Planning repository layouts and scopes
Because the traditionally large and monolithic nature of enterprise applications can slow down development both at the organizational level and the individual developer level, many enterprises take the migration to Git as an opportunity to examine how they can break their monolithic applications down into more agile functional Git repositories. The repository layout in the source code management (SCM) component of the continuous integration/continuous delivery (CI/CD) pipeline affects other pipeline components in several ways:
- Repository layout affects the developer experience, as it impacts the level of isolation for development activities - in other words, how much of your development can happen independently of code or components managed in other repositories.
- The scope of the build is typically defined by what is included inside a repository versus outside of it. For shared resources such as copybooks, other repositories might need to be pulled in.
- The scope of the package sent to the artifact repository will depend on the outputs produced by the build step.
Basic components in a Git SCM layout
At a high level, the Git SCM can be thought of in two components: the central Git provider, which is the source from which developers will be pulling code from and pushing code to when they do their development work, and the clone on the developer workstation.
Within the central Git provider, there can be multiple organizations:
- Each organization can have multiple repositories inside it.
- In turn, each repository can have multiple branches (or versions) of the code in the repository.
- Branches enable updates to be isolated within a branch until they are ready to be included in other branches.
This allows each developer to focus on their development task on a dedicated branch, only needing to worry about upstream and downstream impacts when they are ready to integrate those with their work.
By convention, there is one branch that contains the latest, greatest, and most up-to-date agreed state of the code - this is conventionally known
as
main. Other branches can exist that represent a past state of the code or new changes that are not yet ready to be included inmain.- Branching in Git is lightweight both in storage space and time - no replication of the entire set of files is required to make a new branch; rather, it is a copy-on-update scheme that only requires the storage of the differences in files.
On the developer's workstation, the developer will have however many repositories they have decided to clone down onto their local computer to work with. By default, the clone of the repo from the server is an entire copy of the repo which, for example, includes the same history of changes and all the same branches that exist on the server. When working on changes, the developer will switch their working tree to be the contents of a particular branch.
Working with Git
Git is a distributed version control system, so rather than the files all staying in the mainframe during development, developers will clone the repository they are interested in down to their local workstation. Your organization's administrator(s) can control who has what permissions, or which repositories each developer has access to.
Working with a distributed version control system like Git also means that when planning the SCM layout, one factor to consider is size. Generally, you want to avoid doing something like migrating the entire codebase of a large application into one repository.
Large repositories can be cumbersome for a variety of reasons (although there are organizations that successfully manage their large codebases in so-called monorepos). For example, without using more sophisticated Git commands and options, when developers need to clone the repo it will take longer.
Visualizing the SCM layout
Traditionally, mainframe applications are often seen as a monolith, but as mentioned previously, it is generally not preferable to have all of your codebase in one giant repository. To begin thinking about how to separate an application "monolith" into different repositories and designing your SCM layout, you can start to think about boundaries within your application, which are formed by things such as responsibilities and ownership.
To use an analogy, you can think of the application like a large capital city. On the surface, it might seem like this city is one big entity - a big monolith. However, upon closer inspection, the city is broken up into districts. And while each district has its own workings (for example, each district has its own school system), all of these districts are connected by a broader infrastructure in a controlled way. There might be public transport, such as a metro or buses, which run on predefined paths and schedules. We can think of this transport infrastructure like the data flowing between application boundaries within a larger system.
In a similar sense, the districts within the city could be likened to groupings of related files and programs, which can be formed into their own smaller applications (in a loose sense of the term) with data flowing between them.
The following diagram illustrates the point more literally. In this example, there are three applications, which we can again think of like the city districts:
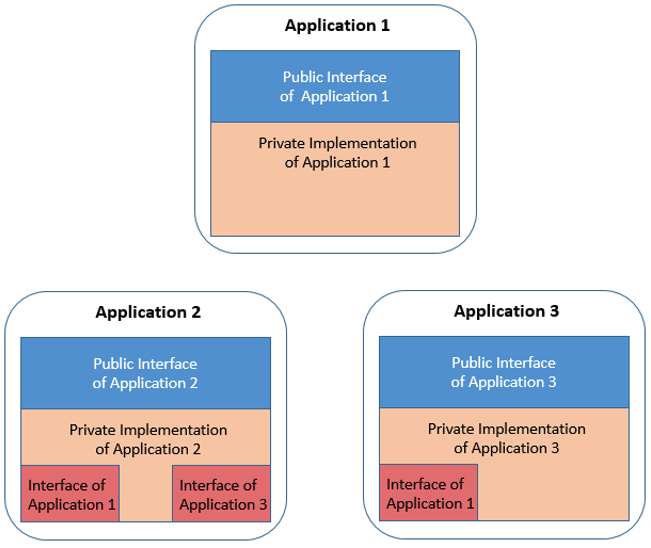
- Each application has its own inner workings in the private implementation (represented by the tan parts of the above diagram). In the city analogy, an example of this could be the school system each district has. In the mainframe context, an example of these inner workings could be the COBOL programs for that application.
