Code Generation#
PythonGenerator is an entry point that converts existing flows to Python SDK code.
Code Generation for Streaming#
For streaming flows, you can use the
PythonGenerator class to automate the transformation.
Prerequisites#
To properly generate a script, a few preparatory steps are required:
Create an instance of a correctly configured and authenticated
IAMAuthenticatorclass.Make sure your IBM Cloud API key is exported as an environment variable named
IBM_CLOUD_API_KEY. This key will be used by the generated script during execution.
Example usage#
The example below demonstrates how to regenerate Python SDK code from
StreamsetsFlow
class fetched directly from a project.
>>> import os
>>> from ibm_watsonx_data_integration.platform import Platform
>>> from ibm_watsonx_data_integration.common.auth import IAMAuthenticator
>>> from ibm_watsonx_data_integration.codegen import PythonGenerator
>>>
>>> auth = IAMAuthenticator(api_key=os.getenv('IBM_CLOUD_API_KEY'))
>>> platform = Platform(auth, base_api_url='https://api.ca-tor.dai.cloud.ibm.com')
>>> project = platform.projects.get(name='Test Project')
>>> flow = project.flows.get(name='My first flow')
>>>
>>> generator = PythonGenerator(
... source=flow,
... destination='/tmp/output.py',
... auth=auth, # pragma: allowlist secret
... base_api_url='https://api.ca-tor.dai.cloud.ibm.com'
... )
>>> generator.save()
PosixPath('/tmp/output.py')
Code Generation for Batch#
For batch flows, use the
PythonGenerator
class to automatically converts assets from zip or json format to python code.
Configuration#
To use the PythonGenerator, create an instance of the generator and set the desired configuration settings.
mode: Generate one file per flow (
'flow_per_file'by default) or combine into a single file ('single_file').create_job: Add code to create a job for each flow (True by default).
run_job: Add code to run the auto-created jobs. Only checked if
create_jobis True, and defaults to True.overwrite: Allow overwriting the output directory (False by default).
use_flow_name: Use original flow names instead of autogenerated ones (True by default).
api_key: Provide your API key or update the placeholder later (default is a placeholder).
project_id: Provide your project ID or update the placeholder later (default is a placeholder).
>>> from ibm_watsonx_data_integration import *
>>> from ibm_watsonx_data_integration.services.datastage import *
>>>
>>> # Declare a generator to use
>>> generator = PythonGenerator()
>>>
>>> # Configure settings
>>> generator.configuration.mode = 'flow_per_file'
>>> generator.configuration.create_job = True
>>> generator.configuration.run_job = True
>>> generator.configuration.api_key = 'MY_API_KEY'
>>> generator.configuration.project_id = 'MY_PROJECT_ID'
Preparing Inputs#
The input can either be a flow JSON or a zip file containing one or more flows and their dependent assets. Both of these formats can be acquired in numerous ways, but one method is to download it directly from the flow editor.
This is a sample project containing one batch flow and one connection used in the flow.

The flow reads data from a COS datasource, sorts it, then outputs a preview of the data.
