IBM Data Science - Best Practices
Versioning
When it comes to machine learning applications, the central artifact is usually a compiled model, which can be very large, and which has no notion of anything resembling a service architecture, dependencies, or anything else. It is essentially a ball of logic with inputs and outputs. Encoded within this artifact are several assumptions: it inherits the shape, support, and type of the dataset that trains it; it inherits the distribution function of the dataset that trains it ; and it often relies on the code or the frameworks that created it.
In other words, a machine learning system is Code + Data + Model. And each of these can and do change.

Source Code Versioning
To ensure all team members work on a consistent state of the source code and to protect against accidental deletions or changes Software Engineering developed source code management systems (short SCM). The most commonly used SCM is Git.
About Git
Git is a widely used Version Control System (VCS) that lets you keep track of all the modifications you make to your code. This means that if a new feature is causing any errors, you can easily roll back to a previous version.
GitHub provides cloud based Git repositories and a web based interface providing a basic set of controls and reporting tools. IBM uses the enterprise version of the GitHub tool suite called GitHub Enterprise
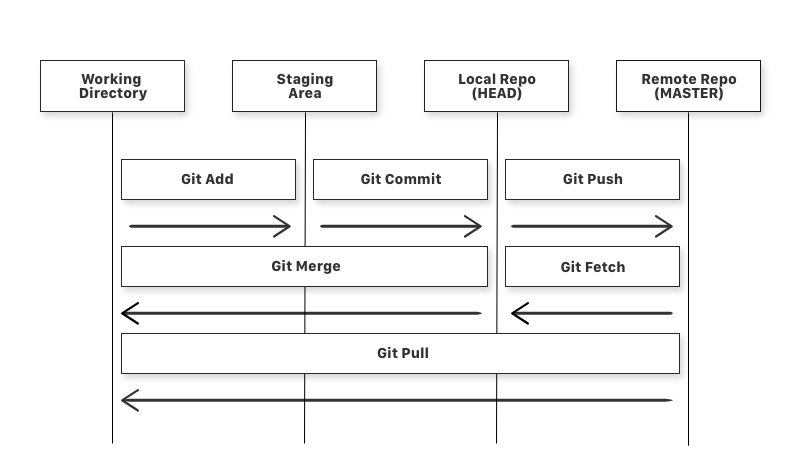
Basics of Git
- Git uses snapshots, not versions
When you make changes to a file and commit it, Git creates a snapshot of the complete filesystem at that point and stores that in its database. The snapshot also points to its predecessors or parents. Releases are usually identified with a metadata tag applied to an individual commit.
- Git operations are all local
Git doesn´t need a server, all operations are local. Only when communicating with a remote repository like GitHub a server connection is needed.
Terminology
Repository
The repository or repo is a folder that contains all project files and the history of the revisions made to each file. The remote repo lives on a server like GitHub, the local repo is a copy of a remote repo on your local machine. Fellow developers will not be able to see changes until they get pushed to the remote repo.
Cloning
git clone <Repo-URL>
Cloning means creating a copy of the remote repo on your local machine. Now you can make changes to the project on your local machine.
Commit
git commit -m “<commit message>”
When you commit a change, you save the changes you made to your files in the repo. To make those changes in the remote repo, you need to use the push command.
Add Files for the Commit
git add <files>
Add new files you want to include in the commit.
git add .
This command adds all new files in the next commit.
Push
git push origin <branch>
Push command allows you to transfer all the changes on your local repo to the remote repo.
Pull
git pull
The Pull command allows you to transfer all the changes from the remote repo to your local repo.
Initialization
git init
To create a new empty git repository use the git init command. It will create a repository at our present working directory. Remote repositories can be created on your github.ibm.com Account. Make sure to set the repository to private and only to public if its needed.
Status
git status
To get the current status of your repository.
