of data from various sources in order to glean meaningful and valuable information.
The purpose of this lab is to familiarize ourselves with the DataStage Flow Designer and the Operations Console.
In this lab, you will learn the following:
- How to create a job in DataStage.
- How to read tabular data from a file into DataStage.
- How to perform transformations (such as filtering out records and removing duplicate values) on a table.
- How to write tabular data from DataStage into a file.
- How to run jobs.
- How to view logs for jobs.
- How to schedule jobs.
This lab is comprised of the following steps:
- Create a Transformation project
- Create the table definition
- Create the job
- Compile and run the job
- Use Operations Console to view previous logs
- Scheduling the job
- View output
Before you start¶
Before we start the lab, let's switch to the iis-client VM and launch Firefox.
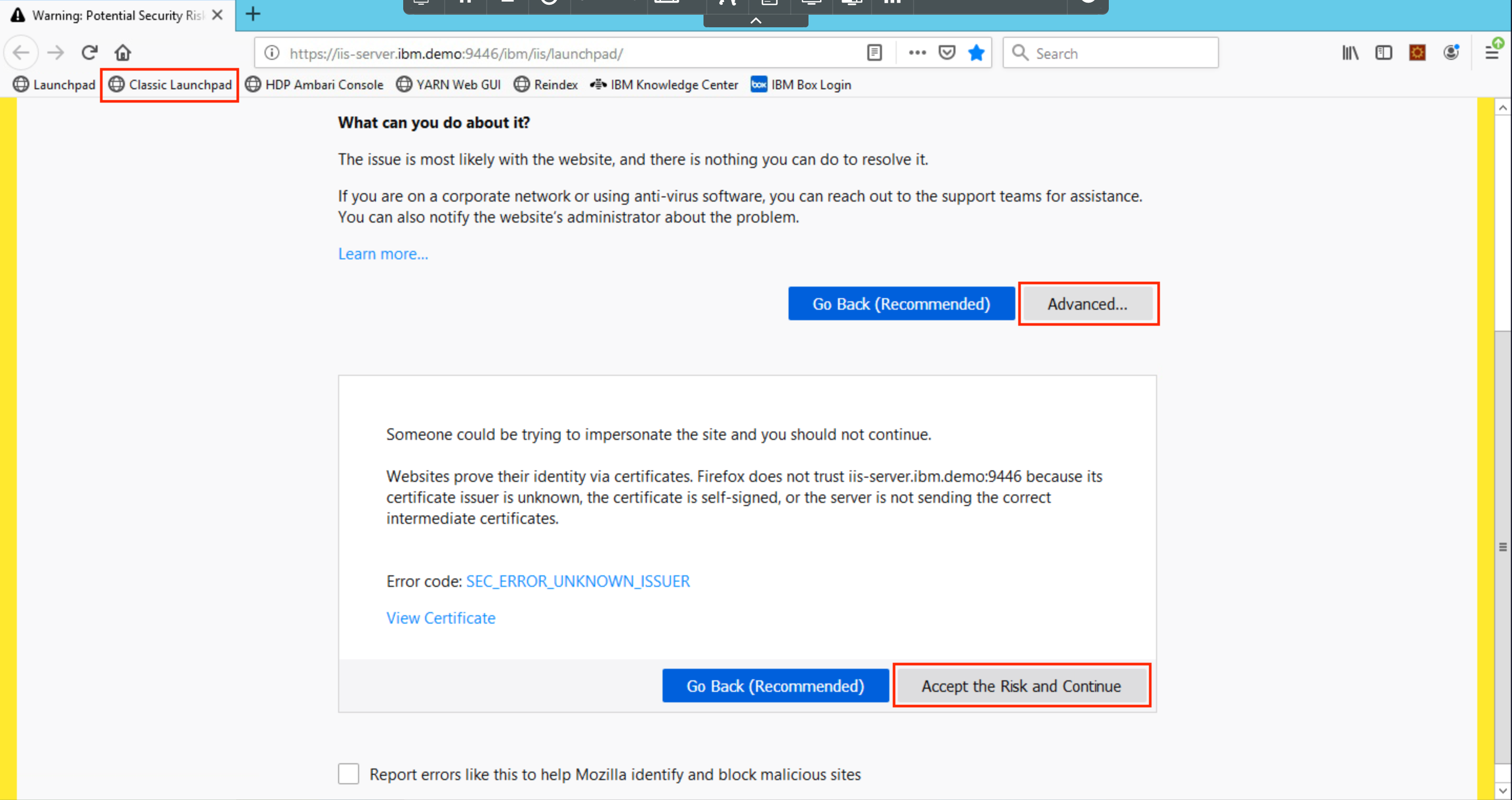
Click on Classic Launchpad in the Bookmarks tab. The first time you try this out, you might see a certificate error. To get past it, click on Advanced... and then click Accept the Risk and Continue.
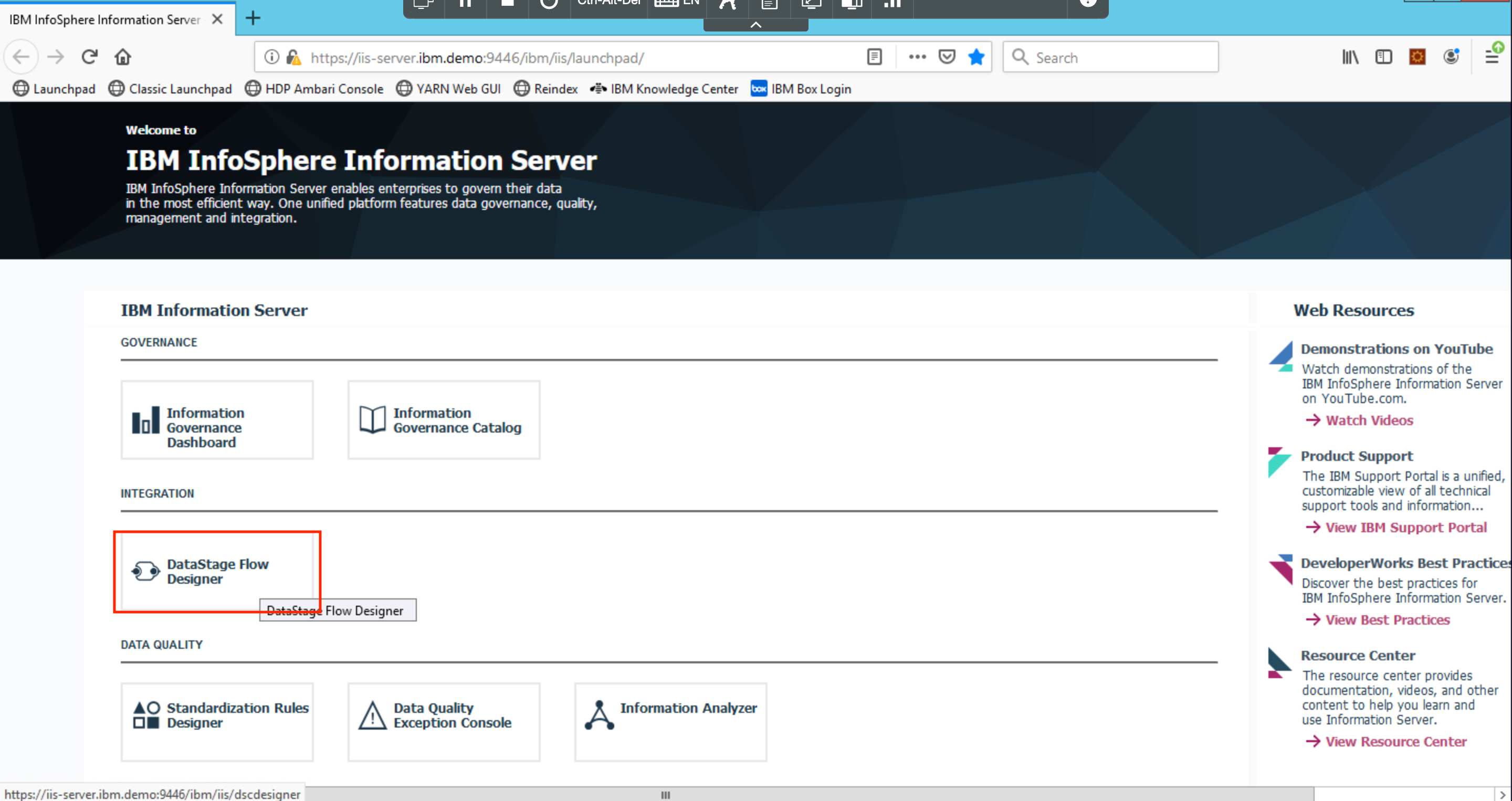
Click on DataStage Flow Designer.
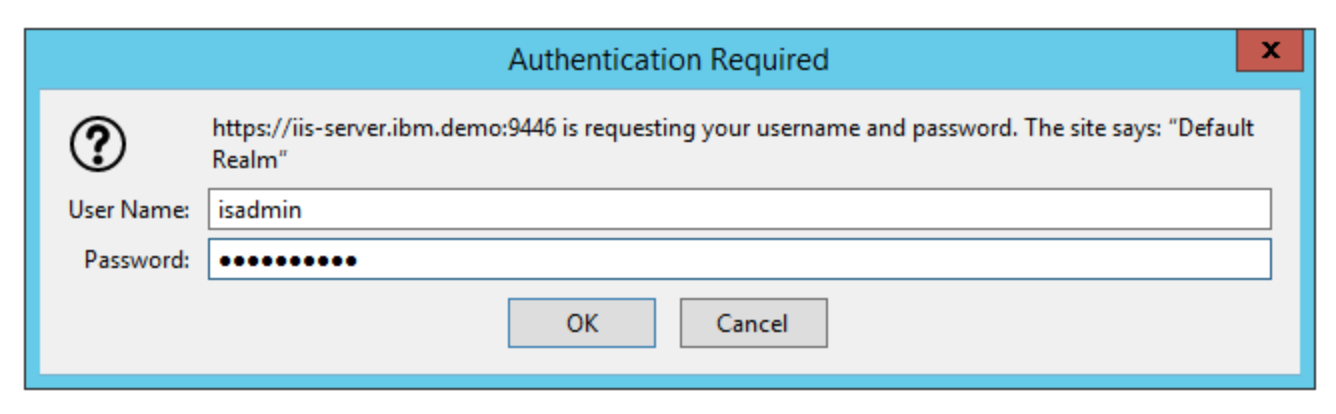
Login with the credentials isadmin/inf0Xerver.
This brings up the DataStage Flow Designer. Click OK.
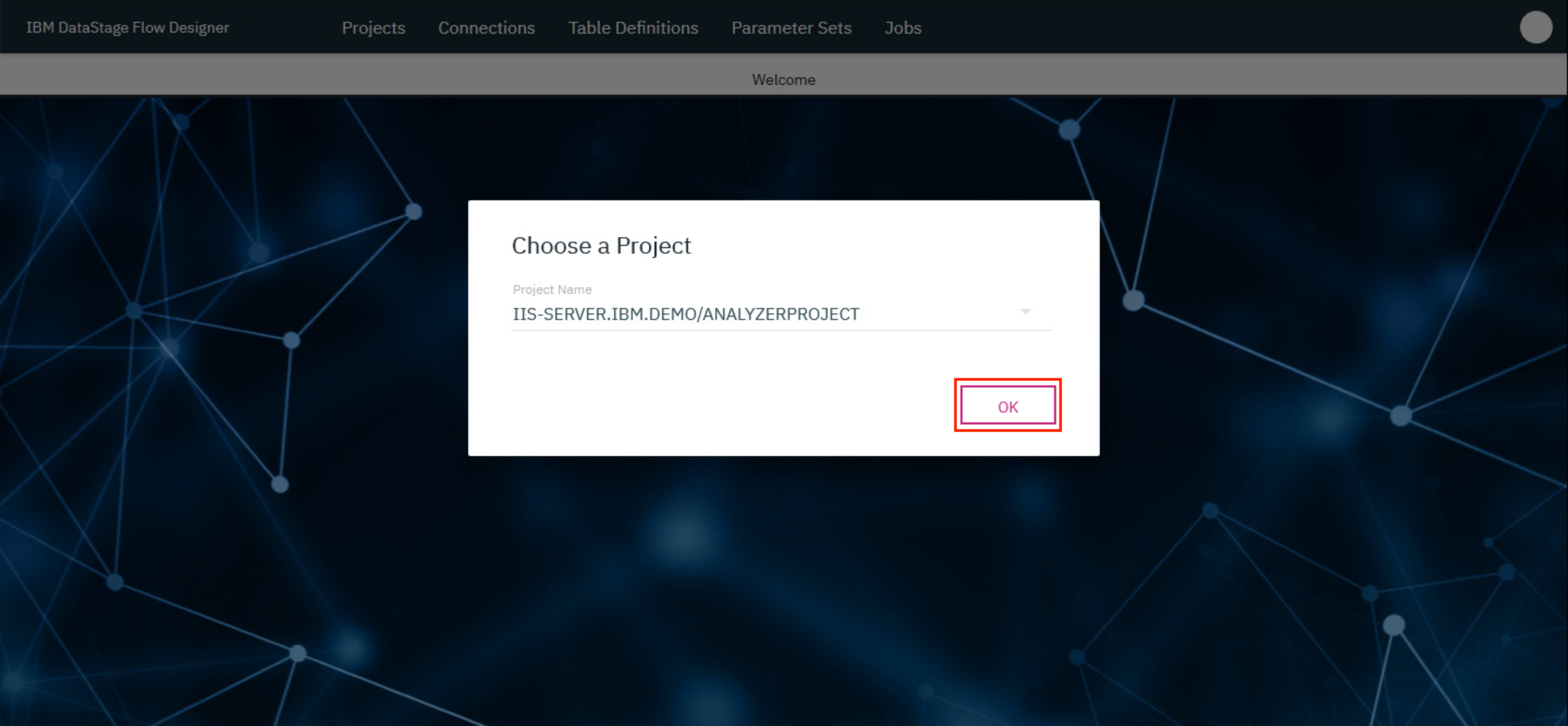
1. Create a Transformation project¶
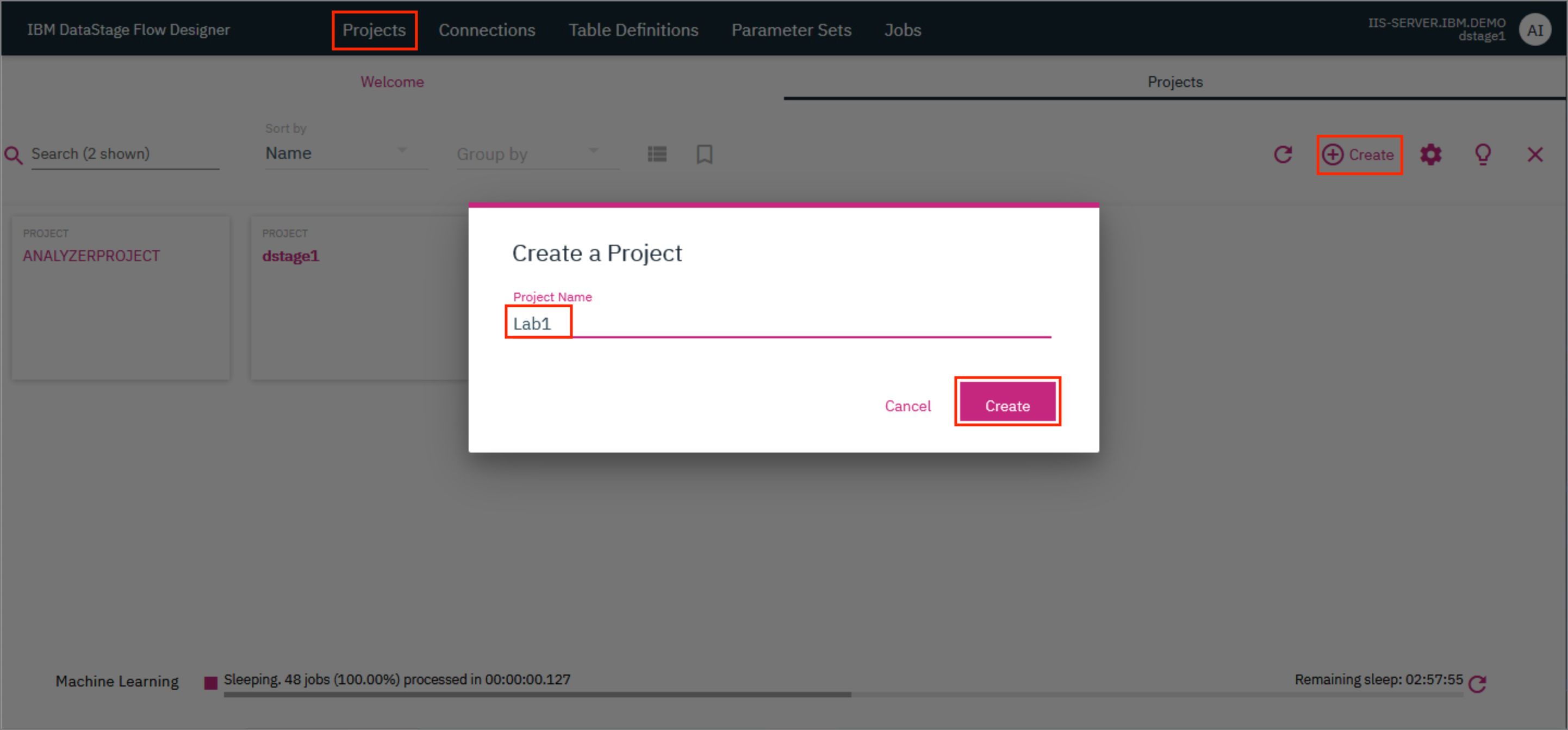
- On the IBM DataStage Flow Designer, click on the
Projectstab and click+ Create. In the modal that opens up, type in a name for the project and clickCreate.
