導入
Introduction¶
IBM® Watson™ Studio ラーニングパスでは、IBM Watson Studio を使用して顧客の解約を予測するさまざまな方法を紹介しています。AutoAI Experiment ツールを使用した半自動のアプローチから、SPSS Modeler Flows を使用した図式化されたアプローチ、Python 用 Jupyter notebooks を使用した完全にプログラムされたスタイルまで、さまざまです。
このラーニングパスに含まれるチュートリアルはすべて、CRISP-DM(Cross Industry Standard Process for Data Mining)やIBM Data Science Methodologyなどのデータサイエンス(およびデータマイニング)の手法の主要なステップに沿っています。チュートリアルでは、データの理解、データの準備、モデリング、評価、予測分析のための機械学習モデルの展開などのタスクに焦点を当てています。チュートリアルでは、Kaggleで提供されている顧客の解約に関するデータ・セットとノートブックをベースとして使用し、AutoAI、SPSS Modeler、およびIBM Watson Studioスイート・オブ・ツールで提供されているIBM Watson Machine Learningサービスを使用して、同じ問題を解決する別の方法を示しています。学習パスでは、データの理解をサポートするためのIBM Watson Studioのプロファイリング・ツールとダッシュボードの使用、および簡単なデータ準備と変換タスクを解決するためのRefineツールについて説明しています。
データサイエンス・メソドロジー¶
IBMは、個々のテクノロジー・コンポーネントをリファレンス・アーキテクチャーにマッピングするためのプロセス・モデルを含むlightweight IBM Cloud Garage Methodを定義しました。この方法には、要求工学やデザイン思考のタスクは含まれていません。プロジェクトのアーキテクチャを最初に定義するのは難しいため、この手法では、プロセスモデル中のアーキテクチャの変更をサポートしています。
各ステージは、方法論全体の中で重要な役割を果たしています。ある程度の抽象度で言えば、データマイニングのためのCRISP-DMメソッドで概説されているワークフローを改良したものと見ることができます。
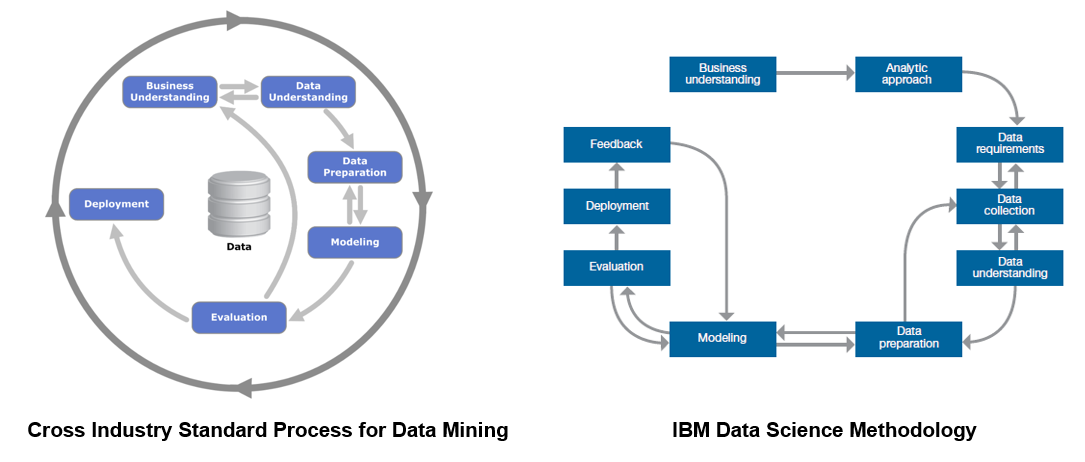