Branching
You should use branches only if it is necessary and work on master so everyone has the same progress of the code. To learn more about the GitHub branching, visit GitHub Flow
git branch <branch-name>
Creates a new branch with the given name.
git checkout <branch-name>
Switches to the given existing branch.
Git Installation and Setup
View this tutorial to get started with GitHub. Getting started with GitHub
To connect with IBM GitHub Enterprise, you need to generate a SSH key and add it to the local ssh-agent. Be aware that if you enter a passphrase when generating the SSH Key, the passphrase has to be entered every time interacting with the remote repositories. After this, you have to add the new SSH key to your GitHub account.
Perform this GitHub Tutorial for setting up the SSH Key. Connecting to GitHub with SSH
Learn more about Git
.gitignore File
Git is a place where source code is stored. To keep it clean only the relevant part of your project should be added to git. This means that there are other file which you will need during development, but which should not be stored on git for various reasons. Here are a few reasons why some file should not be stored on git:
- your personal IDE configuration
- automatically generate files (e.g. build or distribution artifacts)
Pipfile.lockis an exception that must be added to git
- large or binary files
- for large data files use DVC (Data version Control)
- credential files or other confidential data
Caution: Credentials
Never add credentials or other confidential / secret data to git! > If you committed something confidential by accident, you must roll back / delete the complete commit, which is quiet complex. Just deleting it in the next commit will not do the trick!
Committing Code and Commit Messages
The general rule is to commit often and early. This usually causes small changes being committed, which makes resolving merge conflicts significantly easier or even prevents them from happening.
When code is committed git enforces a message to be added to the committed code change: There is no price for the shortest commit message! It is best practice to write a brief description of what was changed and why. It should be brief, but rather write a too long one than a too short one. Some project teams also include e.g. a issue or task ID to their commit messages to add more context to a particular code commit. Try to avoid using abbreviations, unless they are very common.
Feature Branching
Sometimes larger code base changes are necessary to be made. Instead of doing these changes in one big bang (a.k.a. one large commit), the recommended solution is using a feature branch:
- From the main branch (usually
master) a new branch is created - In small iterations (multiple commits) the feature is developed.
- Once the feature is complete, the feature branch is merged back to the main branch.
The advantage of this approach is that the feature development can work separately. The feature is not required to be implemented in one big bang. On the master you can continue developing other small changes or bug fixes.
Data Versioning
Data has a number of important properties, but the two we care most about are its shape and its distribution. The shape can be thought of as a schema, i.e. a structured way of describing the properties of the space the data lives in, and its values, i.e. the way it is distributed over that space. There is no reason to expect that our data will always look the same, even if its underlying shape stays the same. We must always be retraining our models.
One of the main ways in which we deal with Data Versioning is to link data and code using data version control tools. Popular data version control tools include DVC and other open source frameworks like Pachyderm and MLflow
Getting Started with DVC
Data Version Control or DVC is an open-source tool for data science and machine learning projects. Key features:
-
Simple command line Git-like experience. Does not require installing and maintaining any databases. Does not depend on any proprietary online services.
-
Management and versioning of datasets and machine learning models. Data is saved in S3, Google cloud, Azure, Alibaba cloud, SSH server, HDFS, or even local HDD RAID.
-
Makes projects reproducible and shareable; helping to answer questions about how a model was built.
-
Helps manage experiments with Git tags/branches and metrics tracking.
DVC aims to replace spreadsheet and document sharing tools (such as Excel or Google Docs) which are being used frequently as both knowledge repositories and team ledgers. DVC also replaces both ad-hoc scripts to track, move, and deploy different model versions; as well as ad-hoc data file suffixes and prefixes.
DVC usually runs along with Git. Git is used as usual to store and version code (including DVC meta-files). DVC helps to store data and model files seamlessly out of Git, while preserving almost the same user experience as if they were stored in Git itself. To store and share the data cache, DVC supports multiple remotes - any cloud (S3, Azure, Google Cloud, etc) or any on-premise network storage (via SSH, for example).