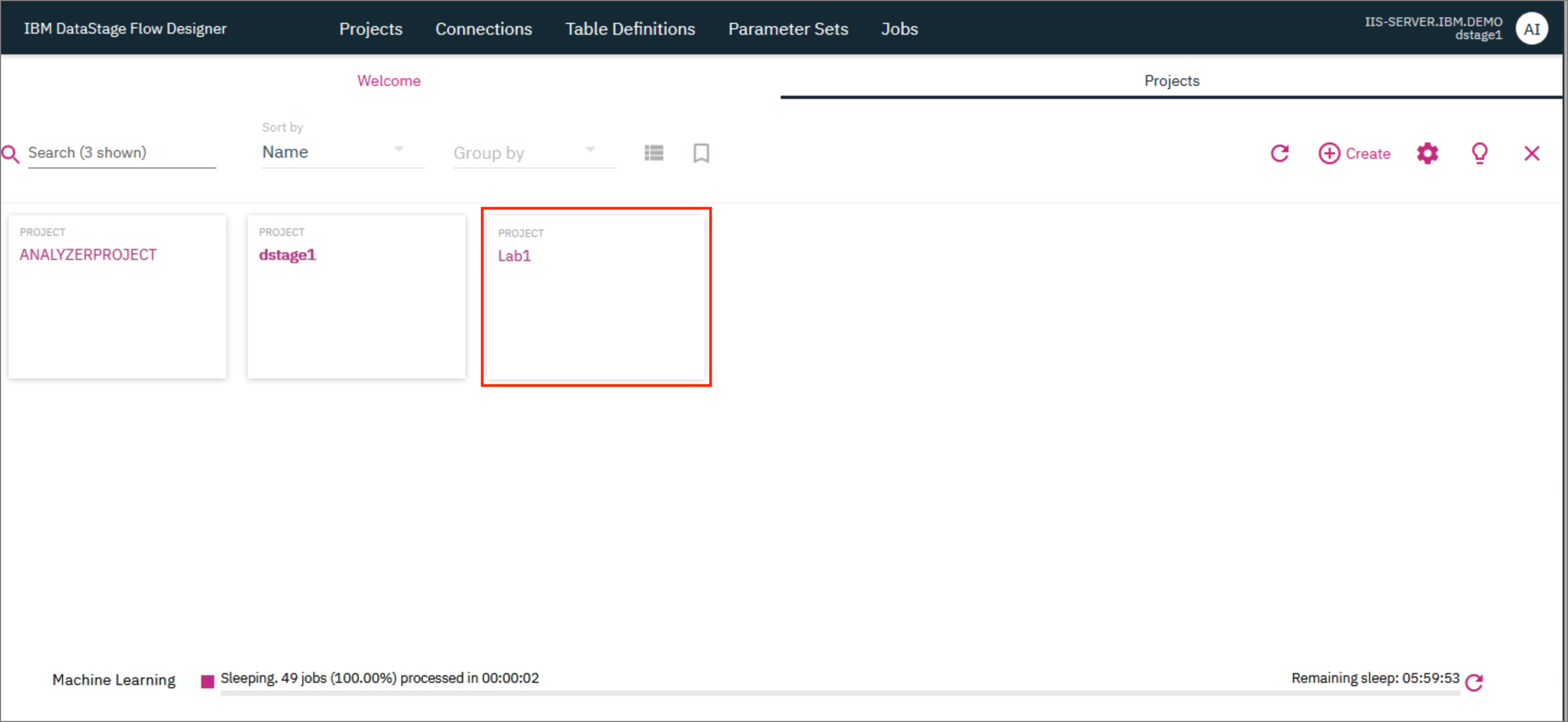
The project takes a few minutes to be created and once ready, it will be visible on the Projects tab.
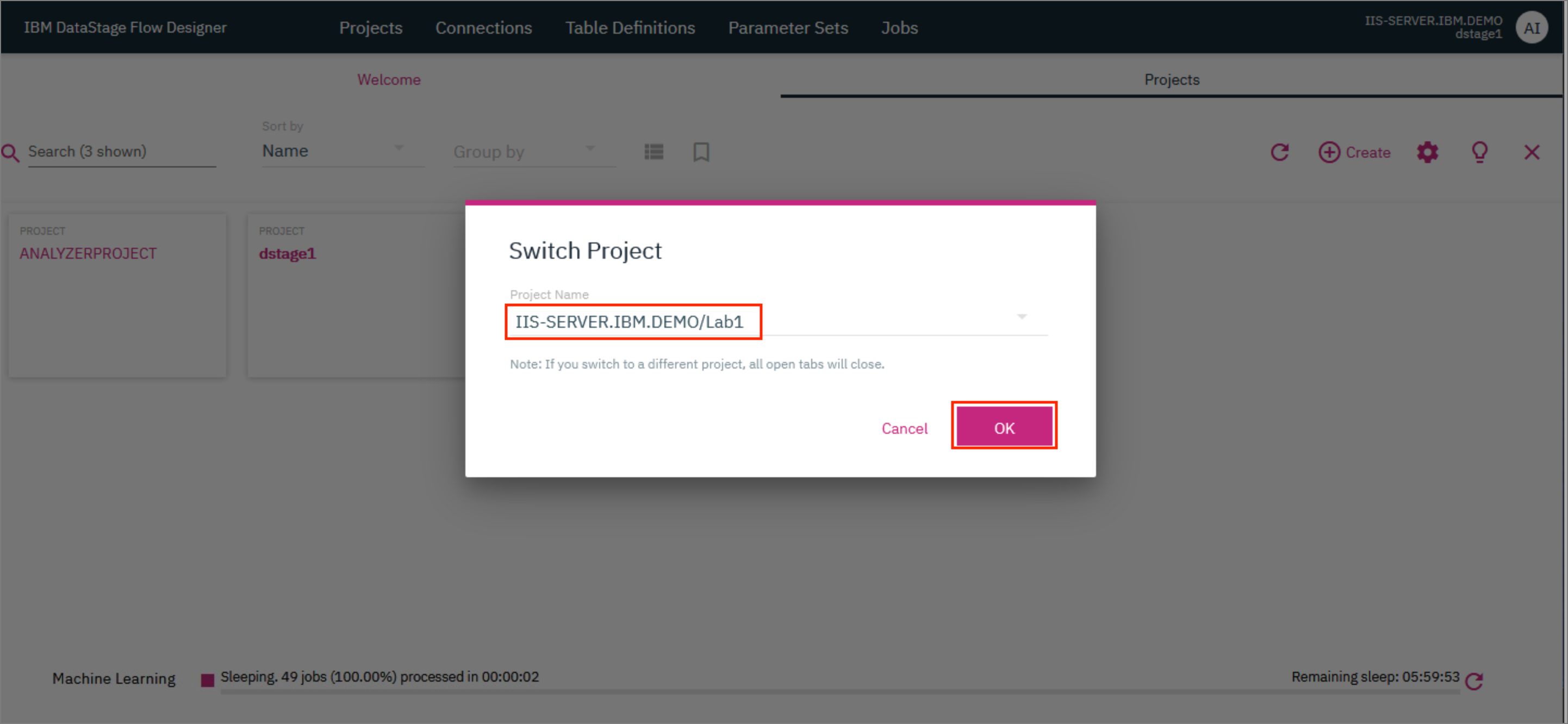
- Click on the tile for your newly created project. In the modal that opens up, verify that the name of your project is provided as the
Project Nameand clickOKto switch the project.
2. Create the table definition¶
We will be using the raviga-products.csv file which contains tabular data having 2 columns:
| Column Name | Data Type |
|---|---|
| ProductID | varchar(9) |
| Zip | Integer(6) |
- On the DataStage Flow Designer, click on the
Table Definitionstab and then click+ Create. In the modal that opens up, provide the definition of the table contained in the input file. Go to theGeneraltab and provide the Data source type asFile, the Data source name asravigaand the Table/File name asravigaproducts. If you wish to, you can also provide optional Short description and Long description.
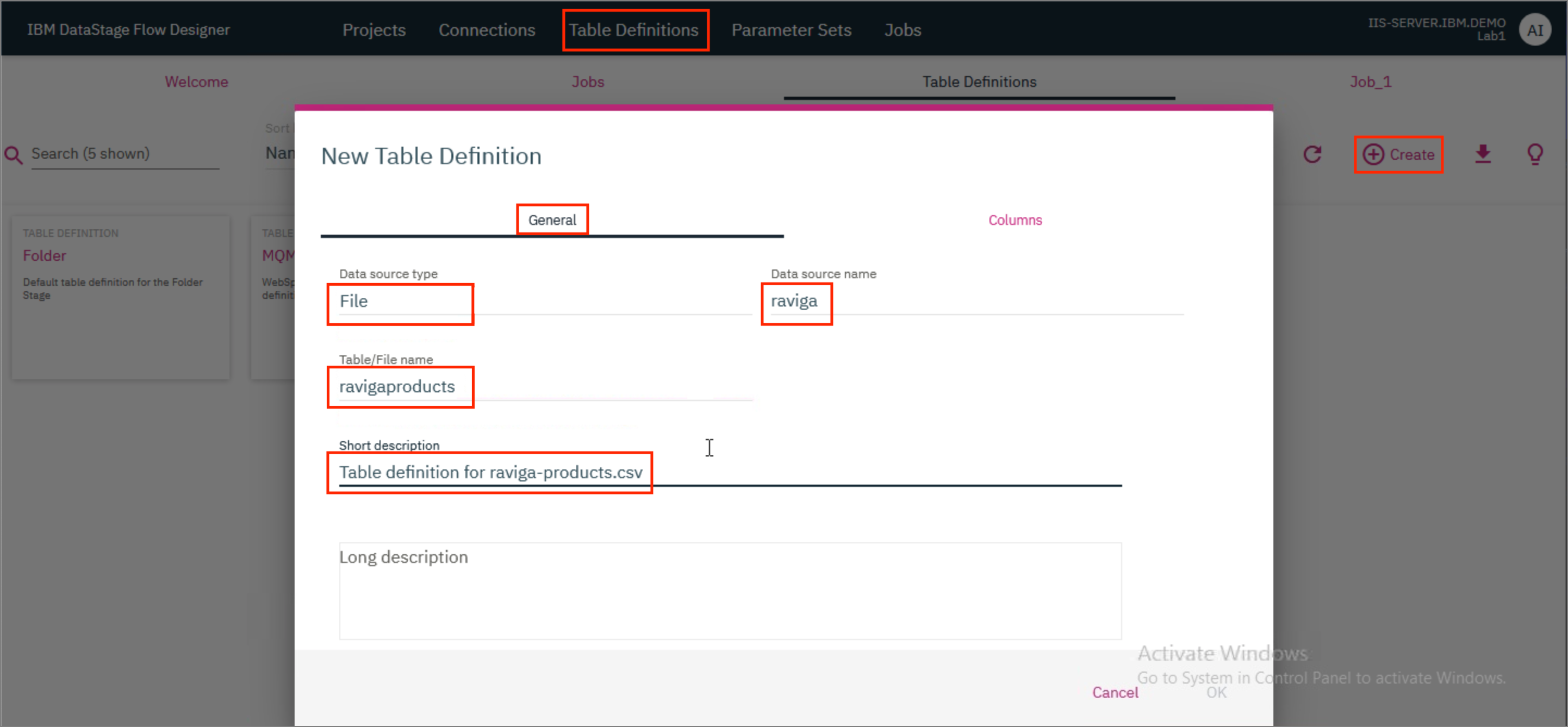
-
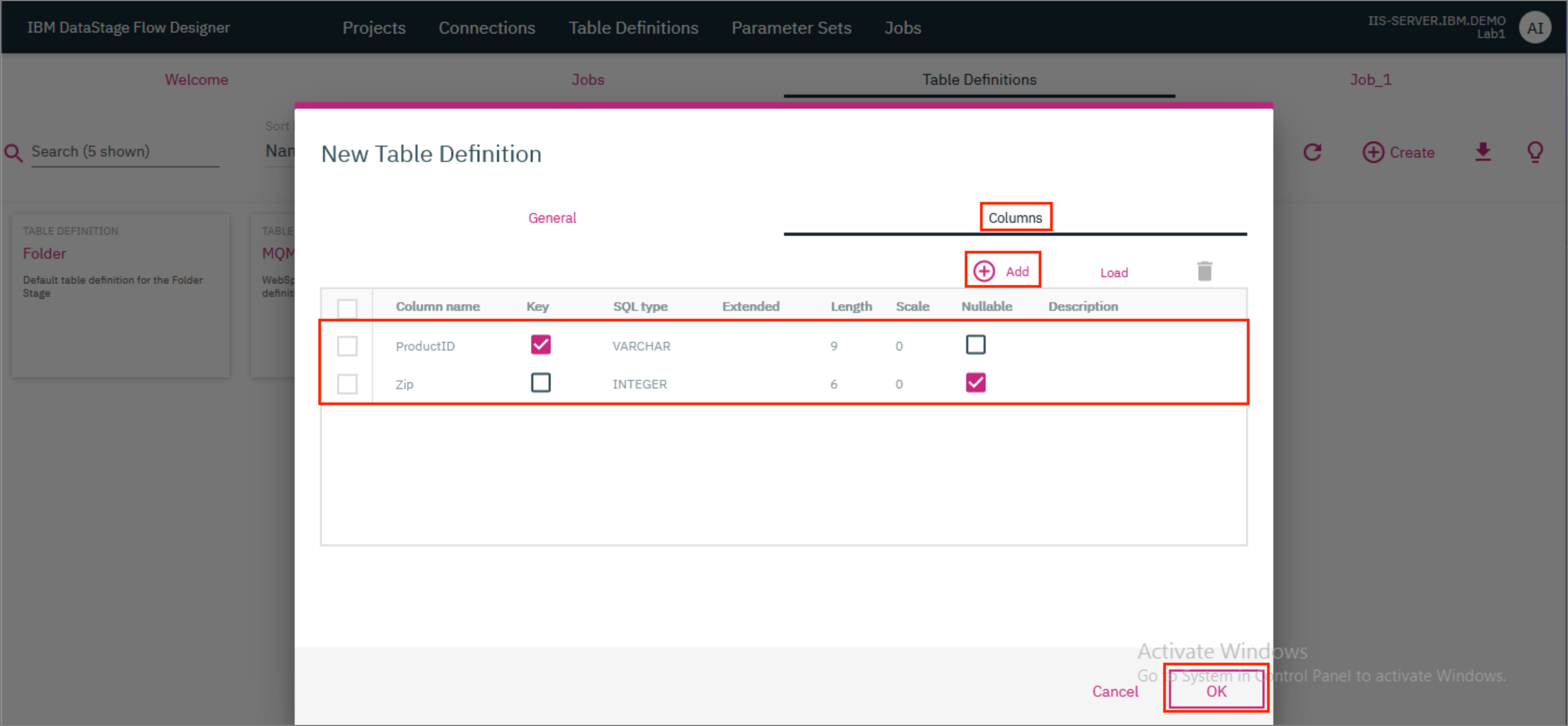
Next, go to the
Columnstab and click+ Add. A new entry is added in the table. Edit the entry and update the Column name toProductID. Mark the column as Key. Update the SQL type toVarcharand the Length to9. -
Click on
+ Addto add another entry in the table. Edit this entry and update the Column name toZip, SQL type toInteger, Extended to"" (blank)and Length to6. Mark the column as Nullable. ClickOK. In the modal that pops up, clickSave.