- Additionally, each application needs to be able to communicate with other applications, which is accomplished via its public interface (shown in blue on the diagram). Using the city analogy again, the bus stop for each district could be considered as the district's "public interface". In the mainframe context, the public interface could be the copybooks defining data structures that are passed between programs.
- Because each application needs to know how to interact with the other applications, the application also includes usage of interfaces from the other applications (shown in red on the diagram). This can be likened to the application needing to know the bus stops and schedule from the other applications.
Typically, with this layout, each application would have its own Git repository with its own scope. Compared to putting the whole system in a single large Git repository, having these smaller repositories enables more agile development practices. Companies choose a central, web-based repository server where they can manage their repositories, and from which their developers will clone from (for example, Git providers such as GitHub, GitLab, Bitbucket, Azure Repos, and so on). The following section provides some guidance to consider when breaking down a monolithic codebase to achieve this kind of setup.
Guidelines for Git repository scope and structure
The guidelines in this section can be used when considering how to cluster your codebase into Git repositories in a way that makes sense and encourages a streamlined workflow for your organization. There are several factors to balance when scoping repositories, including the following:
- Access control
- Consider who (or which teams) need access to which files. Read/write, read-only, and restricted permissions need to be preserved, and this can be achieved by separating the files into different Git repositories and then managing access accordingly through your Git provider.
- Functional areas of the code
- In your current system, if different teams work on different components of your application, it might make sense to make boundaries based on that. An individual can be part of one or several teams.
- Decoupling
- Consider decoupling applications where it makes sense to do so. This allows different functional areas to have separate release cycles, which can help promote more agility in the overall organization.
- Interfaces
- When scoping for Git repository layouts, consider if or how changes performed by a team in one repository might impact other teams. In other words, within a team, if a developer on that team makes a breaking change to their repository (for example, to the application's private implementation), they can just work with their team to fix it. However, if a developer makes breaking changes impacting another team (for example, to the application's public interface), then resolving it can become more complicated.
- Size
- Consider the scope of changes for a typical change request (or pull request/merge request). For example, it is typically preferable to avoid change requests spanning across multiple repositories. Git providers usually have built-in review and approval mechanisms, so it is recommended to set up the repository layout in a way where these approval and review systems will make sense.
- Performance
- Git performance can be a consideration, but it should not be the primary driver to make decisions when organizing repository layouts.
These guidelines impact how application teams implement change, and must be carefully considered.
Recommended internal Git repository layout
A efficient internal layout - that is, the layout of folders within Git repositories - helps application developers easily navigate the codebase of an application. The internal layout also affects the CI/CD pipeline setup, particularly the build and packaging stages. Establishing standardized conventions helps provide a consistent developer experience and simplifies the pipeline implementation.
Generally, the internal repository layout should cater for various artifact types:
- z/OS mainframe artifacts such as COBOL, PL/I or Assembler programs and include files and JCL,
- Service definitions (in the wider sense of APIs) such as IBM z/OS Connect projects,
- Java source code implementing application components that can be run on the mainframe or a distributed runtime environment,
- Test artifacts:
- Standardized unit tests to test single modules,
- Manually triggered test drivers,
- Integration test configurations and scripts,
- Documentation and Readme,
- and everything that makes up the application configuration, such as Infrastructure as Code definitions, for instance CICS Resource builder definitions.
There is no common industry standard that existing open source projects follow. The internal repository layout is rather determined by how it has been established when the project started, how the development team performs change, as well as how the application architecture evolves over time.