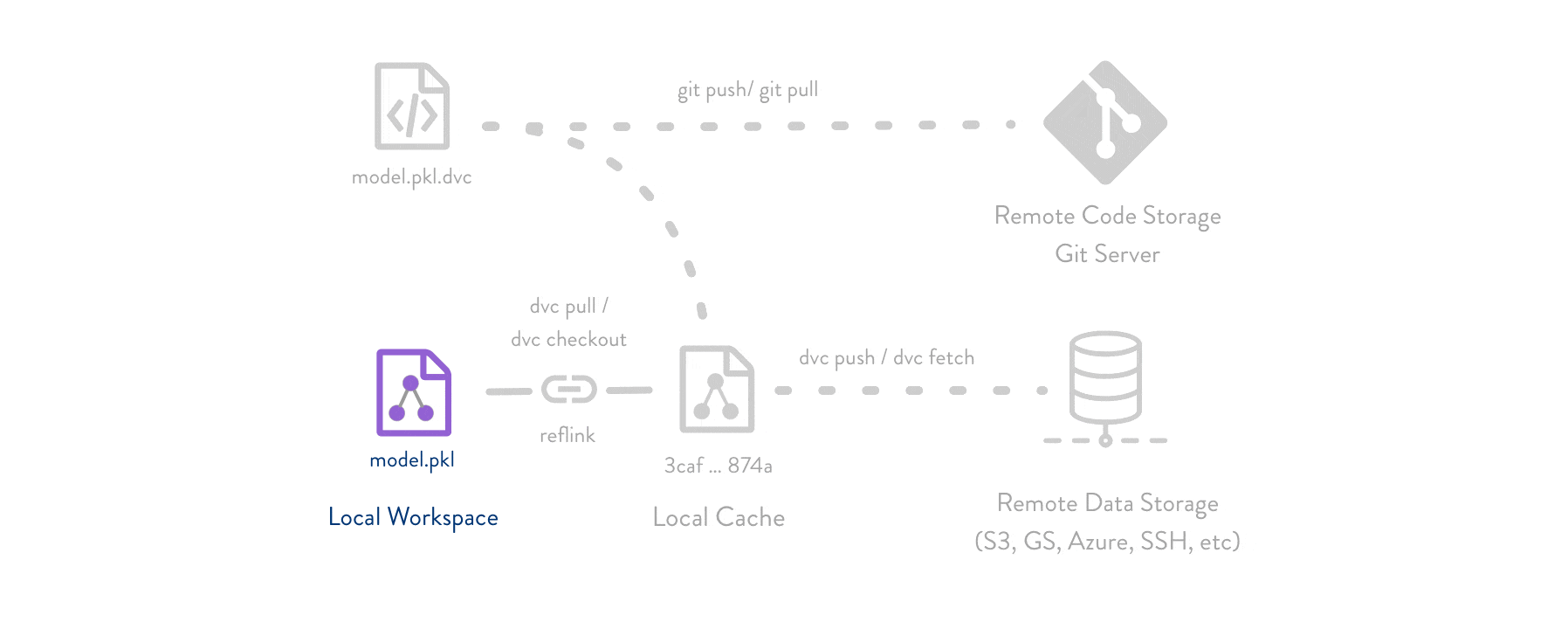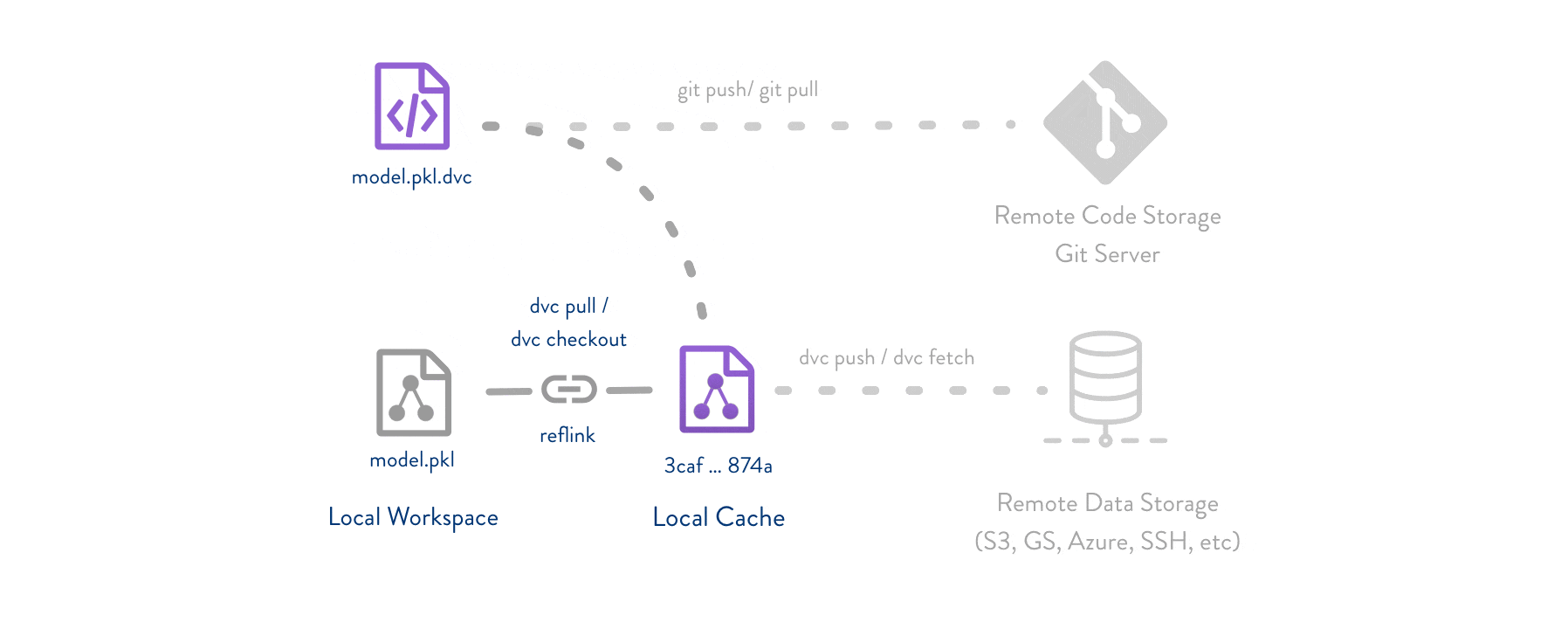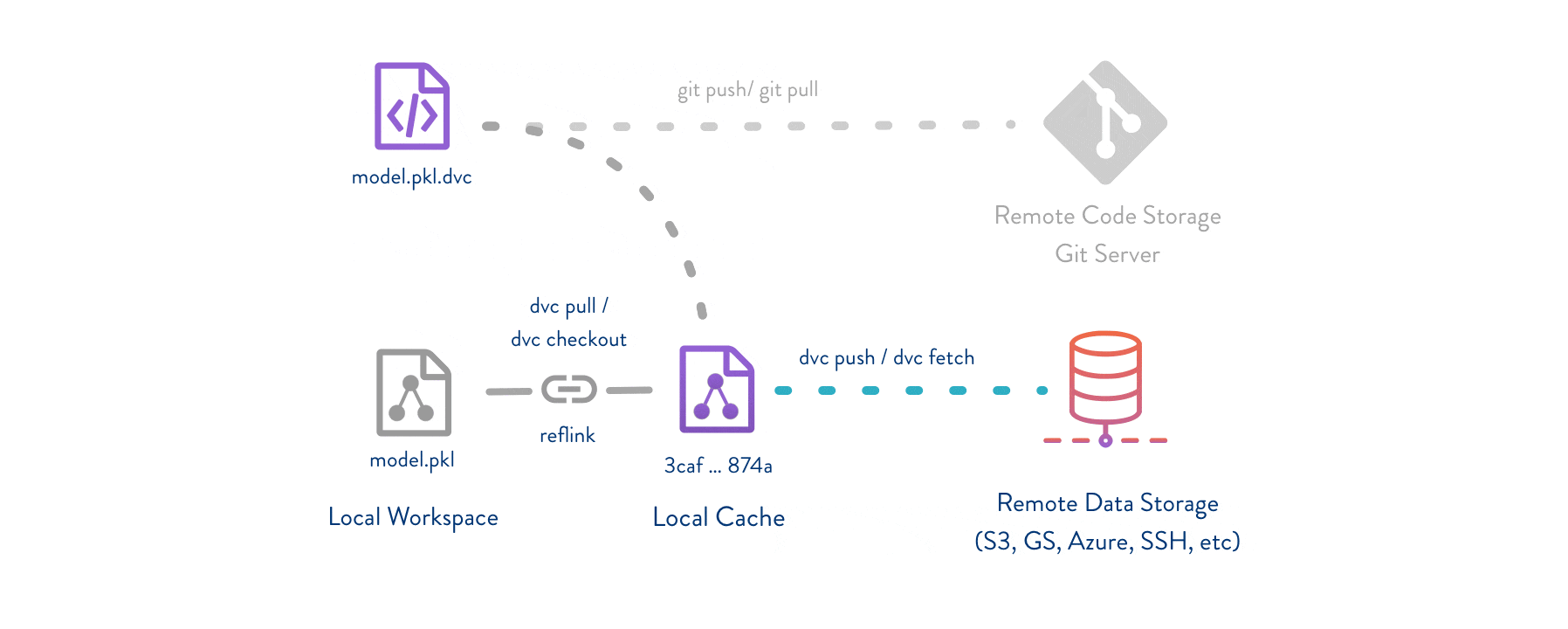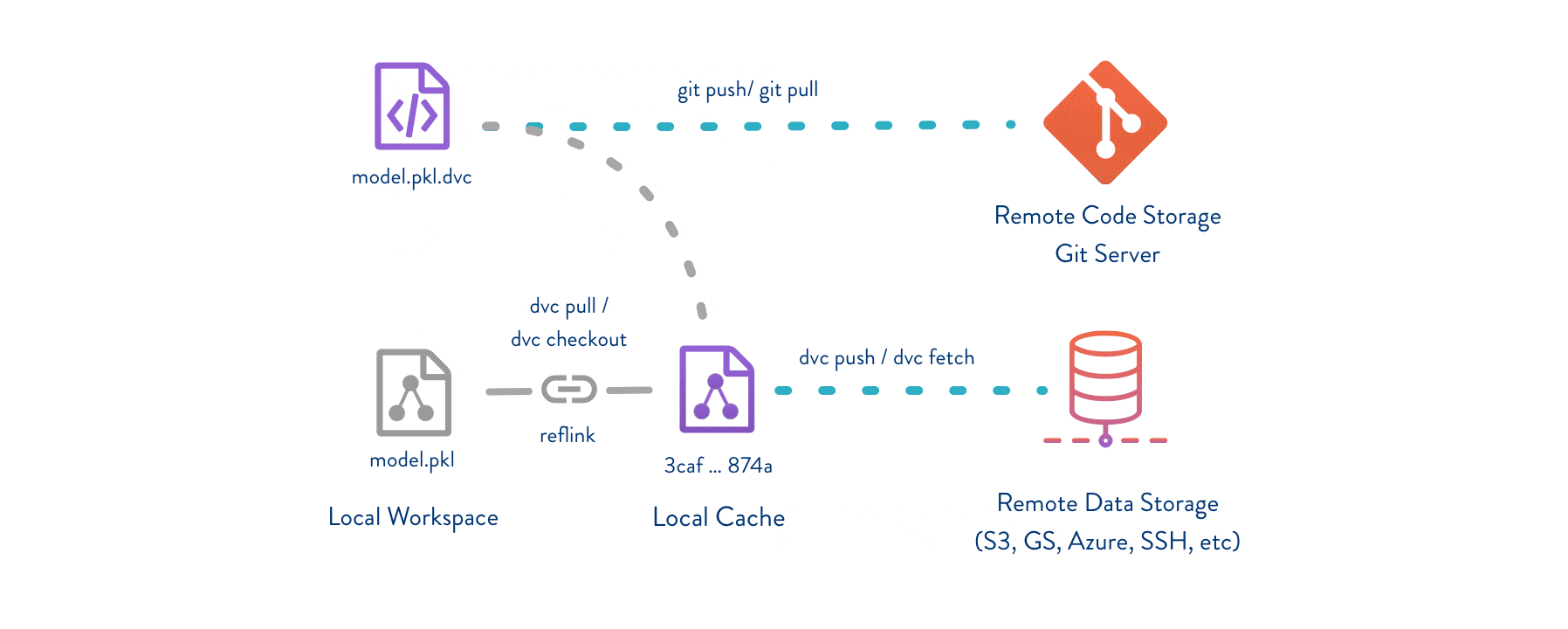
For a tutorial on how to implement DVC in your project and why it’s so helpful follow this tutorial
A list of all supported DVC backends can be found in the DVC documentation.
Model Versioning
Since models are in the wider sense build-artifact. Therefore they are not added to git. In general adding them to git is considered bad practice since they are binary files and can be very large.
Even though you can add your built models to DVC, it is considered bad practice, since it you would mix the input data with the output model, which violates the idea fo separation of concerns.
Model versioning is important because machine learning algorithms have dozens of configurable parameters, and whether you work alone or on a team, it is difficult to track which (hyper)parameters, code, and data went into each experiment to produce a model. One such tool that you can use for Model versioning is MLflow.