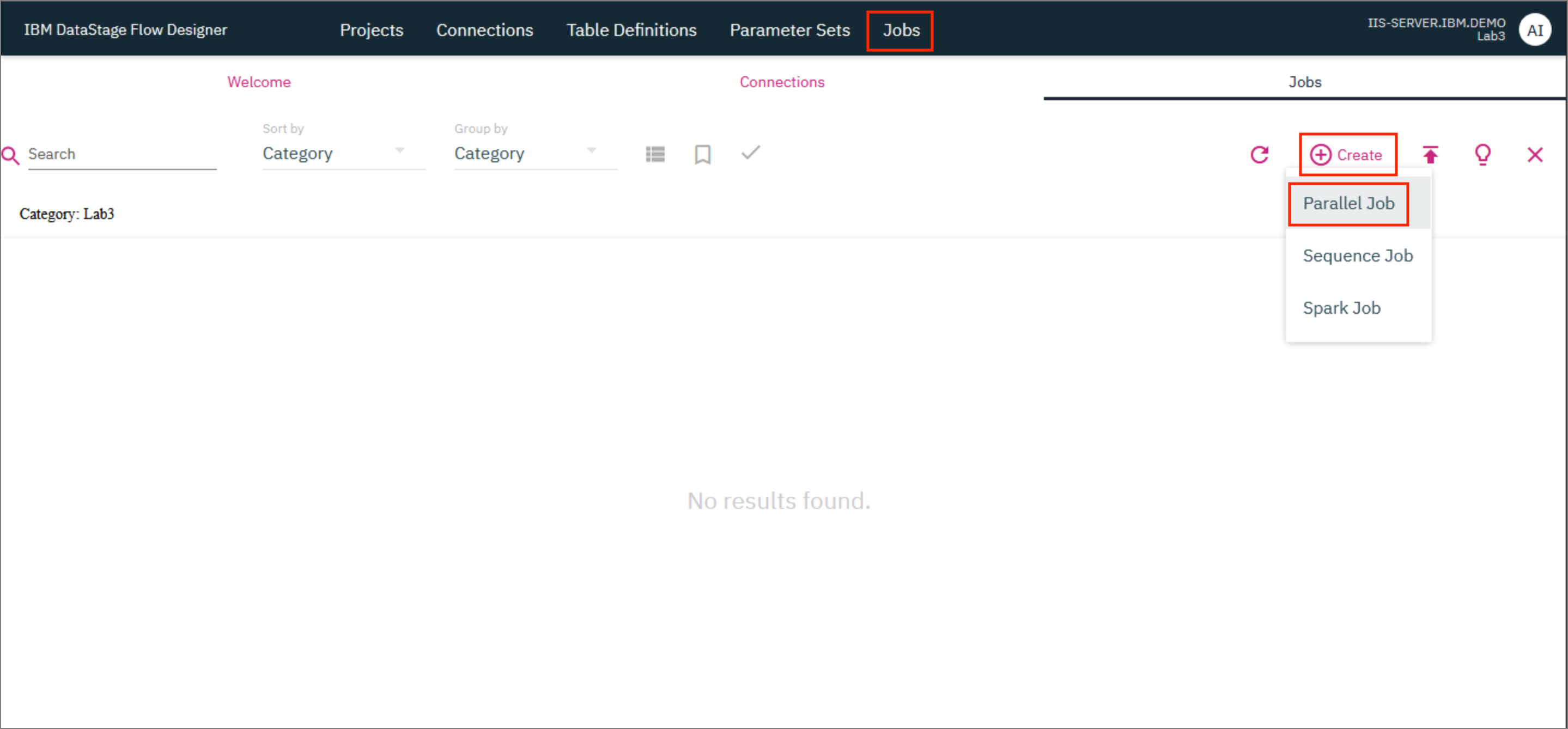
3. Create the job¶
- Click on the
Jobstab and then click+ Create. ClickParallel Job.
A new tab with the name Job_1* opens up where you can now start designing the parallel job.
Before designing the job, take a few minutes to look at the various buttons and menus available on the screen.
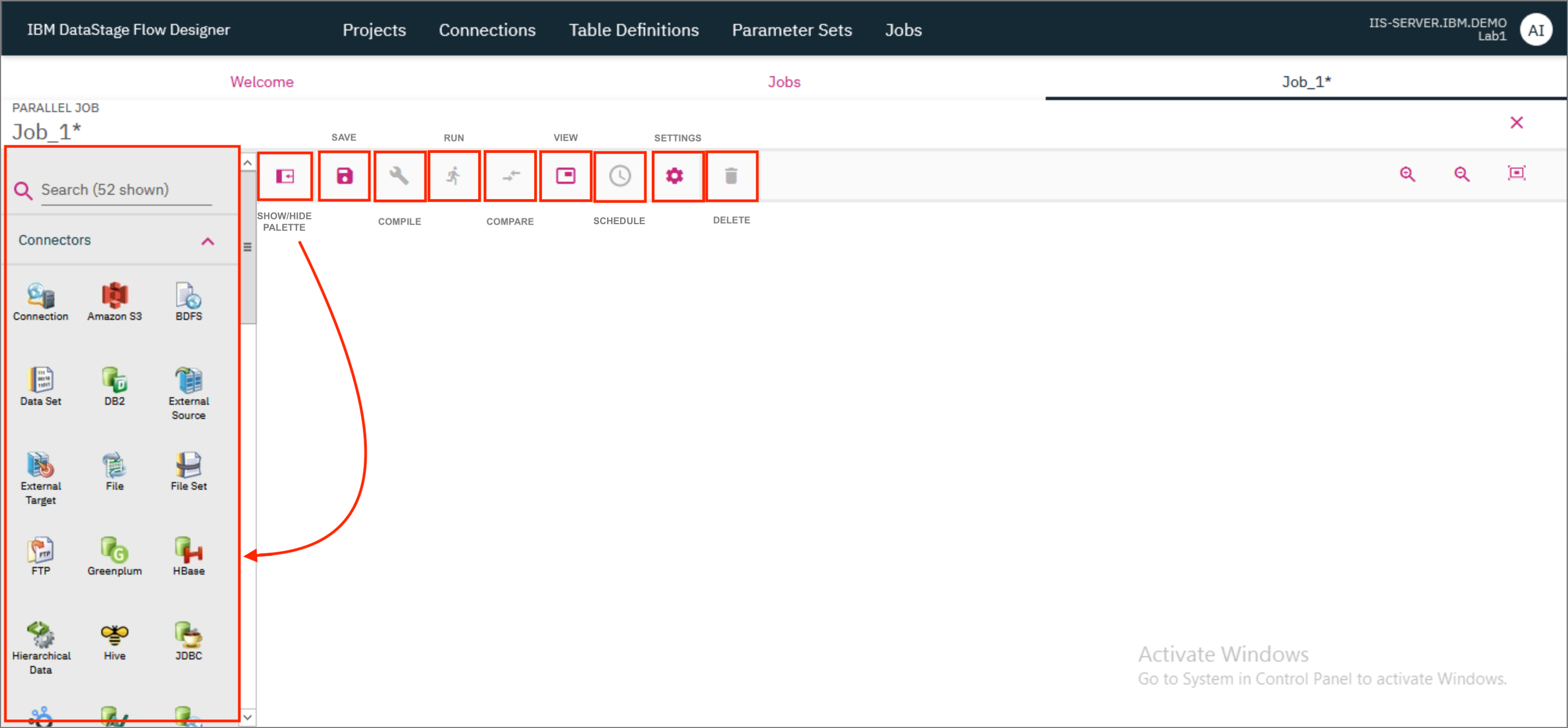
-
The
Show/Hide Palettebutton can be used to show or hide the palette on the left of the screen which contains the connectors and stages that can be used while designing the job. -
The
Save,CompileandRunicons are used to save, compile and run the job respectively. -
The
Compareicon is used to compare this job with another job in the Project. -
The
Viewmenu has the following options:- View OSH code - which is available once the job has been successfully compiled.
- View log - which is available once the job has been run.
- Properties - based on what is selected in the job canvas before clicking on
Properties, either the properties of the job or of a connector/stage/link are displayed.
-
The
Scheduleicon is used to set a schedule to run the job. -
The
Settingsmenu has a number of options such as- Apply horizontal layout - which arranges all the connectors and stages in the canvas in a horizontal manner with data flowing from left to right.
- The ability to view/hide annotations, arrows, link names, and the type of the connector/stage.
- Smart palette - which applies smart logic based on usage patterns to reorder the items available in the palette. If disabled, the items in the palette are displayed in an alphabetical order.
- Smart stage suggestions - applies smart logic based on usage patterns to suggest the next stage that you might want to add to the job.
- Drag a File connector to the canvas. The
Table Definition Asset Browseropens up. Selectraviga\ravigaproductsand clickNext.
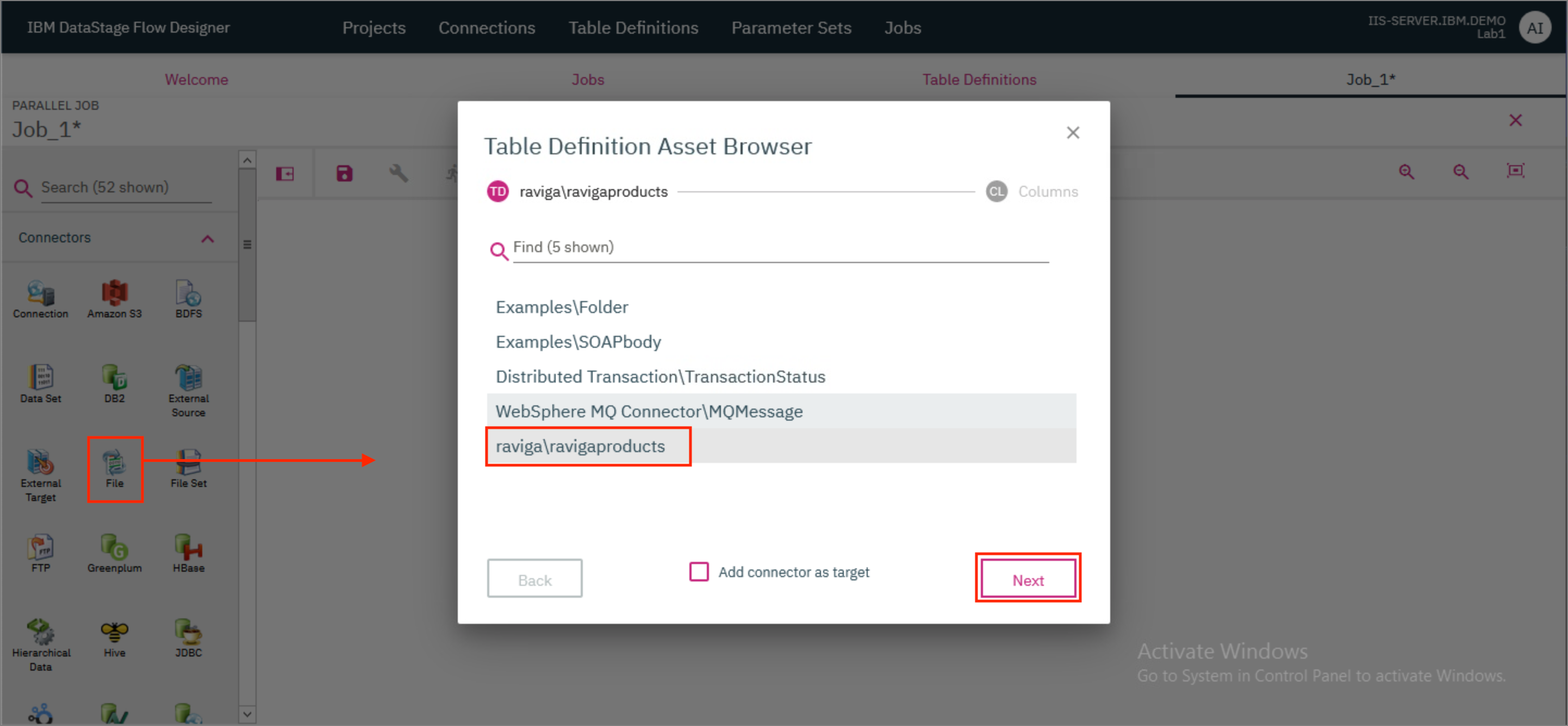
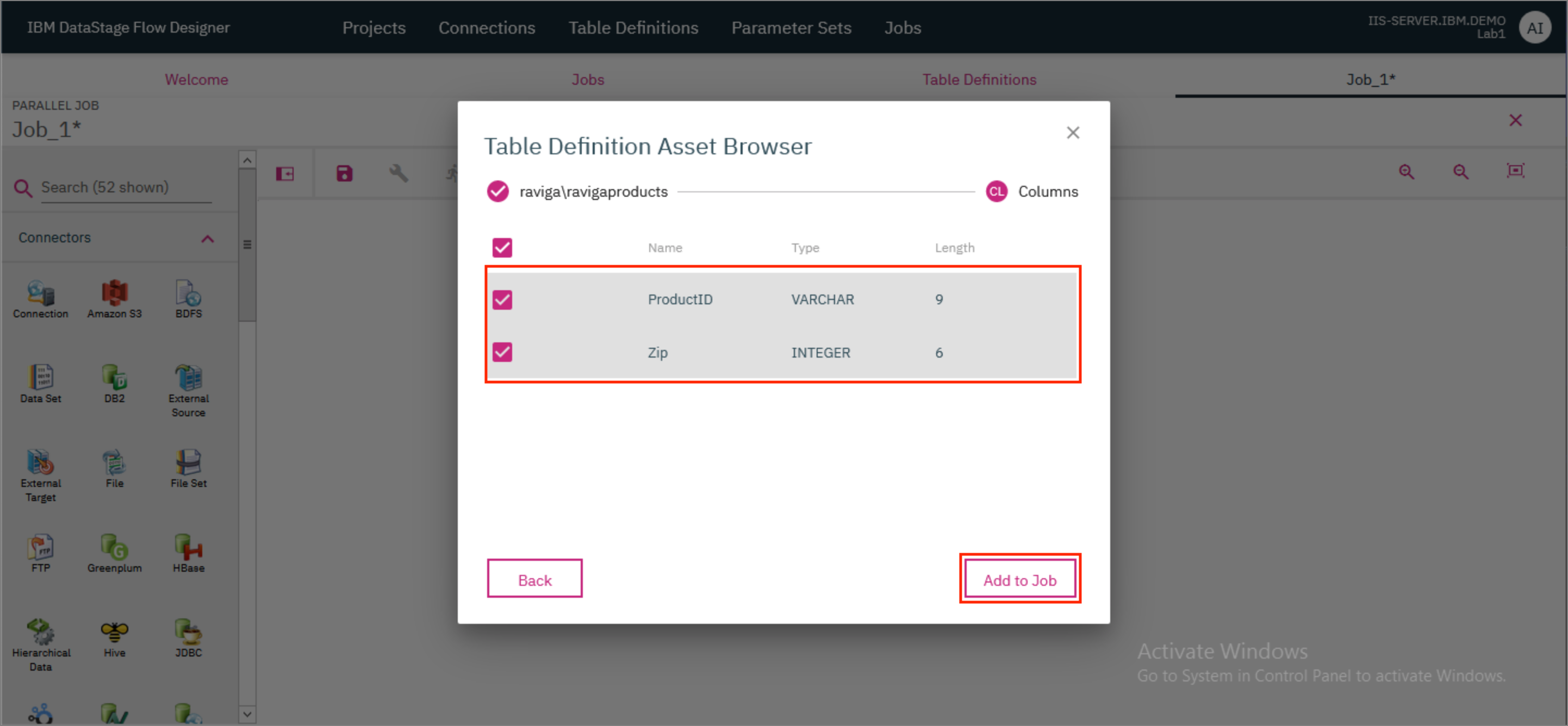
- Ensure that both the columns
ProductIDandZipare selected and clickAdd to Job.
