IBM Data Science - Best Practices
Data Management
What Database should I use?
If you’ve used databases before you might be saying “I’ll just choose X, it’s the database I know and worked with” and that’s completely fine, if performance is not an important requirement for your system. Otherwise, choosing the wrong database might come as an obstacle when the project grows and it can be painful to fix. Even if you are working on a mature project, that already has a database in place, it’s important to know its limitations and identify when and whether you should add another type of database to your stack (do note that it is very common to combine several databases).
Relational vs. Non-Relational
Relational databases are the ‘old school’ databases, like MySQL. Non relational databases are NoSQL databases, such as MongoDB. Relational databases are stored similarly to an Excel spreadsheet, with a value corresponding to a row and a column. Non-relational databases do not store data in a tabular manner (how the data is actually stored varies by database). Because the data is stored differently, it affects the speed, scaling, and complexity of the database.
When choosing between a relational or non-relational database, the most important question to ask is: Do I care about the relations between the data elements?
Relational (SQL) Databases
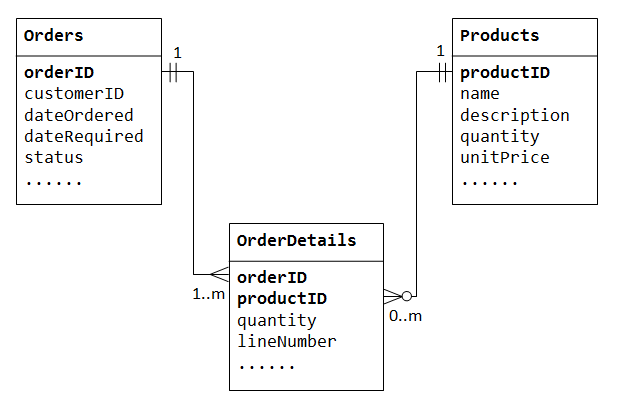
A Relational database consists of a collection of tables, that are connected. Each row in a table represents a record. The term relational refers to the emphasis on capturing the relationships amongst the data. Let ’s say you have a table of students information, and a table of the course grades (course, grade, student id), every grade row relates to a student record. See diagram below, where the value in the ‘Student ID’ column points to rows in the ‘Students’ table by the value of their ‘ID’ column.
All relational databases are queried with SQL-like languages, which are commonly used and inherently support join operations. They allow the indexing of columns for faster queries based on those columns. Because of its structured nature, the relational DB’s schema is decided before inserting data.
Common relational databases: MySQL, PostgreSQL, Oracle, MS SQL Server
Non-Relational (NoSQL) Databases
While in relational databases everything is structured to rows and columns, in NoSQL databases there is no common structured schema for all records. Most of the NoSQL databases contain JSON records, and different records can include different fields. There are four main types of Non-Relational databases:
- Document-oriented: The atomic unit of this DB is a document. Each document is e.g. a JSON, the schema can vary between different documents and contain different fields. Document databases allow indexing of some fields in the document to allow faster queries based on those fields (this forces all the documents to have the field).
- When should I use it? Data analysis — Since different records are not dependent on one another (logic and structure-wise) this DB supports parallel computations.
- Common document-based databases: MongoDB, CouchDB, DocumentDB.
- Columnar: A columnar database is optimized for fast retrieval of columns of data, typically in analytical applications. Column-oriented storage for database tables is an important factor in analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from disk.
- When should I use it? When you plan to do column based operations like aggregations which is a very common data science activity
- Common Columnar databases: Cassandra, Google BigQuery, DB2 BLU, Apache HBase
- Graph: Graph databases contain nodes that represent entities and edges that represent relationships between entities. They work by storing the relationships along with the data. The nodes are linked in the database which makes accessing the relationships as easy as accessing the data itself.
- When should I use it? When your data is a graph like, like knowledge graphs and social networks.
- Common graph databases: Neo4j, InfiniteGraph, JanusGraph
- Key-Value: The querying is only key-based — You ask for a key and get its value. Doesn’t support queries across different record values like ‘select all records where city == New York’ A useful feature in this DB is the TTL field (time to live), this field can be set differently for each record and state when it should be deleted from the DB.
- When should I use it? Mainly used for cache since it is very fast and doesn’t require complex querying, also the TTL feature comes very useful for caching. It can also be used for any other kind of data that requires fast querying and meets the key-value format.