両方の方法論によると、すべてのプロジェクトは、問題と目的を定義する「ビジネスの理解」から始まります。これに続いて、IBMデータサイエンス・メソッドでは、データサイエンティストが問題解決のためのアプローチを定義する「分析的アプローチ」の段階があります。IBMデータサイエンス・メソッドでは、その後、データ要求、データ収集、_データ理解_と呼ばれる3つのフェーズが続きますが、CRISP-DMでは、1つの_データ理解_フェーズで表現されています。
データサイエンティストがデータを理解し、開始するのに十分なデータを手に入れた後は、_データ準備_フェーズに移ります。このフェーズは通常、非常に時間がかかります。データサイエンティストはこのフェーズに約80%の時間を費やし、データクレンジングやフィーチャーエンジニアリングなどの作業を行います。ここでは「データ整理」という言葉がよく使われます。データサイエンティストは、データのクレンジング中およびクレンジング後に、データの全体像を把握するための記述統計や、データの関係性や潜在的な構造を調べるためのクラスタリングなどの探索作業を行うのが一般的です。このプロセスは、データサイエンティストがデータセットに満足するまで、何度も繰り返し行われます。
モデルの学習段階では、機械学習を用いて予測モデルを構築します。モデルは学習された後、予測精度、感度、特異性などの統計的指標によって評価されます。モデルが十分であると判断された後、そのモデルはデプロイされ、未見のデータに対するスコアリングに使用されます。IBM Data Science Methodologyでは、モデルを使用した際のフィードバックを得るための「フィードバック」の段階が追加されており、このフィードバックがモデルの改良に使用されます。どちらの手法も、高度に反復的な性質を持っています。
このラーニングパスでは、データの理解から始まり、データの準備、モデルの構築、モデルの評価、そしてモデルの展開とテストに至るまでのフェーズに焦点を当てます。目的は、顧客の解約を予測するモデルを開発することです。このような解約の原因を分析してビジネスを改善することに関連する側面は、このラーニングパスの範囲外です。つまり、一連の特徴によって定義された顧客の観察結果をもとに、この特定の顧客が解約のリスクにさらされているかどうかを予測することができる、さまざまな種類の分類モデルを扱うことになります。
IBM Watson Studio¶
すべての作業に、IBM Watson Studioを使用しています。IBM Watson Studioは、データを共同で扱うことでビジネス上の問題を解決するための環境とツールを提供します。データの分析と可視化、データのクレンジングと整形、ストリーミングデータの取り込み、機械学習モデルの作成、トレーニング、デプロイなどに必要なツールを選択することができます。