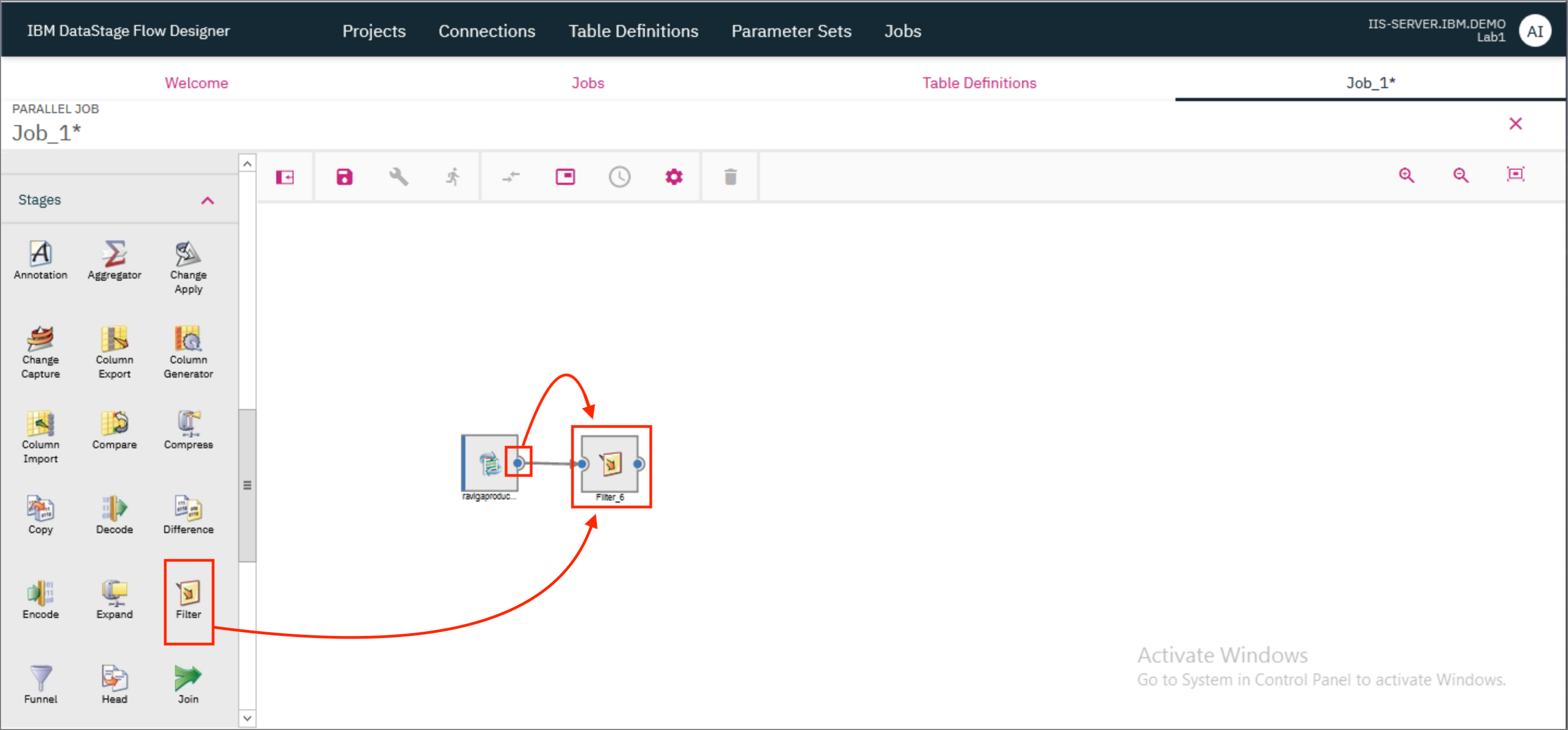
- The File connector should now be visible on the canvas. Drag and drop a Filter stage on the canvas. Provide the output of the File connector as the input to the Filter stage. To do this, click on the little blue dot on the right side of the File connector and drag the mouse pointer to the Filter stage.
NOTE: For another method to connect the File connector to the Filter stage, click on the File connector to select it and then drag and drop the Filter stage. The Filter stage will automatically be connected to the File connector.
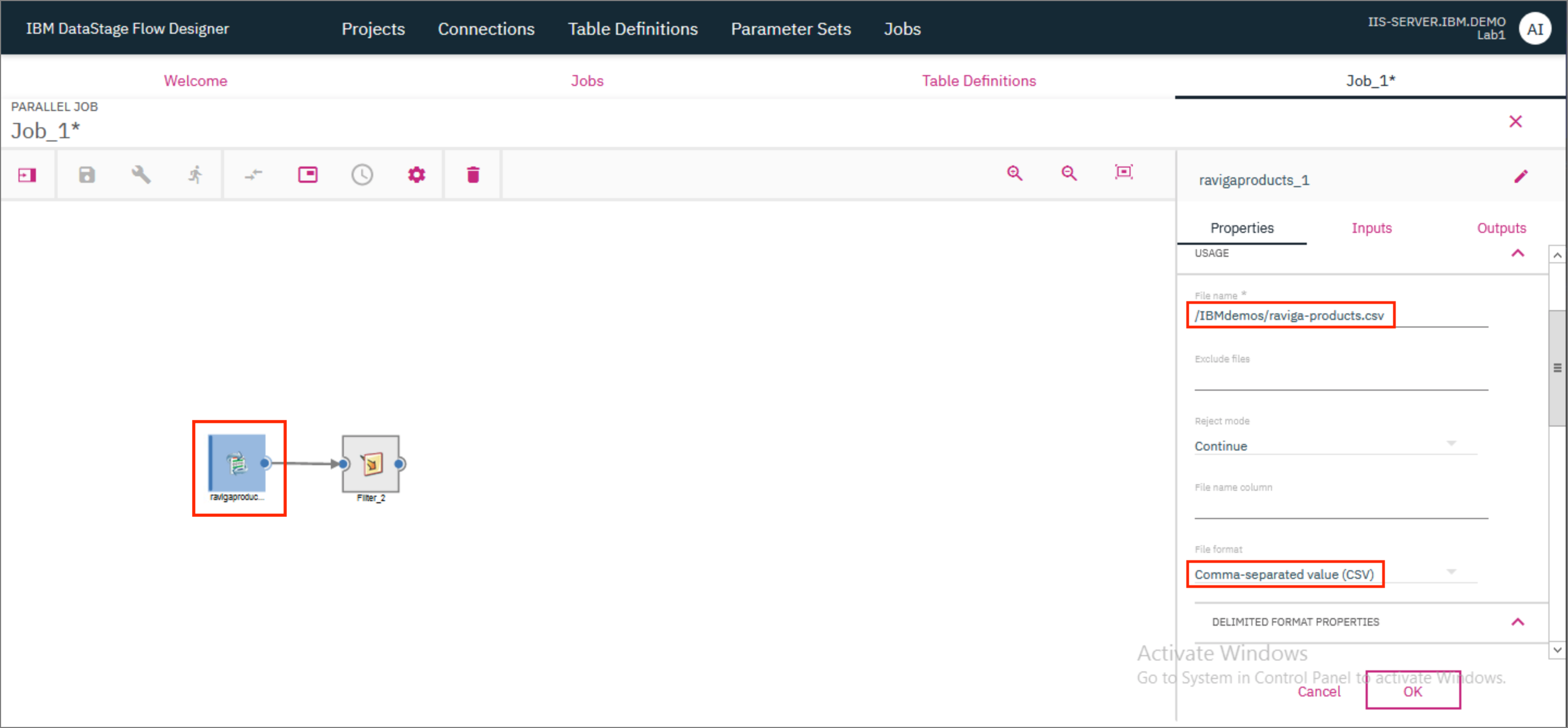
- Double click on the File connector to open the Connector's Properties page. Provide the File name as
/IBMdemos/raviga-products.csvwhich is where the source file is located. Further down, provide the File format asComma-separated value (CSV).
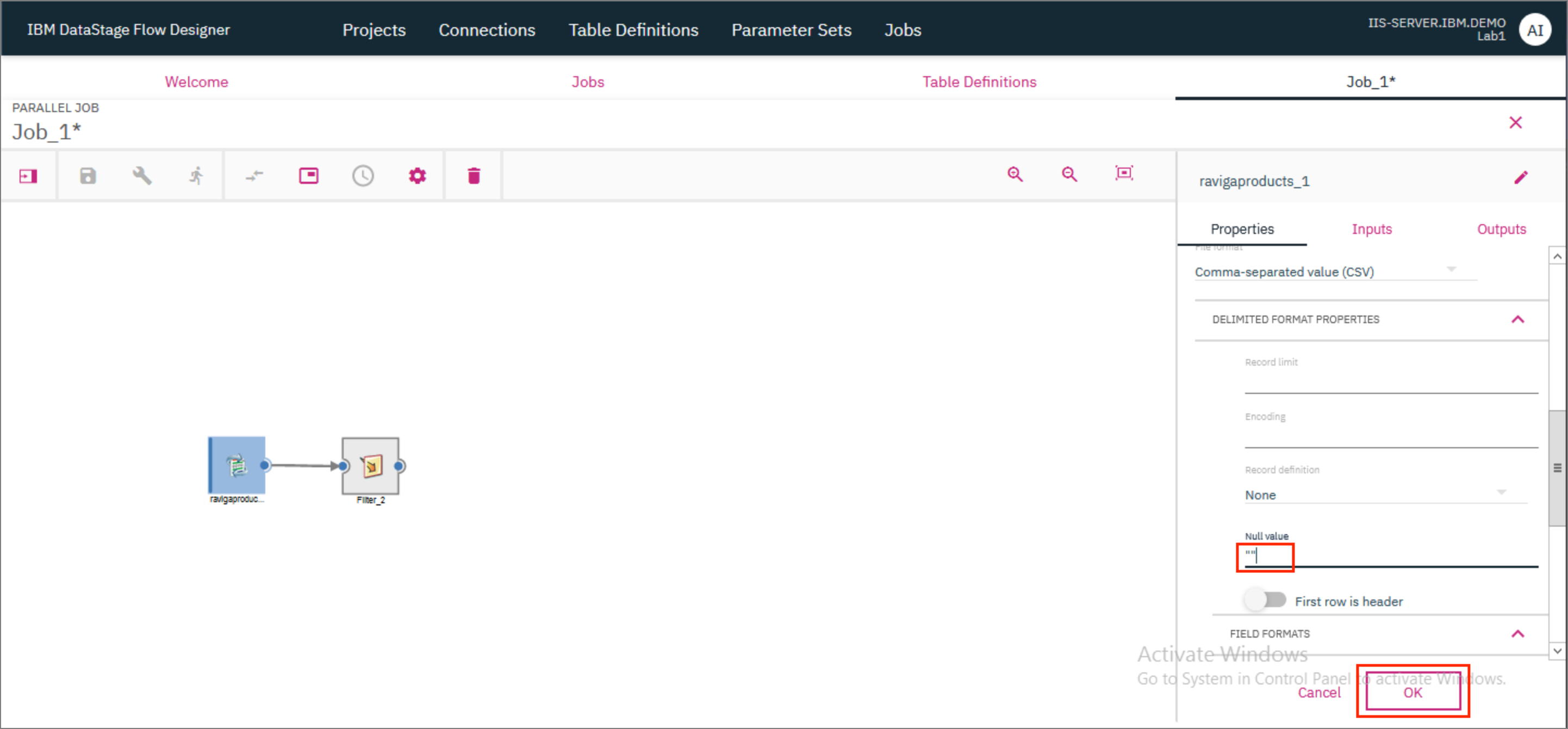
- Scroll further down and update the Null value to
"". ClickOK.
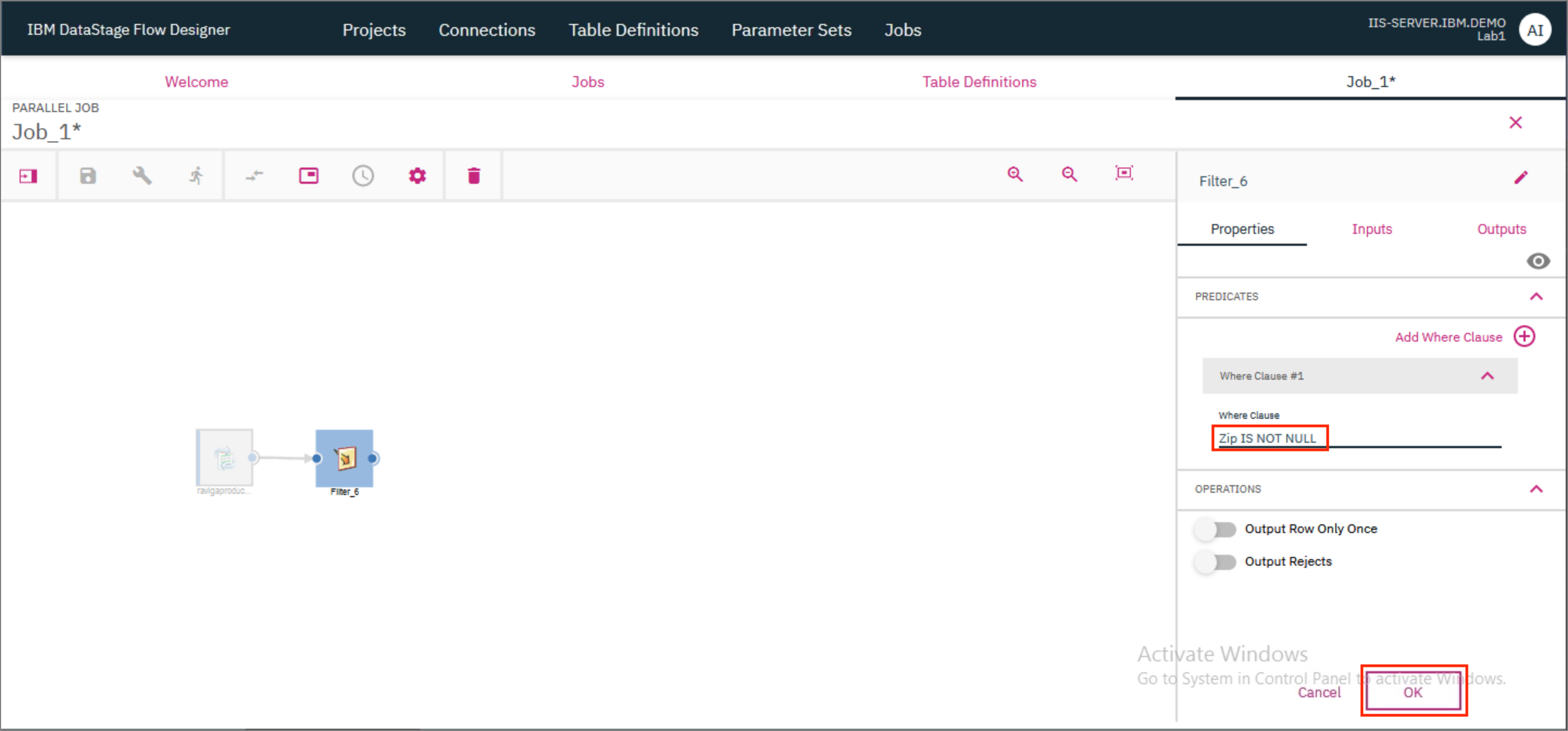
- Double click the Filter stage to open the Stage's Properties page. Provide the value for Where Clause as
Zip IS NOT NULL. This will filter out all the records in the table where the value of Zip is NULL. ClickOK.
