IBM Data Science - Best Practices
Introduction

"Machine Learning" by Randall Munroe is licensed under CC BY-NC 2.5.
The goal of this document is to enable you as a data scientist to develop a data science use case in a semi-professional setting to make it ready for production use. This means focusing on the versioning, scalability, monitoring and engineering of the solution.
Prerequisites
Required Skills
- Python programming - Intermediate Level
- Data Science - Intermediate Level
- Shell, Terminal or CMD (command-line) - Beginner Level
- Git - Beginner Level
Tools
- Python 3 - Python 3.10
- IDE (Integrated Development Environment) - Our recommendations: Visual Studio Code or PyCharm Community Edition
Q: Can I use Jupyter Notebooks as my IDE? A: No, since this is not an IDE. Also we feel that it tends to encourage bad coding practice, especially with beginners. For further details: I don’t like Notebooks - Joel Grus (YouTube)
Q: Can I use a plain text editor? A: Yes, if you feel that this is the best for you, then go for it. Just make sure that it is a plain text editor and not a rich-text editor.
Q: Can I use Anaconda? A: No, Anaconda Free Version is only permitted for ‘individual hobbyists, academics, non-profits, and small businesses’ (more details); You require commercial licensing to use Anaconda in a large enterprise.
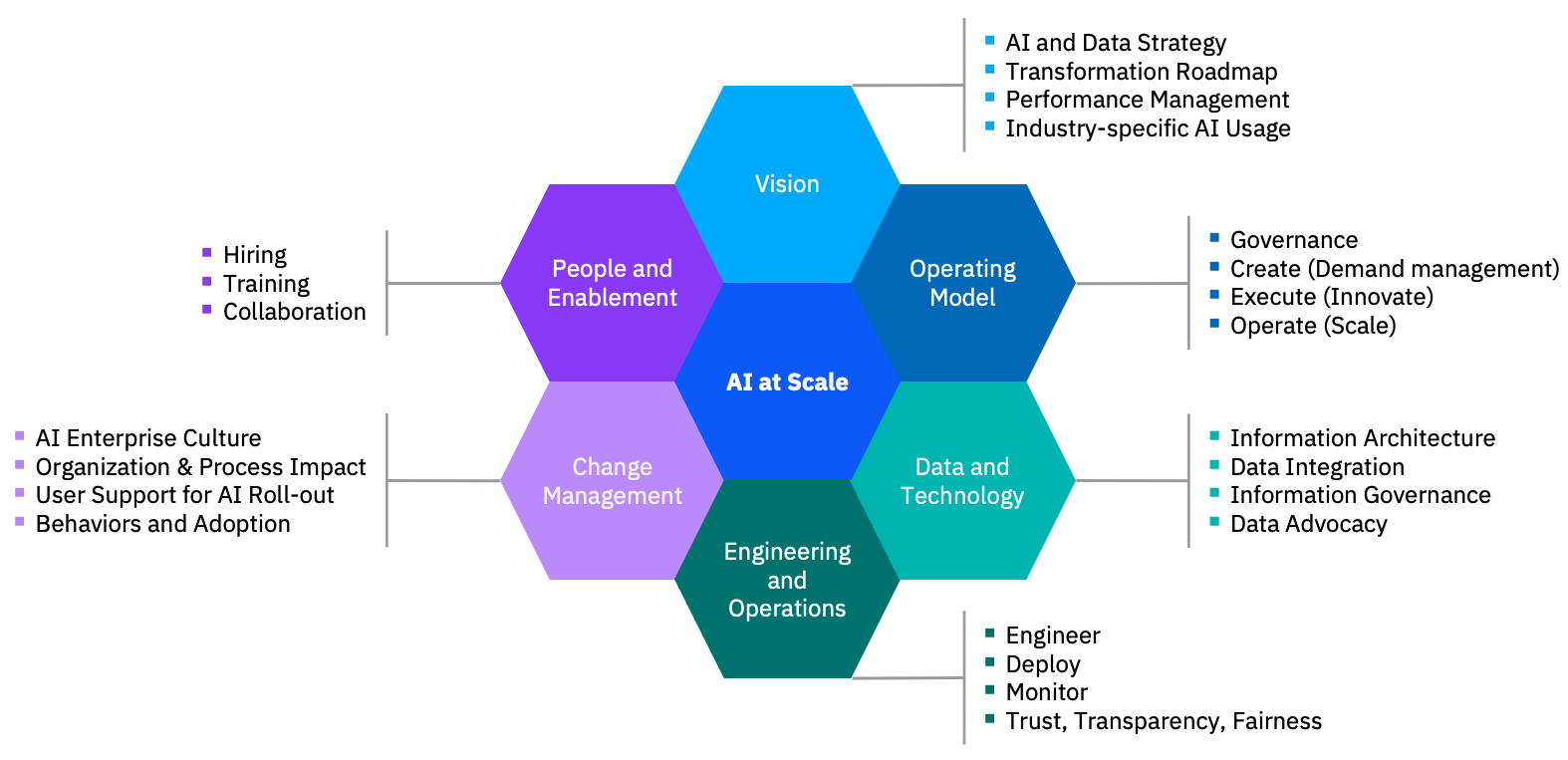
‘IBM Consulting for AI at Scale’ Offering
© IBM
‘IBM Consulting for AI at Scale’ is an IBM Consulting offering, which aims at scaling current AI engagements and applications towards an enterprise setup. It consists of multiple pillars, which are building up the overall offering:
- Vision: Addresses the AI and data strategy of a company and a potential transformation roadmap to make AI a key component of the company’s offering.
- Operating Model: When the journey and the plan is fixed, it is essential to define the how to execute and operate
- Data and Technology: In order to scale AI applications and environments, it is also key to incorporate a strong management and eco system for the existing data.
- Engineering and Operations: This addresses the questions of engineering, deploying and monitoring the AI solution. It is the most technical part of the offering and is the focus of this playbook.
- Change Management: The process to transform and change existing AI structures is addressed in this pillar.
- People and Enablement: To achieve maturity and scalability in AI it is essential to also cover the right skill set, roles and team setup in the AI organization.
The Role of Machine Learning in a Real World AI System
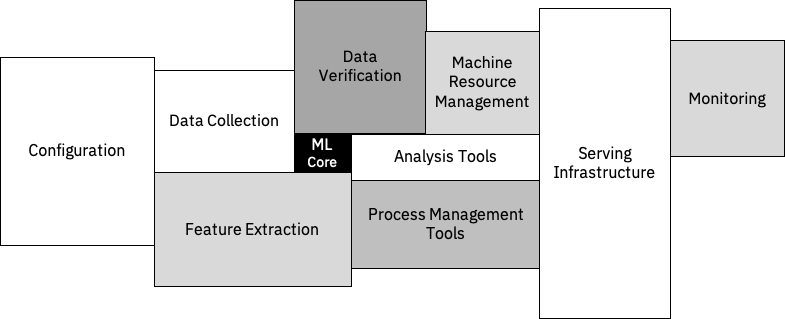
As outlined in the paper “Hidden Technical Debt in Machine Learning Systems” AI systems can become very quickly very complex. Machine Learning itself is just a tiny portion of the overall AI system. Understanding the surrounding factors is the first step is managing the complexity and keeping the technical debt of such systems at bay. The aim of these Data Science Best Practices is to guide and help understand these factors.
Need Help
Reach us at on Slack #datascience-best-practices (IBM Internal)