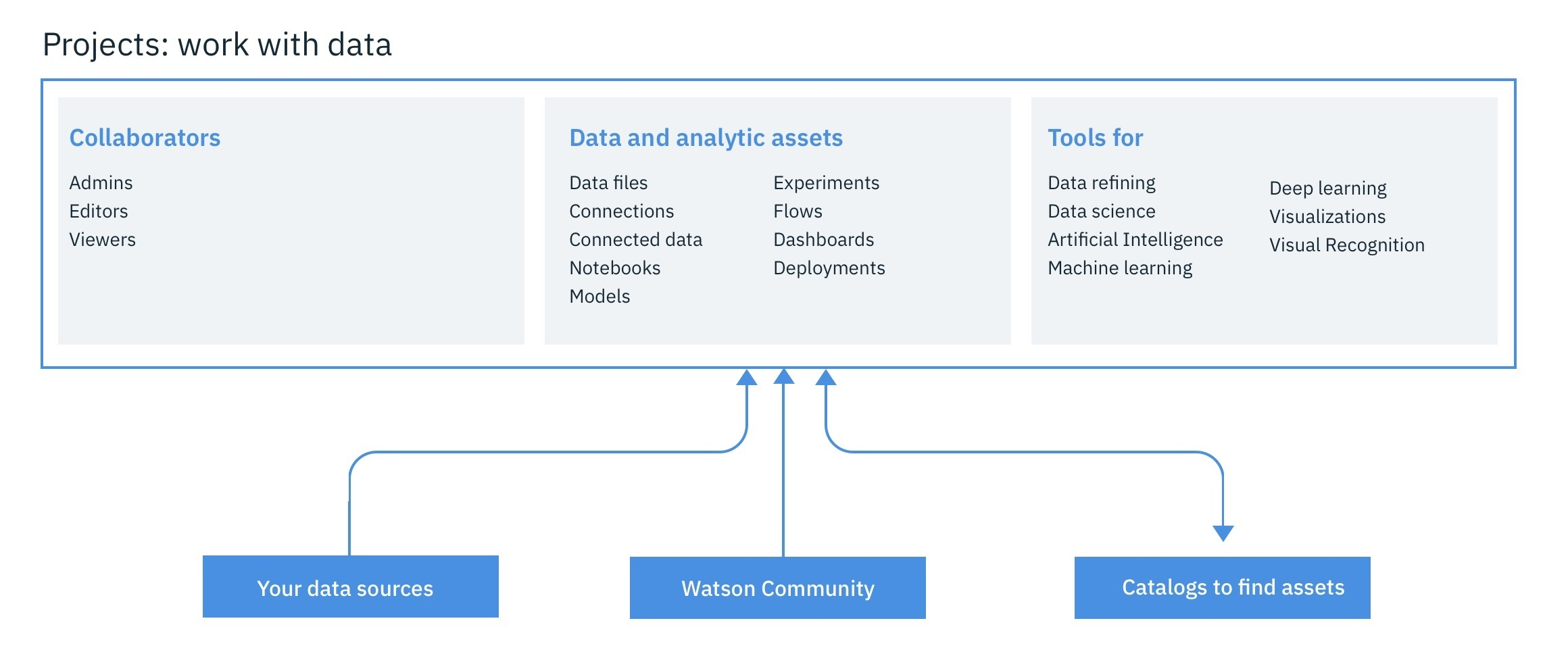
IBM Watson Studio を使用すると、以下のことができます。
-
プロジェクトを作成して、アナリティクスの目標を達成するためのリソース (データ接続、データ資産、共同作業者、ノートブックなど) を整理します。
-
接続から、クラウドまたはオンプレミスのデータソースにデータをアクセスします。
-
ファイルのアップロードをプロジェクトのオブジェクトストレージに行います。
-
データカタログを作成・維持し、データの発見、インデックス、共有を行う。
-
データのリファインを行い、データをクレンジングして整形し、分析の準備をする。
データサイエンスのタスクを実行するには、PythonやScala用のJupyter Notebooksを作成し、データを処理するコードを実行して、その結果をインラインで表示します。また、R用のRStudioを使用することもできます。
-
Streams Designer ツールを使用して、ストリームデータを取り込み、分析する。
-
機械学習や 深層学習 のモデルを作成、テスト、デプロイします。
-
データビジュアライゼーションのダッシュボードをコーディングなしで作成・共有する。
技術的には、IBM Watson Studioは、以下の図のように、様々なオープンソース技術とIBM製品をベースにしています。
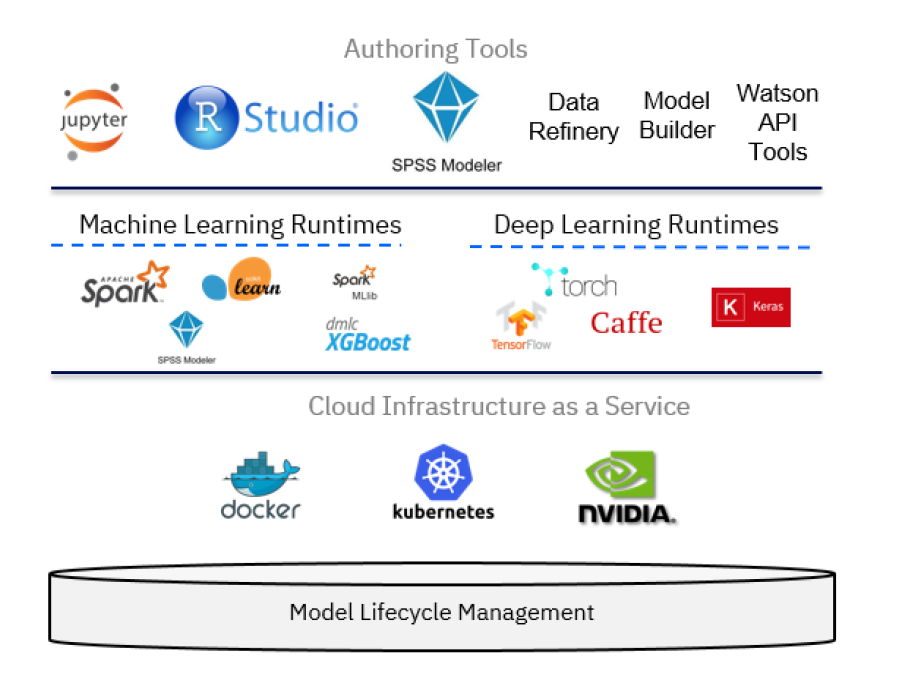
データサイエンスの文脈では、IBM Watson Studioは、データサイエンスの問題を解決するプロセスにおいて、開発者、データエンジニア、ビジネスアナリスト、データサイエンティストをサポートする、統合されたマルチロールコラボレーションプラットフォームと見なすことができます。開発者の役割としては、機械学習サービスを使用するアプリケーションを構築する上で、IBM Cloudプラットフォームの他のコンポーネントも関連してくるかもしれません。しかし、データサイエンティストは、以下のような様々なツールを使って機械学習モデルを構築することができます。
- AutoAI Model Builder。プログラミングのスキルを必要としないグラフィカルなツール
- SPSS Modeler Flows。図式化されたスタイルを採用
- RStudioとJupyter Notebooksの組み合わせ。プログラム的なスタイルの使用
これらの3つの主要コンポーネント以外にも、使用します。