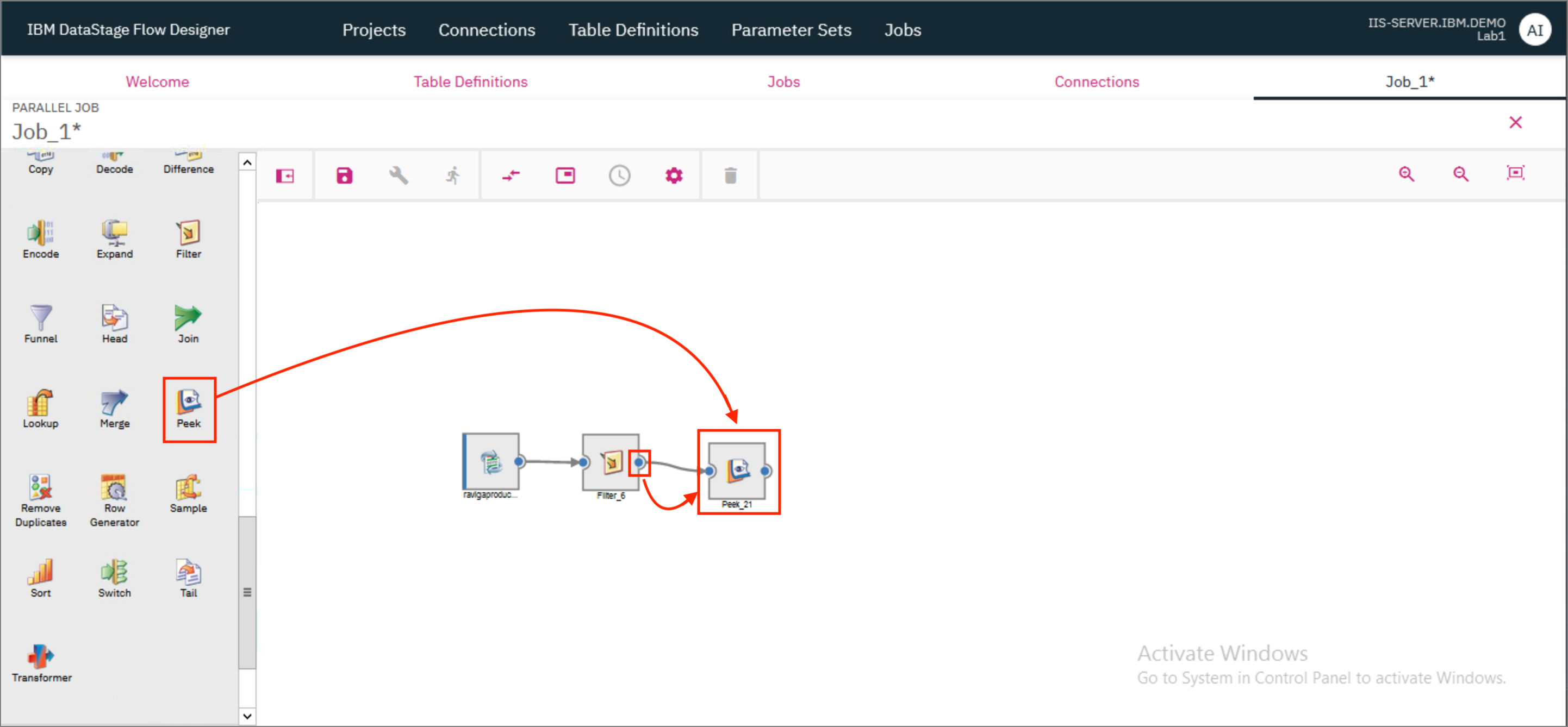
- We will use the Peek stage to look at the intermediate state of the table. Drag and drop a Peek stage to the canvas and provide the output of the Filter stage as the input to the Peek stage.
- Next, we will add a Remove Duplicates stage and provide the output of the Peek stage as the input to the Remove Duplicates stage.
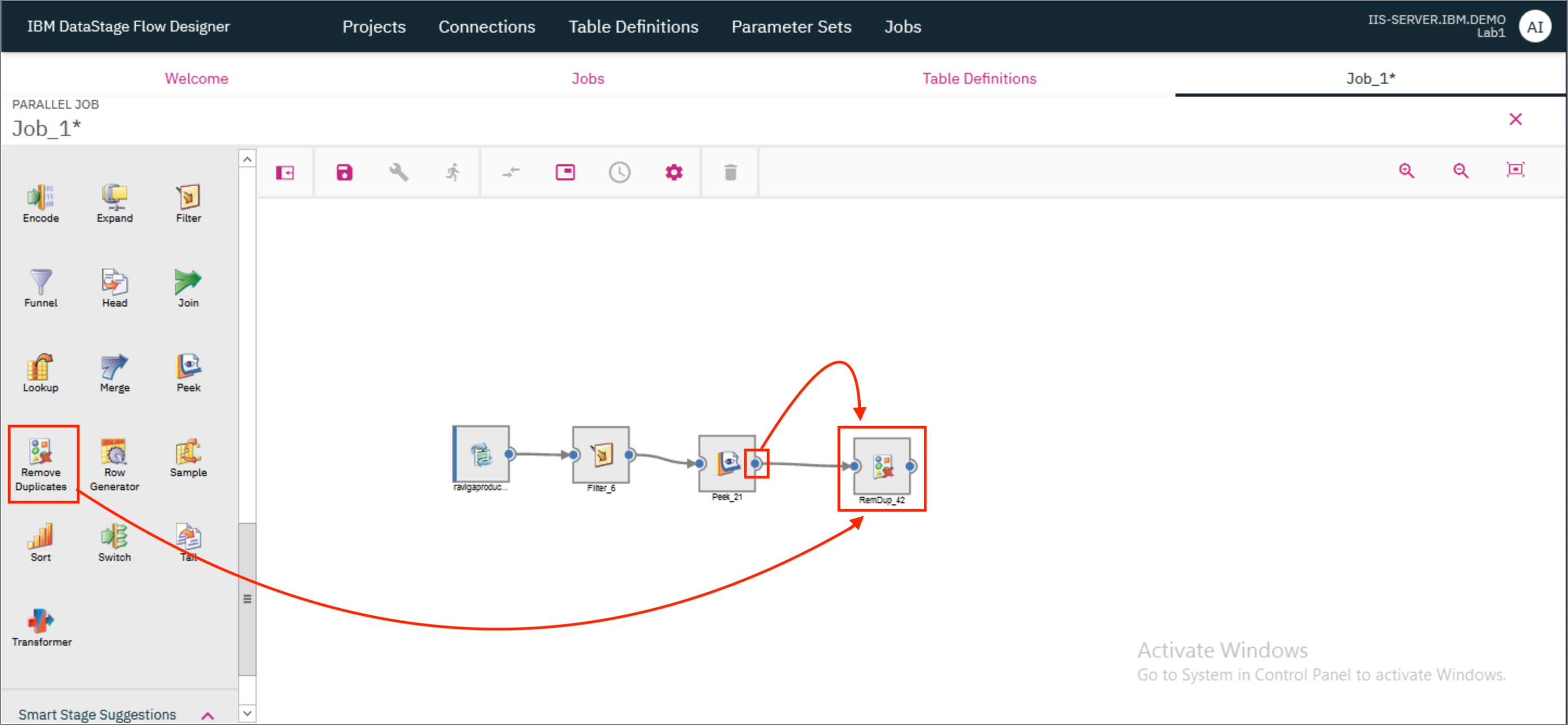
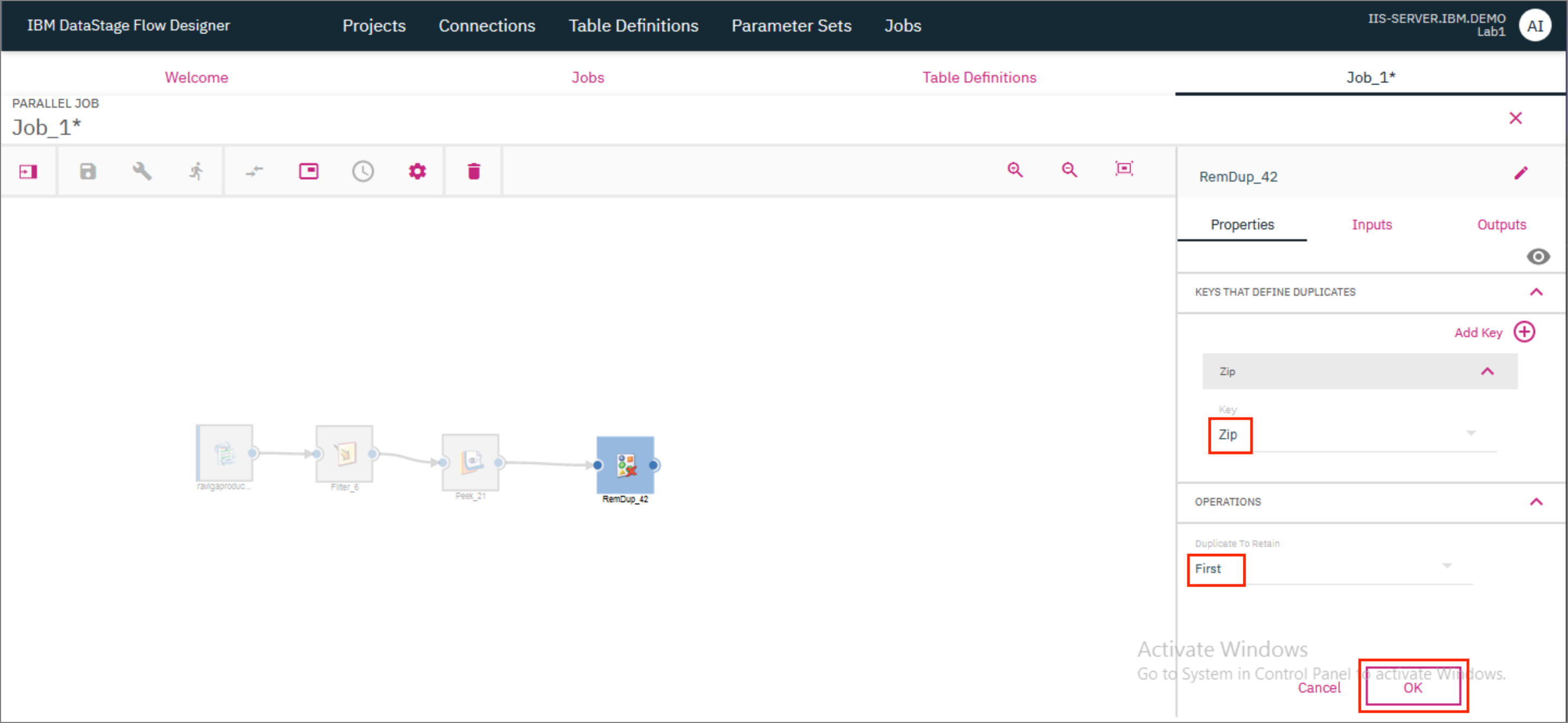
- Double click on the Remove Duplicates stage to open the Stage's Properties page. Under KEYS THAT DEFINE DUPLICATES, select
Zip. Set the value of Duplicate to retain asFirst. This will ensure that if there are any duplicate Zip values, the job will only retain the first record out of the records where this Zip value occurs. ClickOK.
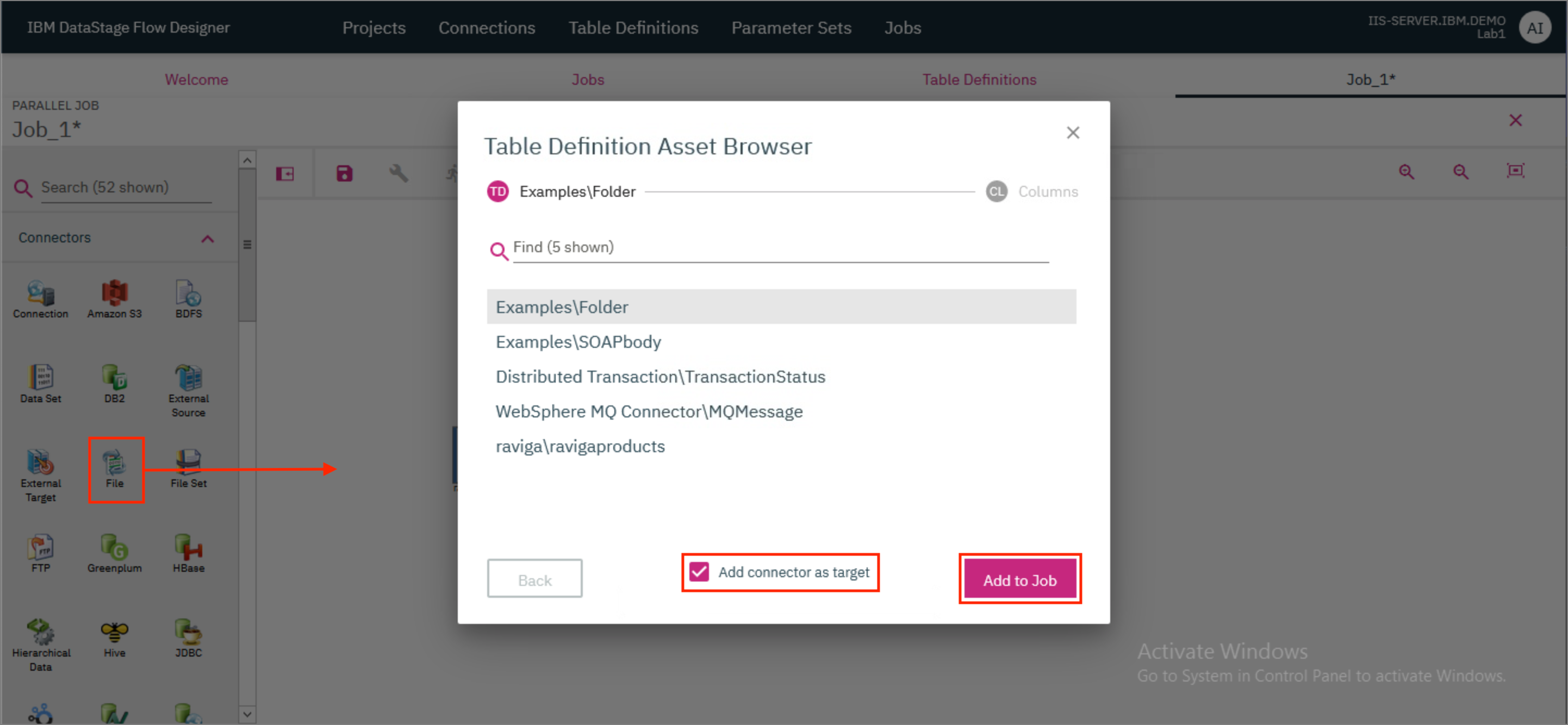
- Drag and drop a File connector to the canvas. In the modal that opens up, check the
Add connector as targetcheckbox and clickAdd to Job.
