IBM Data Science - Best Practices
Usage Recommendations
There is a wide variety of different architectural setups and flavours, the choice of tools is even larger. For a general recommendation on what to use for which use case it is important to consider a set of questions:
- What is the size of the engagement?
It is essential to assess to expected size of the engagement before planning architecture and tool landscape for your machine learning project. Typically the tendency should lean towards having more time to do the actual machine learning work than the management of the necessary infrastructure. Cloud providers take over most of the management on different levels. There are different levels of abstraction (level of abstraction increasing from left to right: Infrastructure as a Service (IaaS), Platform as a Service (PaaS), Software as a Service (SaaS).
For smaller scale engagements it is easier to opt for SaaS offerings. Most of these offerings are easy to work with and offer an API, which can be integrated in the solution. Popular examples for this are Azure ML, Watson Studio or AWS Sagemaker. These software solutions offer the option to specify the scale of the machine for training, your training code and the input data. The actual training, containerization and administration is taken over by the cloud provider. For larger scale engagements you might want to have the opportunity to manage and configure more yourself to meet the detailed requirements. Therefore it might be handy to use other offerings by the cloud provider like a managed Kubernetes service, a managed Spark environment or a managed database. But you still have to take care about containerization, data connections or versioning.
If a cloud provider is not an option you might want to setup clusters and environments yourself with full flexibility in configuration. This in return means that more effort needs to be spend to manage and administrate the infrastructure and landscape.
- What is the size of the training data?
If the use case is considered to have big data requirements (large training data set), it might be necessary to introduce Spark for data processing and learning. Spark is a cluster-based data processing platform for large scale use cases. Spark brings its own machine learning libraries, which implement the common machine learning algorithms for distributed computing. Therefore the workload can be scaled out and runtime decreased. If your use case requires smaller training data sets only, it is probably fine to work with a smaller setup being a Kubernetes Cluster or Docker host or any other machine type defined in your SaaS offering.
- What is the current available architecture and tool landscape?
It is always important to assess the existing architecture and tool landscape before you start working and developing new solutions. If there is an existing Github installation or a running Jenkins environment as well as a managed company-wide Kubernetes cluster, it is definitely not necessary to start from scratch and reinvent the wheel. It is not necessary to startup a standalone instance for the machine learning use case. Rather the existing solutions can be reused and maybe adapted slightly where needed.
- Is there a specific data privacy requirement?
Some industries have strong data privacy requirements like the public or defense sector. In these cases it is mostly not possible to run a workload on the cloud or move data to it. Therefore most of the workloads and use cases are required to be run locally in a data center. Before the final decision against cloud providers is taken, it is worthwhile assessing all encryption options. Maybe cryptographic methods like Homomorphic Encryption, Garbled Circuits, Secret Sharing and Secure Processors and ultimately the generation of synthetic data are an option.
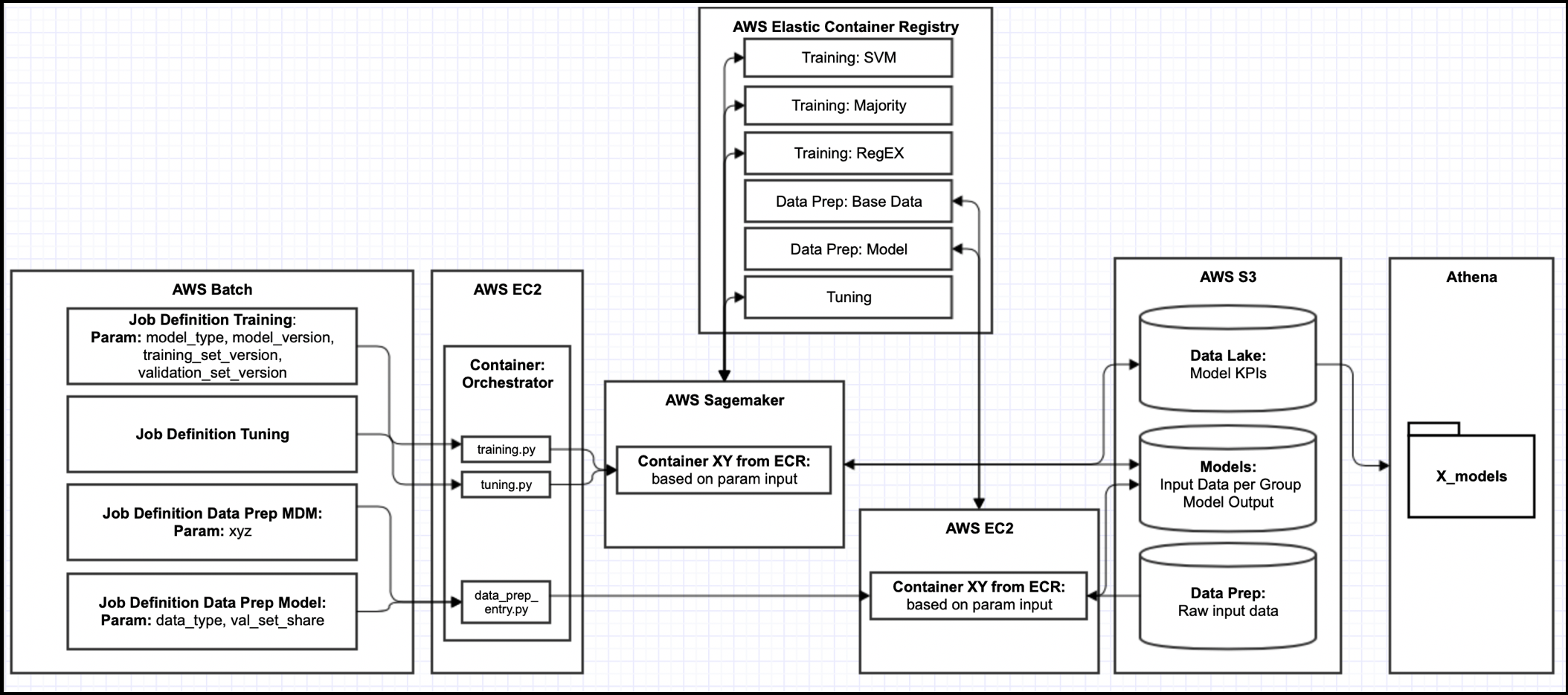
Exemplary solution on AWS
The overview below shows an exemplary pipeline implemented on AWS with the help of AWS Sagemaker and AWS ECS. The client offered the possibility to go to the cloud, the size of the training data was not too big, there were no data privacy requirements and it was a green-field approach.