- Common key-value databases: Redis, Memcached
OLAP vs OLTP
-
OLTP (On-line Transaction Processing) is involved in the operation of a particular system. OLTP is characterized by a large number of short on-line transactions (INSERT, UPDATE, DELETE). The main emphasis for OLTP systems is put on very fast query processing, maintaining data integrity in multi-access environments and effectiveness measured by number of transactions per second. In OLTP database there is detailed and current data, and schema used to store transactional databases is the entity model (usually 3NF). It involves Queries accessing individual record like Update your Email in Company database.
-
OLAP (On-line Analytical Processing) deals with Historical Data or Archival Data. OLAP is characterized by relatively low volume of transactions. Queries are often very complex and involve aggregations. For OLAP systems a response time is an effectiveness measure. OLAP applications are widely used in datascience. In OLAP database there is aggregated, historical data, stored in multi-dimensional schemas.
Object/Blob Storage
Object storage, also known as object-based storage, is a flat structure in which files are broken into pieces and spread out among hardware. In object storage, the data is broken into discrete units called objects and is kept in a single repository, instead of being kept as files in folders or as blocks on servers.
Object storage requires a simple HTTP application programming interface (API), which is used by most clients in all languages. Object storage is cost efficient: you only pay for what you use. It can scale easily, making it a great choice for public cloud storage. It’s a storage system well suited for static data, and its agility and flat nature means it can scale to extremely large quantities of data. The objects have enough information for an application to find the data quickly and are good at storing unstructured data.
There are drawbacks, to be sure. Objects can’t be modified—you have to write the object completely at once. Object storage also doesn’t work well with traditional databases, because writing objects is a slow process and writing an app to use an object storage API isn’t as simple as using file storage.
Common Object Storage providers: Amazon S3, IBM Cloud Object Storage, Azure Blob Storage, Google Cloud Storage
Data Acquisition
Data Acquisition describes the process and methods for obtaining data into the organization for usage in model training, development and production. Data Acquisition targets the form of data that is not yet captured or collected by the organization. It can be performed by various methods like surveys, research, marked data analysis, Data Scraping, etc.
Data Scraping
Data Scraping is a method of Data Acquisition to extract information from websites. The process involves the extraction of text, images and other media. Libraries for Data Scraping are URLLIB, BS4, LXML for HTML and XML Content, Selenium for dynamic webpages and for example Scrapy as a whole Scraping Framework. It should be verified if the websites contain copyrighted data that cannot be used for training and development.
Data Ingestion
Data Ingestion is the process of obtaining data from assorted sources to a storage system, where it can be accessed and analyzed. It targets data that is already existing in diverse formats like e.g. different datasets. Methods for Data Ingestion are Streaming in real-time or the batch processing of data. Streaming Platforms often use micro-batching as an alternative to Streaming in real-time, where a short interval of data is batched.
Data Streaming
Data Streaming describes the processing of mostly real-time data that comes from various sources. Streaming consists of two parts, a Streaming Platform and a Stream Processing Framework. The Streaming Platform is based on a Publisher and Subscriber Model whereas the Stream Processing Framework is a set of library which are supporting the streams over the platform. Products that provide Data Streaming functionality are open source options Apache Kafka, Apache Spark and Hadoop or vendor options like Azure Stream Analytics, Google Dataflow or AWS Kinesis.
Data Transformation
Data Transformation is the process of converting data that exists in one format or structure into another format. Its an alignment of data sets to each other or a certain schema. Data Transformation happens after Data Acquisition and Data Ingestion to further process the data. It it important that data is uniform and standardized, which is mostly not the case for data coming from other systems or sources.
Data Synchronization
Data must always be consistent throughout the data record. If data is modified in any way, changes must upgrade through every system in real-time to avoid mistakes, prevent privacy breaches, and ensure that the most up-to-date data is the only information available. Data synchronization ensures that all records are consistent, all the time.
There are a few types of data synchronization methods. Version control and file synchronization tools can make changes to more than one copy of a file at a time. The other two, distributed and mirror, have more specific uses.
- File Synchronization: Faster and more error-proof than a manual copy technique, this method is most used for home backups, external hard drives, or updating portable data via flash drive. File synchronization ensures that two or more locations share the same data, occurs automatically, and prevents duplication of identical files.
- Version Control: This technique aims to provide synchronizing solutions for files that can be altered by more than one user at the same time.