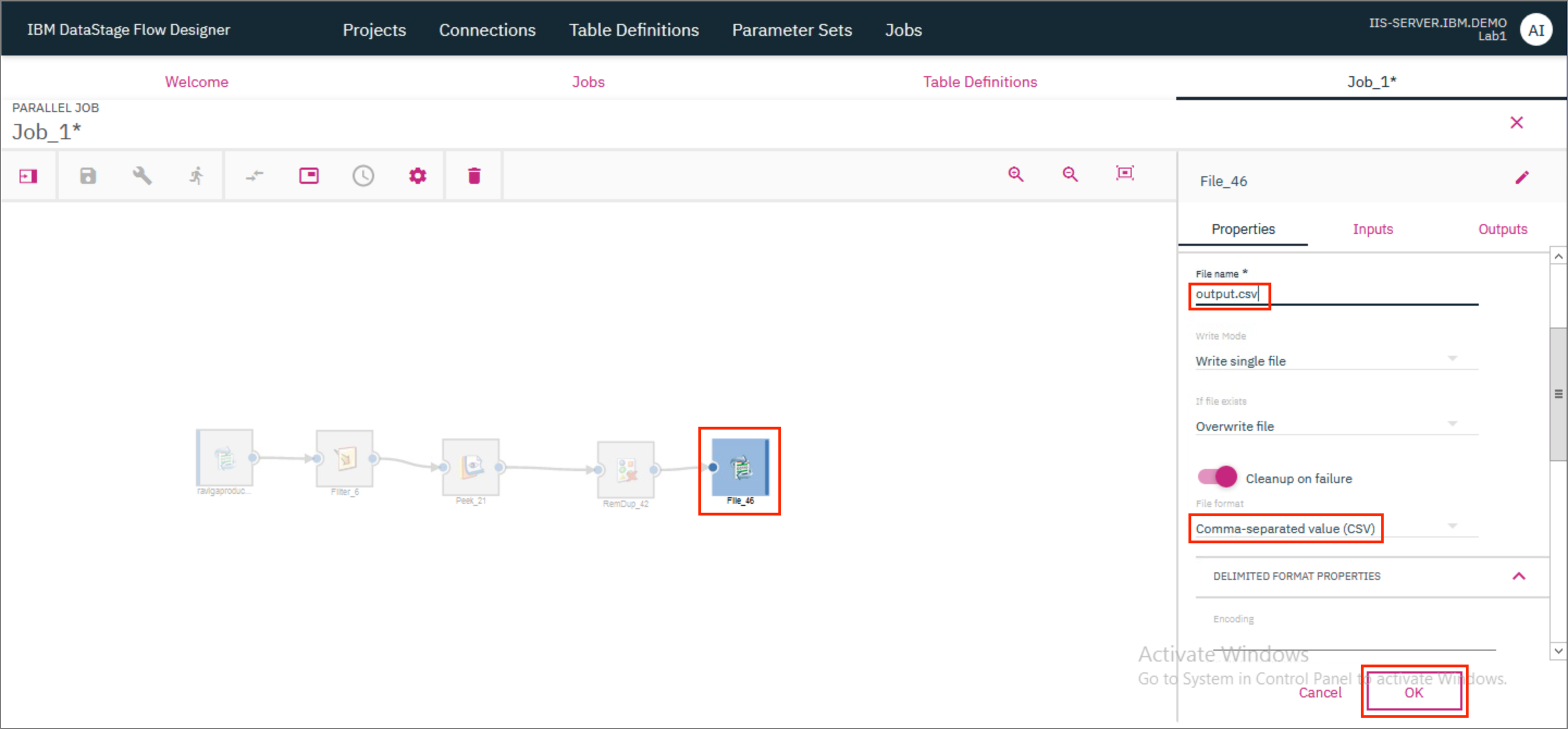
- Provide the output of the Remove Duplicates stage as the input to the File connector. Double click the File connector to open the stage page, and provide the File name as
output.csv. SpecifyComma-separated value (CSV)as the File format. ClickOK.
4. Compile and run the job¶
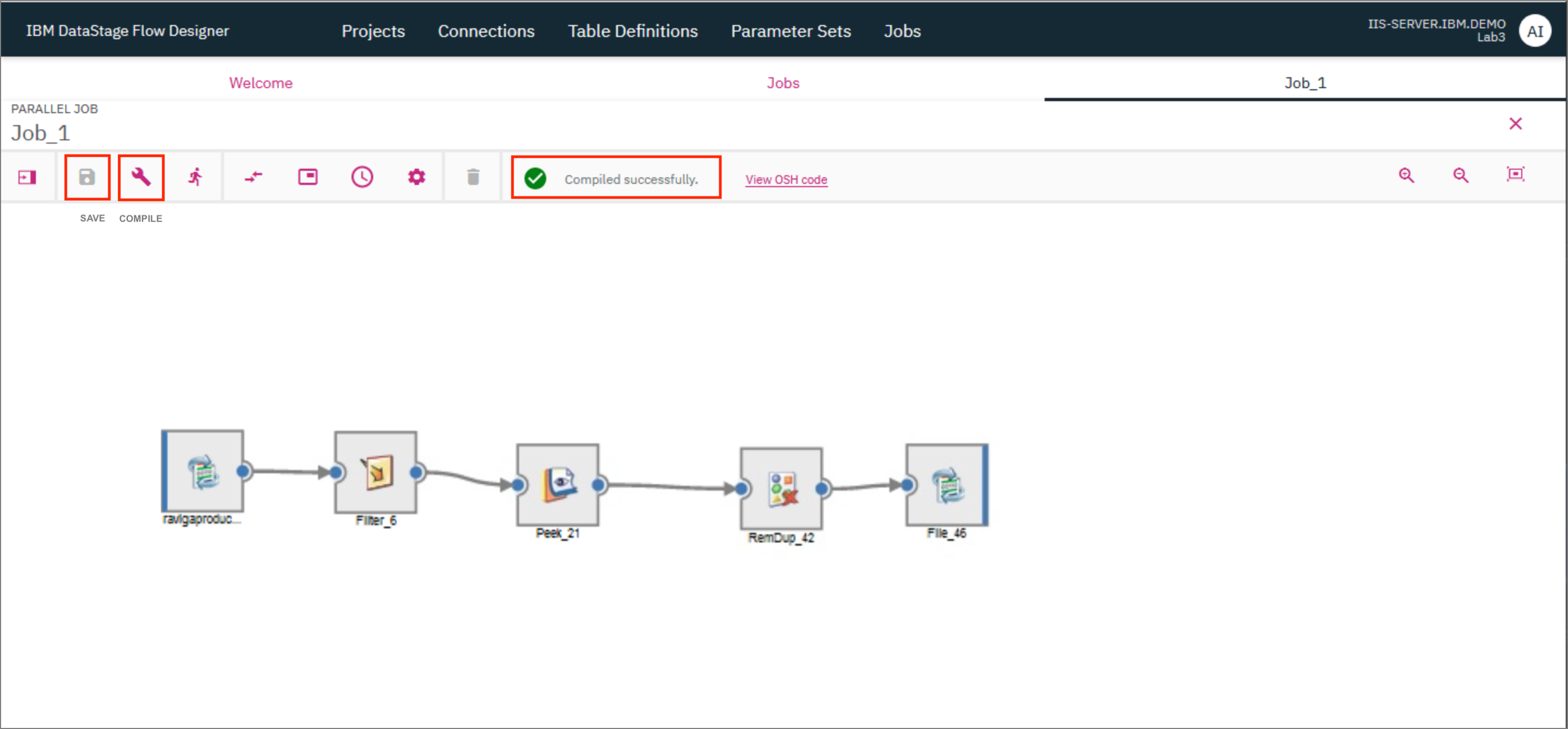
- Click the
Saveicon to save the job. If you wish to, you can provide a different name for the job in the modal that pops up. ClickSave. Once the job is saved, click on theCompileicon to compile it. If compilation is successful, you should see a green check mark and the messageCompiled successfullydisplayed on the screen. The OSH Code will also be available for viewing.
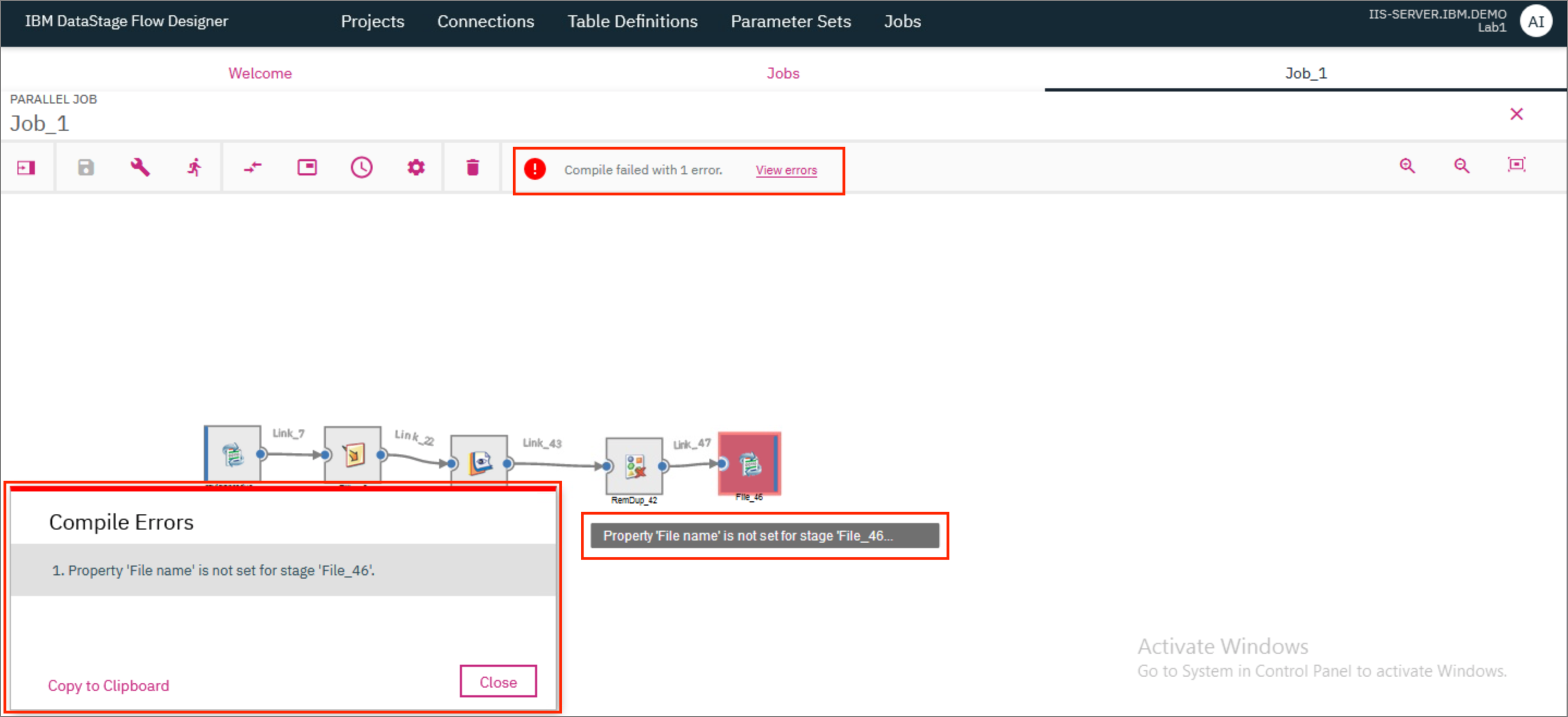
If the compilation was not successful, you should see a red error icon and the message Compiler failed with ### errors. where ### represents the number of errors. Clicking on View errors brings up a modal that lists all the errors that were found. The stage/connector/link that has the error is also highlighted in the canvas and you can hover over it to see the error.
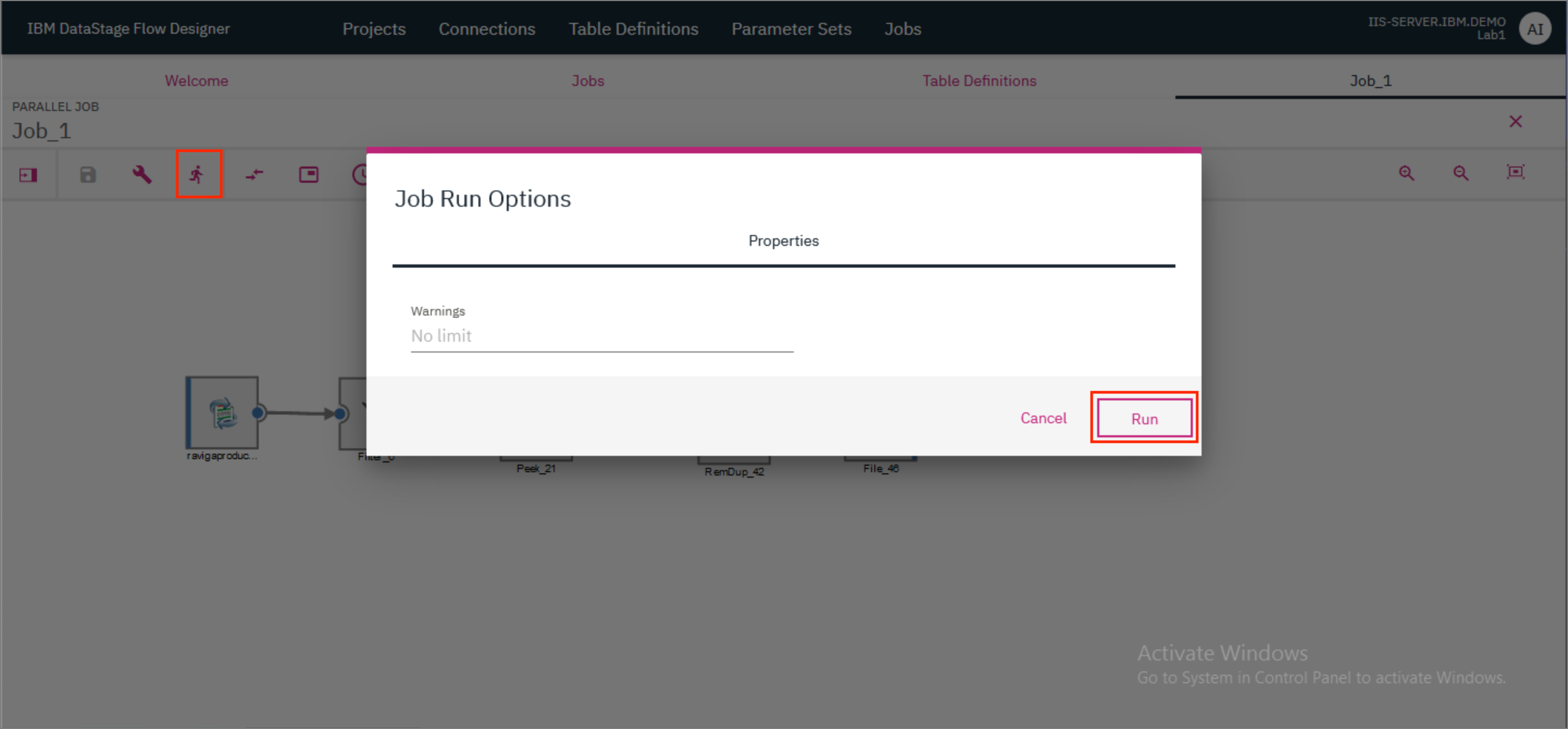
- Click the
Runicon to run the job. In the modal that opens up, clickRun.