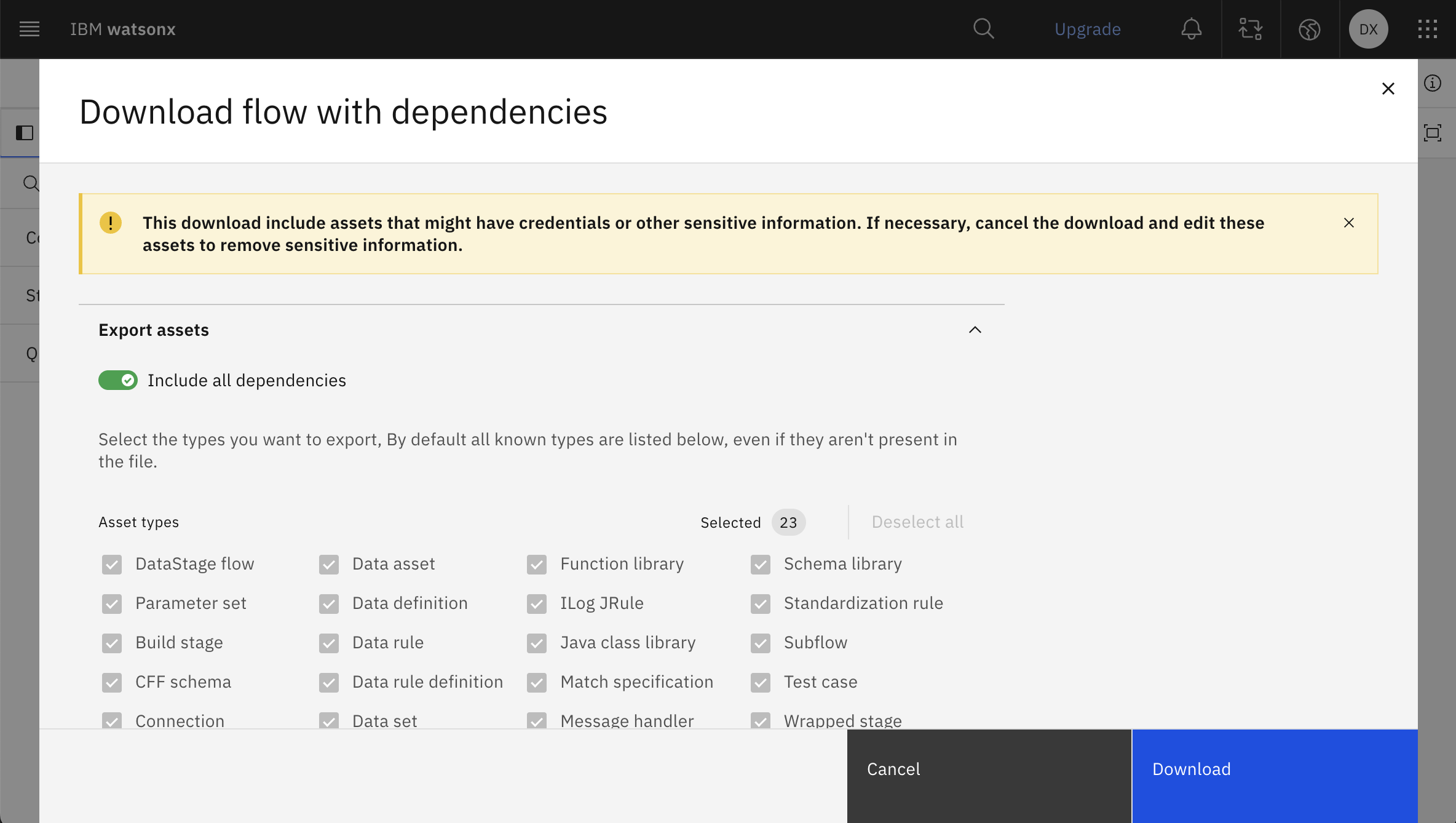
From this page, you can download the flow and its dependencies as a zip file.
This is the expected structure of the downloaded zip file:
downloaded_folder/
├── connections/
│ └── sample_connection.json
└── data_intg_flow/
│ └── sample_batch_flow.json
└── ...etc
Running the Generator#
Run the PythonGenerator using the PythonGenerator.generate(input_path, output_path) method
input_path: input_path to the JSON or zip file
output_path (optional): the file or directory where the code will be written (if no output_path is specified, the code will not be written)
returns a dictionary that maps file names to generated code strings
>>> # Generate multiple flows from zip and write to output directory
>>> generator.generate(input_path='downloaded_folder.zip', output_path='path/to/output')
>>> # Generate one flow from JSON and write to output directory
>>> generator.generate(input_path='downloaded_folder/data_intg_flow/sample_batch_flow.json', output_path='path/to/output.py')
>>> # Generate from zip without saving files
>>> generated_code = generator.generate(input_path='downloaded_folder.zip')
Note
Zip format is preferred since it contains dependencies and therefore can be generated more completely.
Running Generated Code#
Before running the generated code, three types of placeholders may need to be replaced.
Replace the api_key and project_id placeholders if you did not set them on the generator object:
api_key = '<TODO: insert your api_key>'
project = platform.projects.get(guid='<TODO: insert your project_id>')
Sensitive or encrypted connection credentials will also be generated as placeholders:
vertica = project.create_connection(
name='sample_vertica_conn',
datasource_type=platform.datasources.get(name='vertica'),
properties={
'database': 'abcdef',
'password': '<TODO: insert your password>',
'username': '<TODO: insert your username>',
},
)