Deliver changes with the next planned release
The following diagram depicts the typical workflow to deliver changes for the next planned release. In the default workflow, the development team commits changes to the head of the main branch. The changes of the next planned release are built, packaged, and released from the main branch.
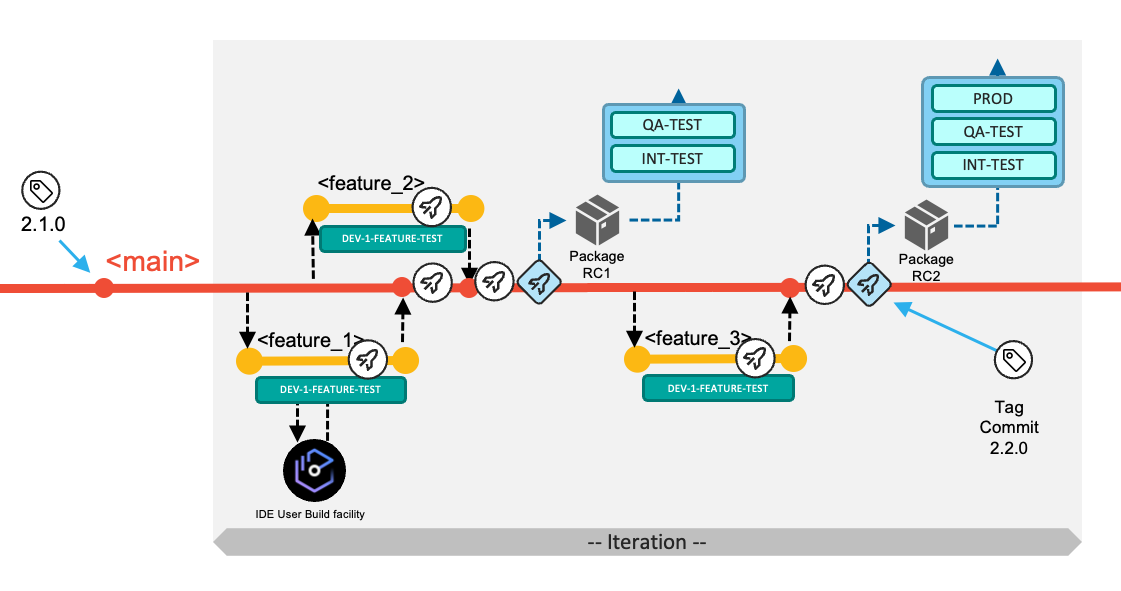
Developers implement their changes by committing to short-living feature branches (visualized in yellow), and integrate those via pull requests into the long-living main branch (visualized in red), which is configured to be a protected branch.
At a high level, the development team works through the following tasks:
-
New work items are managed in the backlog. The team decides which work items will be implemented in the next iteration. Each application team can decide on the duration of the iteration (which can also be seen as the development cycle). In the above diagram, three work items (Feature 1, Feature 2, and Feature 3) were selected to be implemented for the next iteration. The development team is responsible for coordinating if features are required to be implemented in a specific order.
-
For each work item, a feature branch is created according to pre-defined naming conventions, such as
feature/42-new-mortgage-calculation. The feature branch allows the assigned developers to work on their changes in isolation from other concurrent development activities.- Note: In the diagrams for this workflow, multi-segmented branch names are abbreviated to their contexts in the diagrams for readability (for example,
feature_1orhotfix_1).

- Note: In the diagrams for this workflow, multi-segmented branch names are abbreviated to their contexts in the diagrams for readability (for example,
-
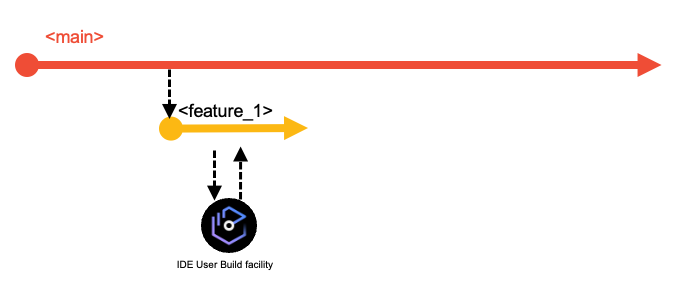
To start making the necessary modifications for their development task, developers create a copy of the Git repository on their local workstations through Git's clone operation. If they already have a local clone of the repository, they can simply update their local clone with the latest changes from the central Git repository by fetching or pulling updates into their local clone. This process makes the feature branch available for the developers to work with on their local workstation. They can then open their local clone of the repository in their integrated development environment (IDE), and switch to the feature branch to make their code changes.