The following list is not exhaustive but represents some of the important factors to consider when designing the internal Git repository layout:
- Navigation through the components and functional areas of the application
- Accommodation of changes in the application architecture
- Addition or change of programming languages
Typically, the first level of folders in the repository is driven by the various application components. The second level provides an architectural breakdown on the applications' code base. In the sample layout below, the docs folder allows the application team to store the documentation of the application under version control. The cbsa folder is named after the application and groups the artifacts by their functional areas, such as services (APIs), z/OS source code, tests, and Java:
docs/
cbsa/
|- application-conf/
|- api/
|- src/
|- test/
|- zos/
|- src/
|- cobol/
|- copybooks/
|- copybooks_gen/
|- interfaces/ (containing services to other mainframe applications)
|- test/ (e.g. Mainframe Unit tests)
|- test/ (e.g. Galasa tests)
|- java/
|- src/
|- com/acme/cbsa/packages
|- test/ (JUnit)
Each component folder contains src and test subfolders when applicable, to segregate the source code from the test artifacts. For the mainframe artifacts, the most common layout is to group by artifact type, such as the programming languages. Inside the zos/src folder, the structure indicates the different purposes of the application's artifacts. For instance, the folder interfaces contains include files owned by the application that can be referenced by other applications.
For the pipeline setup, the clone and checkout phase can be enhanced to retrieve external dependencies from other Git repositories. These steps can also be configured to only retrieve the shared include files that reside in the interfaces folder. Additionally, standardized dependency resolution rules can be applied in the build framework configuration.
Having a standardized layout across applications' repositories helps in using some features that Git providers usually provide. One of these features is the capability to implement a policy-based control of who needs to review and approve changes (known as CODEOWNERS or branch policies). Such a mechanism is easier to setup when based on the repository's structure.
To facilitate the navigation in the codebase, it is possible to further group source code by business functionality or by architectural composition of the application. In the following sample layout, the mainframe component, zos, is split into core account management functions (such as create, update, and delete), payment functions (to handle payments between accounts), and shared functions.
docs/
cbsa/
|- application-conf/
|- api/
|- src/
|- test/
|- zos/
|- src/
|- account.management /
|- cobol/
|- copybooks/
|- copybooks_gen/
|- interfaces/
|- account.payments /
|- cobol/
|- copybooks/
|- copybooks_gen/
|- interfaces/
|- account.shared.functions /
|- cobol/
|- copybooks/
|- copybooks_gen/
|- interfaces/
|- test/ (e.g. Mainframe Unit tests)
|- test/ (e.g. Galasa tests)
|- java/
|- src/
|- com/acme/cbsa/packages
|- test/ (JUnit)
Combining various application components into a single repository allows changes to be processed by a single pipeline with a streamlined build, packaging, and deployment process as part of a cohesive planning and release cadence. However, if application components are loosely coupled and/or even maintained by different teams, it often makes more sense to maintain them in separate repositories to allow for independent planning and release cycles. The following section provides guidance on how to manage dependencies between separate repositories.
Managing dependencies between applications in separate repositories
One of the challenges in designing the scope of applications and their repositories is about the dependency management, inside and across applications. For mainframe applications, this implies thinking about how the files are arranged. If a program and its subprogram are located in the same application's repository, then there is an 'internal' dependency between these artifacts, that does not impact other applications. If they are located in different applications' repositories, the dependency between these repositories can be qualified as 'external'.
Languages such as Java™ allow you to access other external applications by referencing their application programming interfaces (APIs). However, with COBOL (and other mainframe languages), the build process needs to pull in the external dependencies as source, via concatenation. Therefore, this is something you will want to consider when designing your SCM layout.
To help guide the SCM layout design process, we can approach the SCM design with a two-step process:
- Define which files make up each application: This is like defining the "districts" in your city, if we go back to the city analogy. You can consider looking at boundaries that have already naturally arisen based on ownership and responsibility around different parts of the codebase, in addition to the other guidelines for repository scope.
- You might already have an idea of which files make up each application based on a data dictionary.
- IBM® Application Discovery & Delivery Intelligence (ADDI) can assist in visualizing call graphs and clusters of dependencies in your codebase. These visualizations can be useful when you are analyzing the code to figure out how to organize it.
- Understand the internal versus external elements (such as copybooks) for each application: Here, the objective is to identify interfaces and shared items across application scopes - in other words, we want to determine which application is using which copybooks. In the city analogy, this is like identifying the bus stop names. Based on the repository layout, you can minimize how much changes in one repository will impact other repositories (and in turn, other teams and applications). Ideally, you will end up with files that have a lot of references within the same repository.
The result of the analysis in the steps above can be reflected within each application's repository. In the following example, you can see that the file structure is organized to indicate private versus public files and interfaces.

More details about managing dependencies can be found in the documentation for Defining dependency management.