- IBM Cloud Object Storageを使用して、モデルのトレーニングとテストに使用するデータセットを保存します。
- Data Refinery でデータセットを変換します。
- Cognos Dashboardsで可視化を行う。
その他の背景については、IBM Watson Studio で利用可能な 広範な「ハウツー」ビデオのリストをご覧ください。
IBM Watson Machine Learning サービス¶
IBM Watson Studio の重要なコンポーネントは、IBM Watson Machine Learning サービスと、機械学習モデルと対話するためにあらゆるプログラミング言語から呼び出すことができる REST API のセットです。IBM Watson Machine Learning サービスの焦点はデプロイメントですが、IBM SPSS Modeler または IBM Watson Studio を使用して、モデルやパイプラインをオーサリングして作業することができます。SPSS ModelerとIBM Watson StudioはどちらもSpark MLlibとPython scikit-learnを使用しており、機械学習、人工知能、統計学から取り入れた様々なモデリング手法を提供しています。
以下のリンクを使用して、Watson Machine Learning のより詳細な情報を入手してください。
まとめ¶
この記事では、IBM Data Science Methodology の背景情報、IBM Watson Studio が果たす役割、そしてこのラーニングパスで取り上げられる内容のプレビューを提供しました。
このラーニングパスの目的の 1 つは、IBM Watson Studio が、Python、Scala、または R 用の Jupyter Notebooks に加えて、同様のプロセスをより速く、プログラミングスキルなしで実現できる代替方法を提供していることを示すことです。要するに、これらのメカニズムは、データサイエンティストがフローを定義することで純粋にグラフィカルにモデルを作成できるSPSS Modeler Flowと、IBM Watson Studio内のIBM AutoAIグラフィカルツールであり、SPSSよりも一歩進んで、機械学習モデルの作成、評価、デプロイ、テストを半自動で行うことができます。同時に、この学習パスでは、IBM Watson Studioが、データのプロファイリング、可視化、変換のための機能を、やはりプログラミングを必要とせずにすぐに提供する様子を示しています。