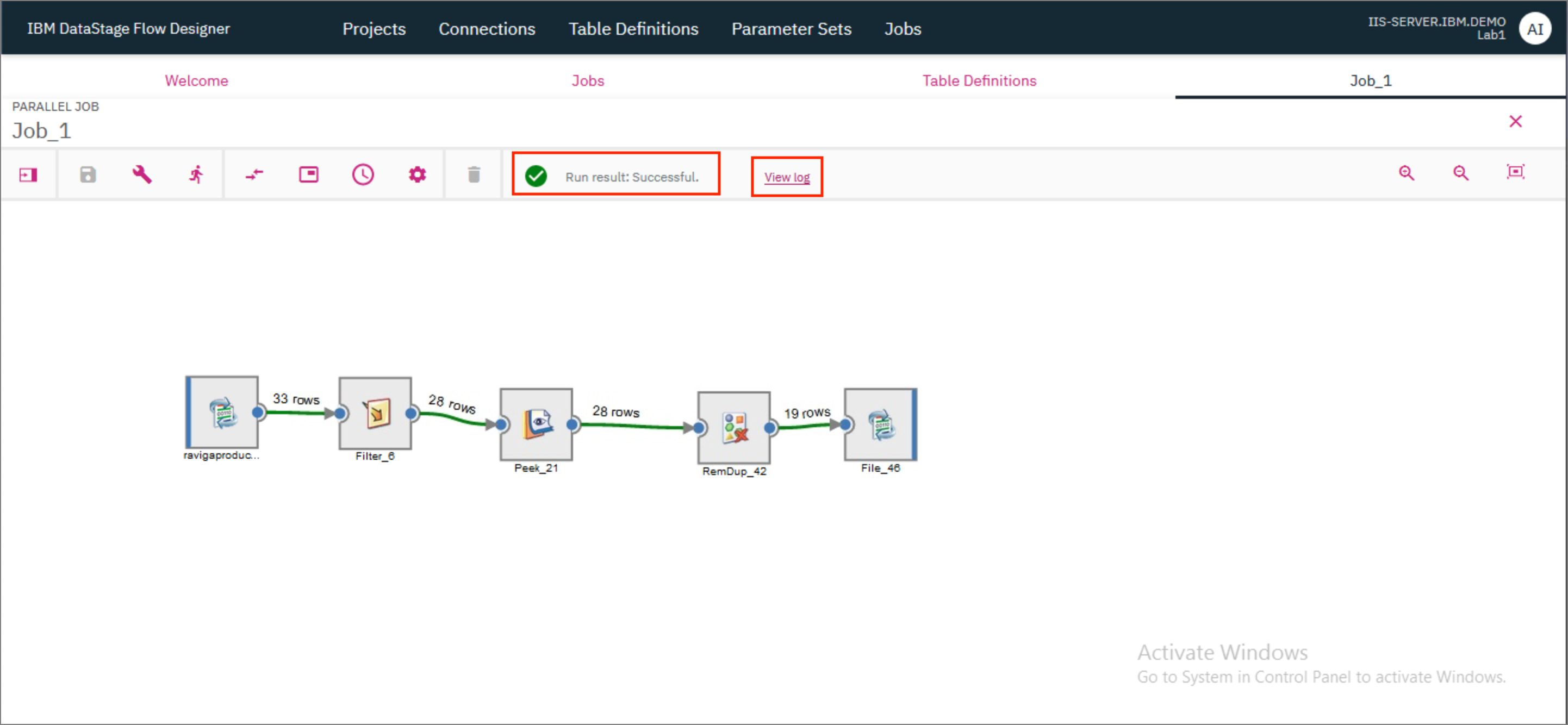
- Once the run completes, you should see the status of the run on the screen. The status will also indicate if there were any warnings or errors. Click on
View logto get more details about the run.
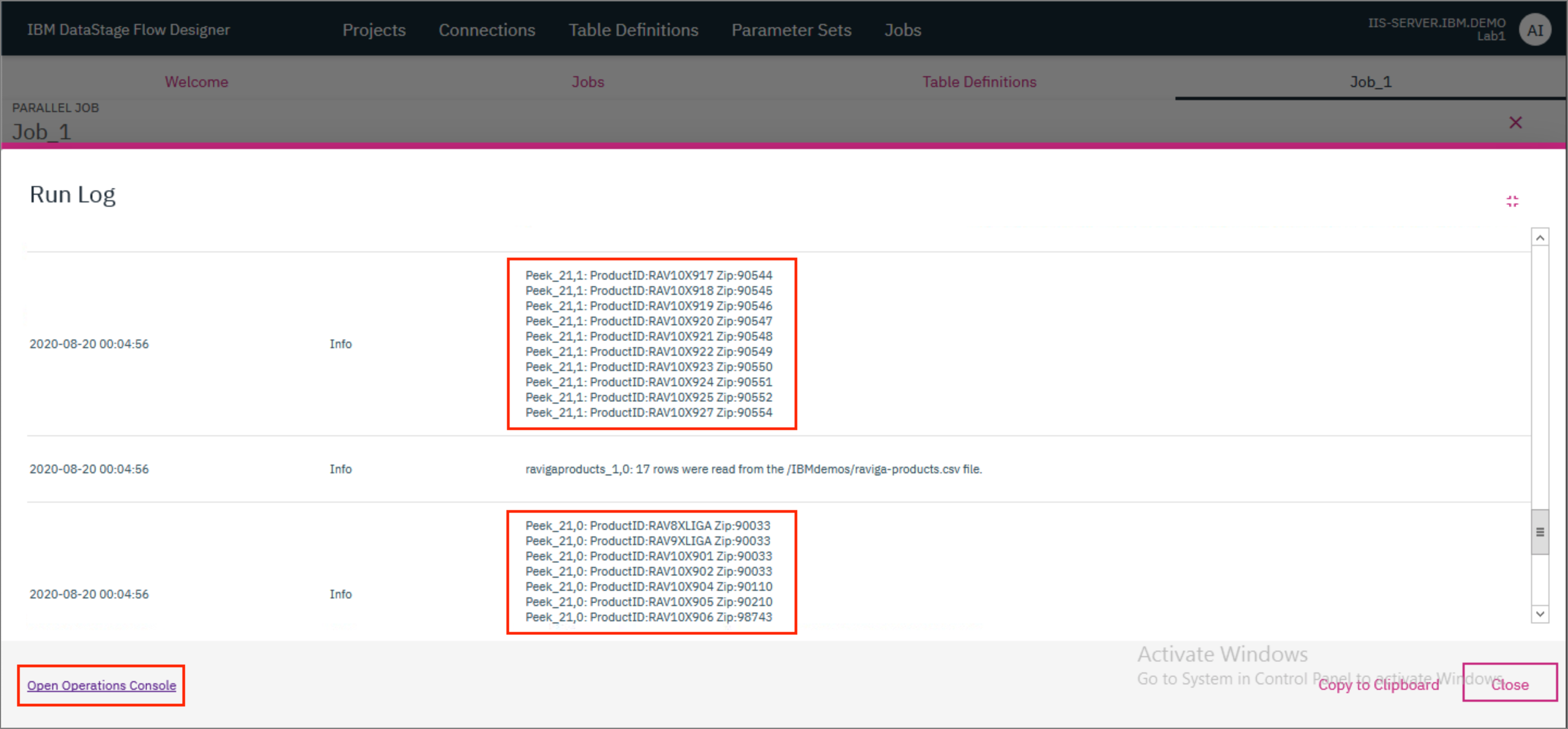
- Everything that happens as part of the job run is available in the log. This includes warnings, errors and informational messages such as the results of the Peek stage. Scroll through the log to reach the Peek results. By default, the Peek stage only logs the first 10 records of the partition (the data was split into two partitions in this case). You can see how in both Peek logs there are no records where Zip value is NULL.
5. Use Operations Console to view previous logs¶
- At the bottom of the log, click on
Open Operations Console. Alternatively, you can open theClassic Launchpadin Firefox and click onOperations Console.
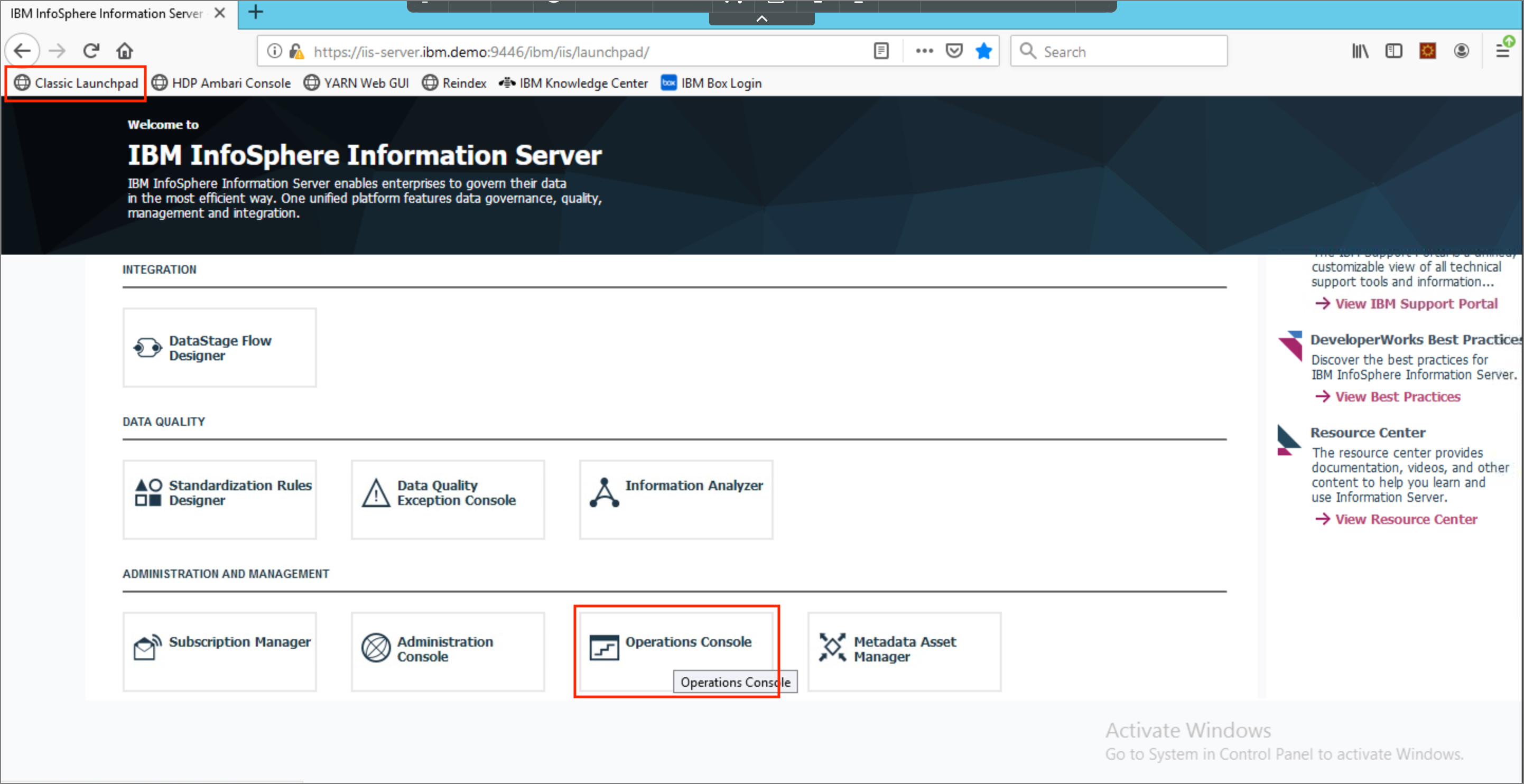
- The Operations console can be used to view logs for previous runs of the job. Switch to the
Projectstab. In the left-hand navigation pane, expandLab1(the transformation project), followed byJobs. Click onJob_1(the job that was just saved/compiled/run). TheJob Runstable at the bottom of the screen will be updated to reflect all the times that the job was run. Click on any job run in the list to select it and clickView Details.
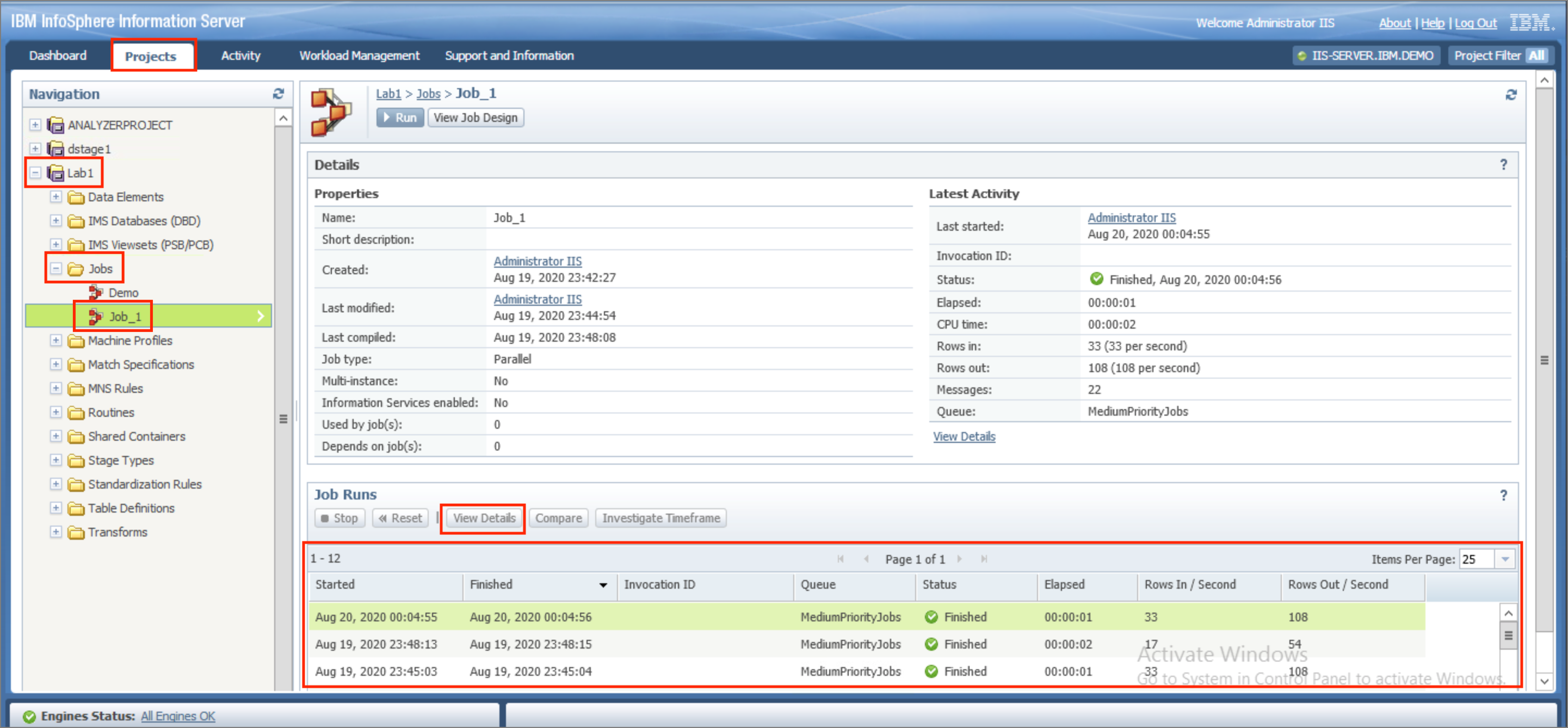
- Go to the
Log Messagestab and check theFull Messagescheckmark to see the complete log for the job run. Clicking on an entry in the job log will display the log message details at the bottom.