The built models are usually uploaded to binary repositories for versioning. This is often done by wrapping the model with some Python code and uploading it as Python library. This has the advantage that the model can directly be consumed e.g. by other Python developers. It is also possible to upload and version only the model file.
Examples
To find examples for these guidelines, go to the example repository: MLOps pipeline.
This example code is hosted and versioned in the IBM Enterprise Github. It is a git based repository, so it can be operated with the standard git CLI. One of the standard components is a .gitignore file:
*.iml
*.idea
*.cache
*__pycache__
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
...
The file specifies, which files are not pushed from the local working tree to the remote. The example above shows, that generally files with endings .iml, .idea, .cache etc. are not synced with git. Usually these are local user specifc files, that are not relevant for the team or public. Typically this also includes password files, which are obviously not meant for the public.
The respective data is versioned using DVC. For more detail refer to the examples section of Chapter 7 - Data Management (Engineer).
The models in this examples are pushed to Nexus (binary repository) after training. There they are versioned like a python package, which can be imported and installed via pip. An exemplary implementation for that can be found in the web-service repository. The Pipfile in that repository shows the import of the oncology model:
...
[packages]
flask-restplus = "==0.13.0"
oncology-model = {version="==0.1.175", index="nexus"}
...
The package is used as import in the src/oncology_service/serice.py file:
...
from oncology_model.datamodel import Tumor, Prediction
from oncology_model.classifier import Classifier
...
The packages includes the serialized model as well as the necessary code, which is required to get predictions from the model. The method to call a prediction is located in src/oncology_model/classifier.py (please refer to - Chapter 4 - Source Code (Engineer) for a description of the structure):
def predict(self, tumor: Tumor) -> Prediction:
result = self.model.predict(tumor.get_data())
if len(result) != 1:
raise ValueError(
f"the model returned and unknown prediction result:{result} ")
else:
return Prediction.from_classifier(value=result[0])
In this method, the user only needs to call the predict method with the respective tumor object as an input. As this code is included into the python package with the model, the user is sure, which interface to use to interact with the trained model.