Advanced topic: Options for efficient use of Git repositories
Migrating z/OS® applications from PDSs to Git takes planning and analysis. If you are new to Git, the earlier sections of this page provide an overview of general guidelines to keep in mind. The following advanced section explores finer details that can be considered when optimizing Git repositories for performance.
Modeling applications by size is a good first step in managing performance and capacity. The following table is an example that models applications by number of files (PDS members) times average total lines at 80 bytes each. Use it to compare with your application repos to determine what, if any, optimization may be needed.
The table also includes total size compressed by Git. Compression reduces the amount of disk space objects take up, which is important for efficient storage and transfer of Git repositories. Smaller objects mean less data to transfer, which can lead to faster clone, fetch, and push operations.
| App size | File count | Average lines per program at 80 bytes per line | Size (MB) | Size at 50% compression (MB) |
|---|---|---|---|---|
| small | 1,500 | 1,000 | 114 | 57 |
| med | 5,000 | 1,500 | 572 | 286 |
| large | 50,000 | 5,000 | 19,073 | 9,537 |
| Very Large | 140,000 | 5,000 | 53,406 | 26,703 |
Total size is half the story. Managing a Git repository's history also plays an important part in maintaining optimum performance.
The size of a Git repository's history can vary depending on the number of commits, the size of the files, and how often the repository is modified. In some cases, the history can become larger than the total size of all the files in the repository, especially if there are many commits that modify the same files over time.
Git employs various compression and storage optimization techniques to manage the size of the history, such as storing file differences instead of full copies for each commit and using delta compression for objects in the object database.
When comparing the performance of Git operations on repositories with large histories versus smaller histories, several metrics can be considered, including network transfer speed and CPU usage. Here's a general comparison:
-
Clone speed: Cloning a repository with a large history will typically take longer than cloning one with a smaller history. This is because Git needs to download and process more data for the larger history.
-
Fetch speed: Similarly, fetching updates from a remote repository can be slower for repositories with large histories, as Git needs to transfer and process more data.
-
Commit speed: Committing changes to a repository may be slower for repositories with large histories, especially if there are many files or changes that need to be processed.
-
Branching and merging: Creating branches and performing merges can be slower for repositories with large histories, as Git needs to analyze the history to determine the correct merge base.
-
CPU usage: Git operations on repositories with large histories may consume more CPU resources than those on repositories with smaller histories. This is because Git needs to process more data and perform more calculations for the larger history.
-
Memory usage: Git's memory usage can also be higher for repositories with large histories, especially during operations that require loading and processing a significant portion of the history.
-
Disk I/O: Operations on repositories with large histories may result in more disk I/O compared to operations on repositories with smaller histories, due to the larger amount of data that needs to be read from and written to disk.
Overall, repositories with large histories can require more time and resources to perform Git operations compared to repositories with smaller histories. However, the exact impact on performance will depend on factors such as the size of the history, the number of files, the nature of the changes, and the capabilities of the system running Git.
Strategies to manage large Git repositories with extensive histories
Managing large Git repositories with extensive histories can be challenging, but there are several strategies you can use to make the process more manageable:
-
Split repositories: If parts of your repository are independent or have different access requirements, consider splitting them into separate repositories. This can make each repository smaller and more manageable.
-
Baseline versus merge: Consider the trade-offs between maintaining a baseline branch (such as
masterormain) with a linear history versus using feature branches and merging them back into the main branch. A linear history can make it easier to track changes and understand the evolution of the codebase, but it may require more frequent rebasing and rewriting of history. On the other hand, using feature branches and merging them back into the main branch can make it easier to work on multiple features simultaneously and collaborate with other team members.tipTo learn about recommended Git branching strategies for mainframe applications, check out our Git branching model for mainframe development.
-
Code review practices: Establish code review practices and guidelines to ensure that changes to the repository are reviewed and approved by team members before being merged into the main branch. Maintaining code quality in this way can help teams avoid regressions in the codebase, as well as the extra time and commit history that might come with fixing regressions later in the development cycle.
-
Regular maintenance: Regularly review and clean up the repository, removing any unnecessary files and branches that are no longer needed.
-
Squash commits: Squashing commits can also help reduce the size of the repository, as each commit contains metadata and changesets that take up space. By squashing commits when merging into the long-living protected branch, you maintain relevant commits in the Git history while avoiding the potential noise of intermediate commits, which can make operations such as cloning, fetching, and browsing the history faster and more efficient. Git provider interfaces typically have an option to facilitate squashing commits when merging a pull request.
By incorporating these additional strategies into your Git workflow, you can further improve the management of large repositories and enhance collaboration within your team.