-
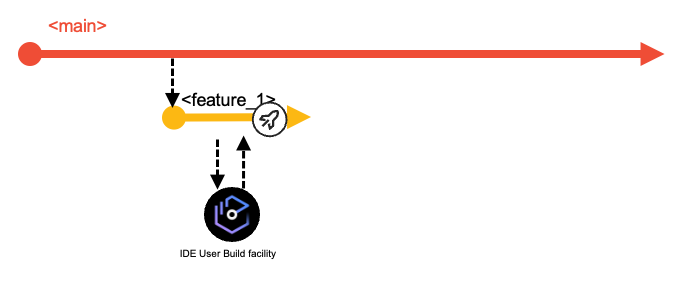
Developers use the Dependency Based Build (DBB) User Build facility of their IDE to validate their code changes before committing the changes to their feature branch and pushing the feature branch with their updates to the central Git repository. (Tip: Feature branches created locally can also be pushed to the central Git server).
 tip
tipThis branching model is also known as a continuous integration model to reduce merge conflicts. While developing on the feature branch, a common practice is for developers to regularly sync their feature branch with the
mainbranch by merging the latest changes from themainbranch into their feature branch. This ensures that developers are operating based on a recent state ofmain, and helps to identify any potential merge conflicts so that they can resolve them in their feature branch. -
Developers test their changes before requesting to integrate them into the shared codebase. For example, they can test the build outputs of the User Build step. For a more integrated experience, the CI/CD pipeline orchestrator can be configured to run a pipeline for the feature branch on the central Git server each time the developers push their committed changes to it. This process will start a consolidated build that includes the changed and impacted programs within the application scope. Unit tests can be automated for this pipeline, as well. To continue even further testing the feature branch, the developer might want to validate the build results in a controlled test environment, which is made possible by an optional process to create a preliminary package for the feature branch.
-
When developers feel their code changes are ready to be integrated back into the shared
mainbranch, they create a pull request asking to integrate the changes from their feature branch into themainbranch. The pull request process provides the capability to add peer review and approval steps before allowing the changes to be merged. As a basic best practice, the changes must be buildable. If the pull request is associated with a feature branch pipeline, this pipeline can also run automated builds of the code in the pull request along with tests and code quality scans. -
Once the pull request is merged into the
mainbranch, the next execution of the Basic Build Pipeline will build all the changes (and their impacts) of the iteration based on themainbranch.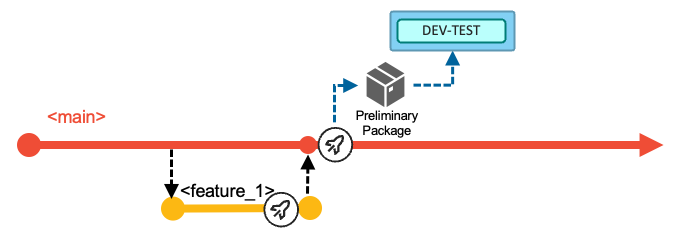
The pipeline can optionally include a stage to deploy the built artifacts (load modules, DBRMs, and so on) into a shared test environment, as highlighted by the blue DEV-TEST icon in the above diagram. In this DEV-TEST environment, the development team can validate their combined changes. This first test environment helps support a shift-left testing strategy by providing a sandbox with the necessary setup and materials for developers to test their changes early. The installation happens through the packaging and deployment process of a preliminary package that cannot be installed to higher environments (because it is compiled with test options), or alternatively through a simplified script solution performing a copy operation. In the latter, no inventory and no deployment history of the DEV-TEST system exist.