- Distributed File Systems: When multiple file versions must be synced at the same time on different devices, those devices must always be connected for the distributed file system to work. A few of these systems allow devices to disconnect for short periods of time, as long as data reconciliation is implemented before synchronization.
- Mirror Computing: Mirror computing is used to provide different sources with an exact copy of a data set. Especially useful for backup, mirror computing provides an exact copy to just one other location — source to target.
Data Privacy
Data privacy relates to how a piece of information—or data—should be handled based on its relative importance. We typically apply the concept of data privacy to critical personal information, also known as personally identifiable information (PII) and personal health information (PHI).
GDPR
One such data privacy framework that is important to keep in mind is GDPR. The mutually agreed General Data Protection Regulation (GDPR) came into force on May 25, 2018, and was designed to modernise laws that protect the personal information of individuals.
GDPR applies across the entirety of Europe but each individual country has the ability to make its own small changes. Both personal data and sensitive personal data are covered by GDPR. Personal data, a complex category of information, broadly means a piece of information that can be used to identify a person. This can be a name, address, IP address… you name it. Sensitive personal data encompasses genetic data, information about religious and political views, sexual orientation, and more.
Masking
Data masking, also known as data obfuscation, is a process enterprises use to hide data. Generally, real data is obscured by random characters or other datum. It covers classified data points from those who don’t have permission to view it.
Overall, the primary function of masking data is to protect sensitive, private information in situations where it might be visible to someone without clearance to the information.
Here are a few of the top reasons that enterprise businesses use data masking:
- To protect data from third-party vendors: The sharing of some data with third-party marketers, consultants and others is par for course, but certain information must be kept confidential.
- Operator error: Enterprises trust their insiders to make good decision, but data breaches are often a result of operator error and businesses can safeguard themselves with data masking.
- Not all operations require the use of entirely real, accurate data: There are many functions within an IT department that don’t need real data — for instance, some testing and application use.
There a few different types of data masking to be aware of as you consider next steps. Most experts would agree that data masking is static or dynamic, with one exception – on-the-fly data masking. Here’s a look at three main types of data masking:
- Static: Static data masking refers to the process in which important data is masked in the original database environment. The content is duplicated into a test environment, and can then be shared around third-party vendors or other necessary parties.
- Dynamic: In dynamic data masking, automation and rules allow IT departments to secure data in real-time. That means it never leaves the production database, and as such is less susceptible to threats. Data is never exposed to those who access the database because the contents are jumbled in real-time, making the contents inauthentic.
- On the fly: Similar to dynamic data masking, on-the-fly data masking occurs on demand. In this type of data masking, an Extract Transform Load (ETL) process occurs where data is masked within the memory of a given database application. This is particularly useful for agile companies focused on continuous delivery.
Overall, your selection of a data masking strategy must take into consideration the size of the organization, as well as the location (cloud v. on premise) and complexity of the data you wish to protect.
Example
To find examples for these guidelines, go to the example repository: MLOps pipeline.
In this example, the data is hosted on an object storage solution in the cloud. For this implementation AWS S3 is chosen. The interaction with AWS S3 is managed by DVC when pushing and pulling data to or from the repository. The data is initially copied to the data/ folder, where it is then pushed to AWS S3 using the DVC push command. Only a *.dvc file remains.
Refer to the folder data/, where you find the training data breast_cancer_data.csv.dvc. The suffix .dvc implies, that this file is not physically stored in the Github repository, but only the reference to a specific version is stored. When you open the file, you find the md5 hash of the specific file versioned with DVC here. The actual file is not stored in DVC either, but in this examples resides in AWS S3. This configuration can be found in the .dvc/config file. In the file you can find the S3 url to the location, where the actual training file is stored. This file is only retrieved for usage in the training cycle to fit the model. The version of the training file and the version of the code is linked with the *.dvc file in the data/ folder. Therefore this specific commit in git refers to a specific version of the data in DVC, which resides in AWS S3. DVC also has a specific .gitignore file located in the .dvc/ folder, it makes sure git ignores everything in the .dvc folder except the config file. The same applies to the .dockerignore file.
In the makefile during model training the data is fetched from DVC:
dvc:
poetry run dvc pull
...
train: clean dvc build.training
poetry run python -m oncology_training -o src/oncology_model/model/model.joblib -d data -t build/train
The respective data file associated with the version saved in the breast_cancer_data.csv.dvc file is pulled from AWS S3.