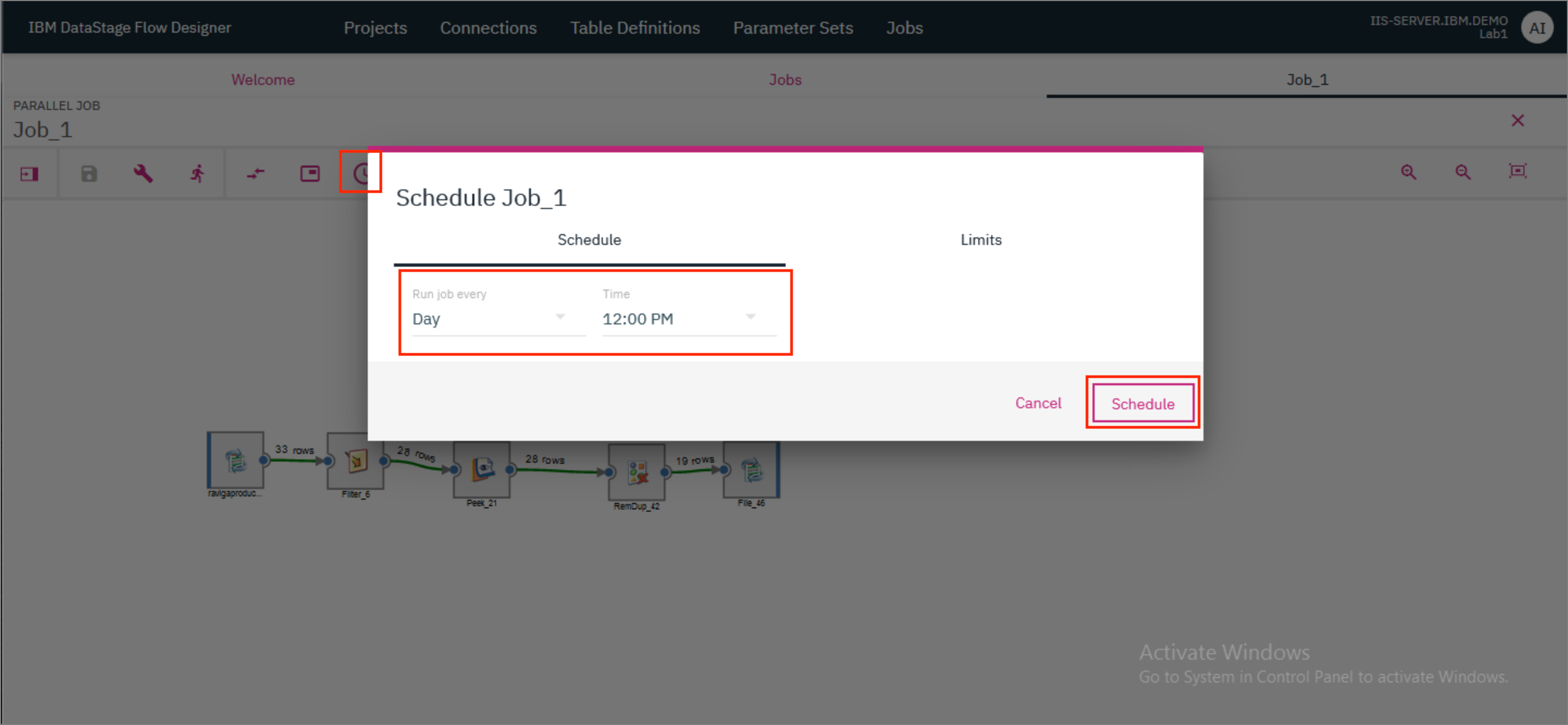
6. Scheduling the job¶
DataStage Flow Designer provides the ability to run jobs as per a schedule.
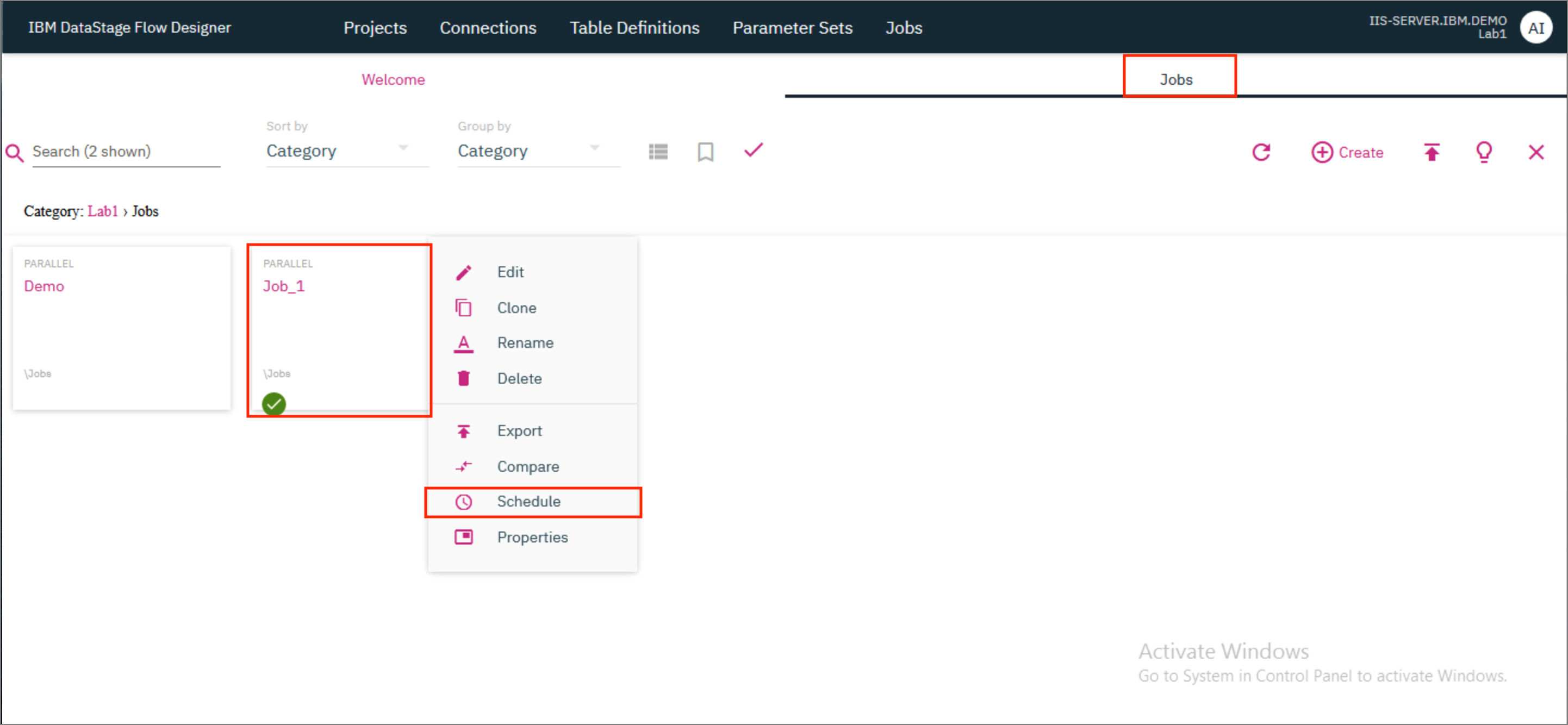
- Back in the DataStage Flow Designer where we were designing the job, click on the
Scheduleicon. In the modal that opens up, provide the frequency for running the job - whether you want to run it everyDay,WeekorMonth. Next to it, provide the time of the day when the job should run. ClickSchedule.
Alternatively you can go up one level to the Jobs tab, and hover over your job's tile to see the kebab icon (⋮). Click on the icon and select Schedule to open up the scheduling modal where you can set up a schedule for your job.
NOTE: You can only schedule your job once it has been successfully compiled.
7. View output¶
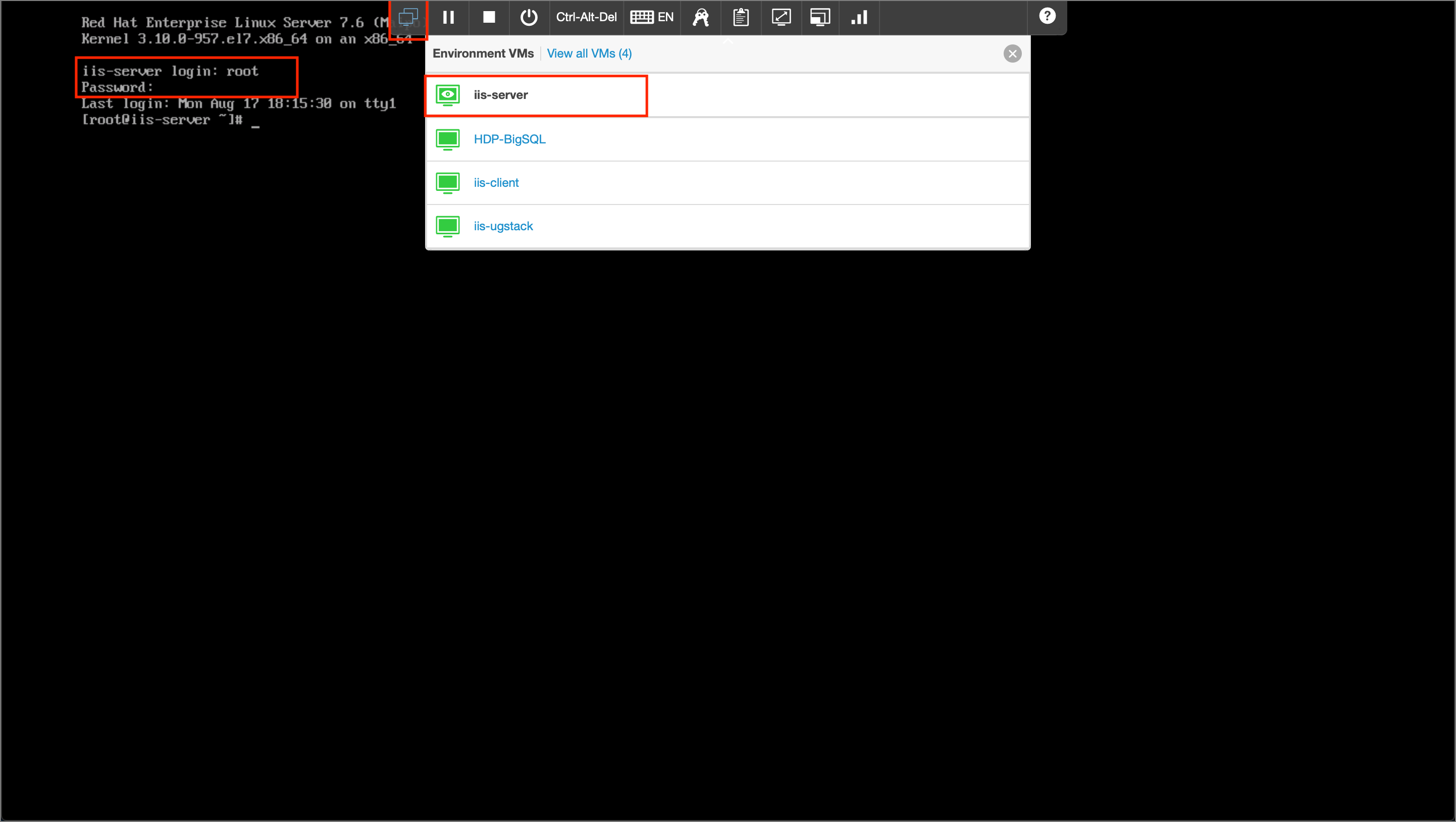
- The output file will be saved on the server. Switch to the server VM by clicking the first icon on the
Environment VMs paneland selectingiis-server. Login as therootuser with the passwordinf0Xerver.
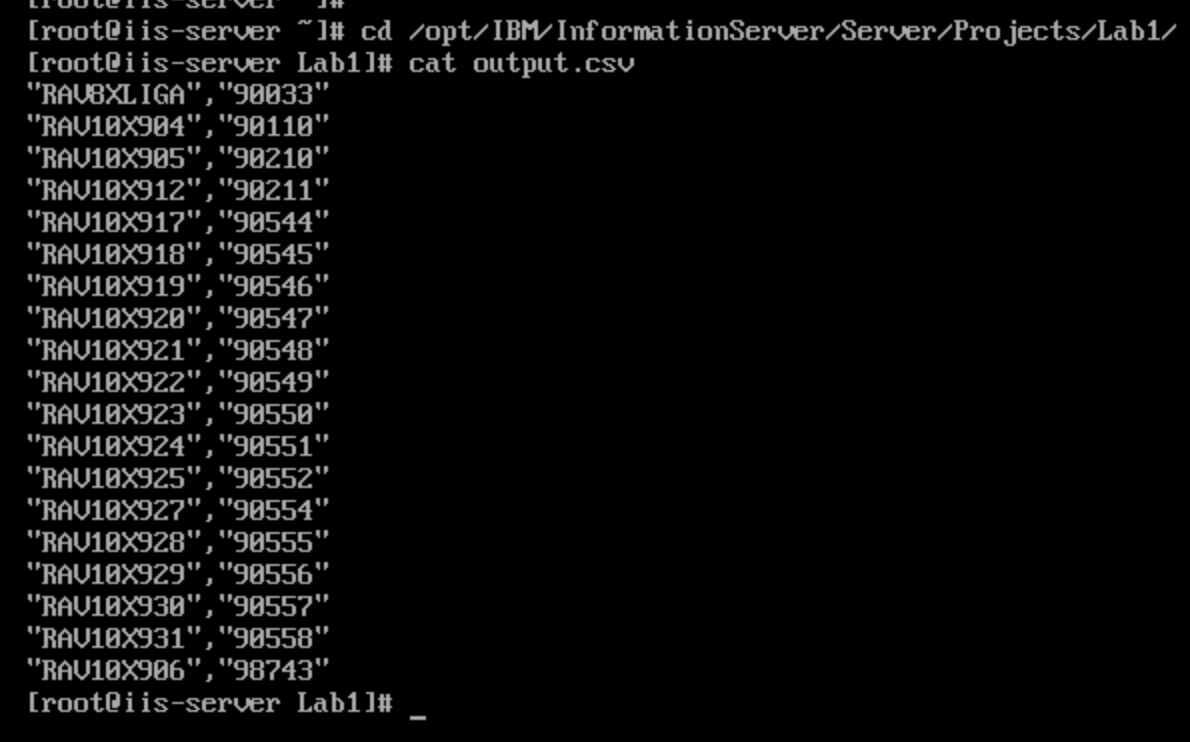
- CD to the location where you had stored the file. If you provided a path starting at "/", then it will be stored at that location in the server. Since we had only provided
output.csvas the file path in the File connector, the file will be available in the Transformation project's folder, i.e.,
/opt/IBM/InformationServer/Server/Projects/<project-name>/
CONGRATULATIONS!! You have completed this lab!