-
In the example scenario for this workflow, the development team decides after implementing Feature 1 and Feature 2 to progress further in the delivery process and build a release candidate package based on the current state of the
mainbranch. With this decision, the development team manually runs the Release Pipeline. This pipeline rebuilds the contributed changes for this iteration - with the compiler options to produce executables optimized for performance rather than for debug. The pipeline includes an additional stage to package the build outputs and create a release candidate package (Package RC1 in the following diagram), which is stored in a binary artifact repository.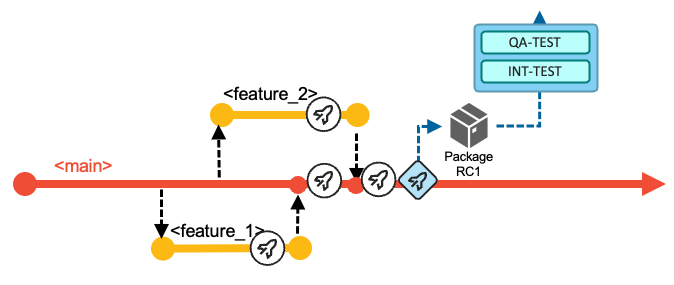
Although not depicted in the above diagram, this point in
main's history can be tagged to identify it as a release candidate. -
The release candidate package is installed in the various test stages and takes a predefined route. The process can be assisted by the pipeline orchestrator itself, or the development team can use the deployment manager. In the event of a defect being found in the new code of the release candidate package, the developer creates a feature branch from the
mainbranch, corrects the issue, and merges it back into themainbranch (while still following the normal pull request process). It is expected that the new release candidate package with the fix is required to pass all the quality gates and to be tested again. -
In this sample walkthrough of an iteration, the development of the third work item (Feature 3) is started later. The same steps as above apply for the developer of this work item. After merging the changes back into the
mainbranch, the team uses the Basic Build Pipeline to validate the changes in the DEV-TEST environment. To create a release candidate package, they make use of the Release Pipeline. This package (Package RC2 in the following diagram) now includes all the changes delivered for this iteration -- Feature 1, Feature 2 and Feature 3.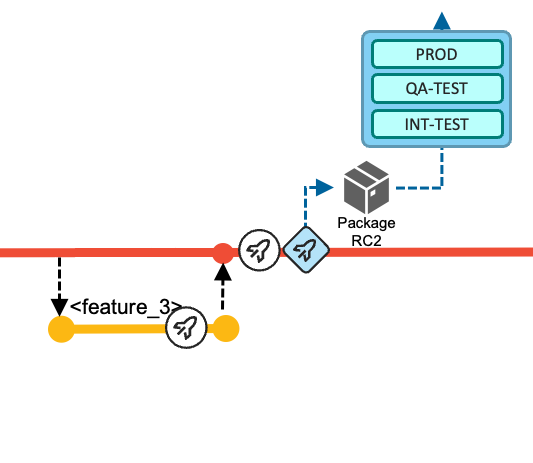
-
When the release is ready to be shipped after all quality gates have passed successfully and the required approvals have been issued by the appropriate reviewers, the deployment of the package from the binary artifact repository to the production runtime environment is performed via the deployment manager or is initiated from the Release Pipeline.
-
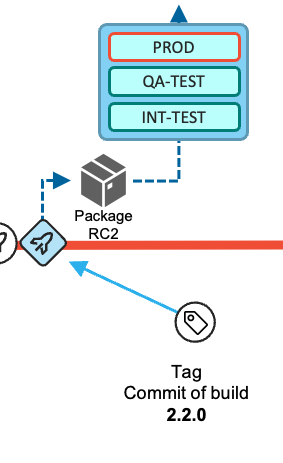
Finally, during the release process to the production environment, the state of the repository (that is, the commit) from which the release candidate package was produced is tagged following a semantic versioning strategy. This serves to identify what version is currently in production, and also serves as the baseline reference for the calculation of changes for the next release.
For a demonstration of the workflow outlined above, please see our video series showing the Git branching model in action. This four-part series includes an overview of the Git branching model for mainframe development, as well as a role-based walkthrough of the activities of an application developer, development lead, and release manager during the process of delivering changes with the next planned release.